diff --git a/DB.md b/DB.md
index 2eed8fa..7fd57da 100644
--- a/DB.md
+++ b/DB.md
@@ -241,13 +241,13 @@ SHOW PROCESSLIST:查看当前 MySQL 在进行的线程,可以实时地查看
| State | 显示使用当前连接的 sql 语句的状态,以查询为例,需要经过 copying to tmp table、sorting result、sending data等状态才可以完成 |
| Info | 显示执行的 sql 语句,是判断问题语句的一个重要依据 |
-**Sending data 状态**表示 MySQL 线程开始访问数据行并把结果返回给客户端,而不仅仅只是返回给客户端,是处于执行器过程中的任意阶段。由于在 Sending data 状态下,MySQL 线程需要做大量磁盘读取操作,所以是整个查询中耗时最长的状态。
+**Sending data 状态**表示 MySQL 线程开始访问数据行并把结果返回给客户端,而不仅仅只是返回给客户端,是处于执行器过程中的任意阶段。由于在 Sending data 状态下,MySQL 线程需要做大量磁盘读取操作,所以是整个查询中耗时最长的状态
-***
+***
@@ -264,7 +264,7 @@ SHOW PROCESSLIST:查看当前 MySQL 在进行的线程,可以实时地查看
1. 客户端发送一条查询给服务器
2. 服务器先会检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果(一般是 K-V 键值对),否则进入下一阶段
3. 分析器进行 SQL 分析,再由优化器生成对应的执行计划
-4. MySQL 根据优化器生成的执行计划,调用存储引擎的 API 来执行查询
+4. 执行器根据优化器生成的执行计划,调用存储引擎的 API 来执行查询
5. 将结果返回给客户端
大多数情况下不建议使用查询缓存,因为查询缓存往往弊大于利
@@ -280,7 +280,7 @@ SHOW PROCESSLIST:查看当前 MySQL 在进行的线程,可以实时地查看
##### 缓存配置
-1. 查看当前的 MySQL 数据库是否支持查询缓存:
+1. 查看当前 MySQL 数据库是否支持查询缓存:
```mysql
SHOW VARIABLES LIKE 'have_query_cache'; -- YES
@@ -399,7 +399,7 @@ SELECT * FROM t WHERE id = 1;
解析器:处理语法和解析查询,生成一课对应的解析树
* 先做**词法分析**,输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么代表什么。从输入的 select 这个关键字识别出来这是一个查询语句;把字符串 t 识别成 表名 t,把字符串 id 识别成列 id
-* 然后做**语法分析**,根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。如果你的语句不对,就会收到 `You have an error in your SQL syntax` 的错误提醒
+* 然后做**语法分析**,根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。如果语句不对,就会收到 `You have an error in your SQL syntax` 的错误提醒
预处理器:进一步检查解析树的合法性,比如数据表和数据列是否存在、别名是否有歧义等
@@ -434,7 +434,7 @@ MySQL 中保存着两种统计数据:
* innodb_table_stats 存储了表的统计数据,每一条记录对应着一个表的统计数据
* innodb_index_stats 存储了索引的统计数据,每一条记录对应着一个索引的一个统计项的数据
-MySQL 在真正执行语句之前,并不能精确地知道满足条件的记录有多少条,只能根据统计信息来估算记录,统计信息就是索引的区分度,一个索引上不同的值的个数(比如性别只能是男女,就是 2 ),称之为基数(cardinality),**基数越大说明区分度越好**
+MySQL 在真正执行语句之前,并不能精确地知道满足条件的记录有多少条,只能根据统计信息来估算记录,统计信息就是索引的区分度,一个索引上不同的值的个数(比如性别只能是男女,就是 2 ),称之为基数(cardinality),**基数越大说明区分度越好**
通过**采样统计**来获取基数,InnoDB 默认会选择 N 个数据页,统计这些页面上的不同值得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数
@@ -1650,7 +1650,7 @@ SELECT * FROM emp WHERE name REGEXP '[uvw]';-- 匹配包含 uvw 的name值
#### 约束介绍
-约束:对表中的数据进行限定,保证数据的正确性、有效性、完整性!
+约束:对表中的数据进行限定,保证数据的正确性、有效性、完整性
约束的分类:
@@ -1724,7 +1724,7 @@ SELECT * FROM emp WHERE name REGEXP '[uvw]';-- 匹配包含 uvw 的name值
#### 主键自增
-主键自增约束可以为空,并自动增长。删除某条数据不影响自增的下一个数值,依然按照前一个值自增。
+主键自增约束可以为空,并自动增长。删除某条数据不影响自增的下一个数值,依然按照前一个值自增
* 建表时添加主键自增约束
@@ -2122,19 +2122,11 @@ STRAIGHT_JOIN与 JOIN 类似,只不过左表始终在右表之前读取,只
salary DOUBLE -- 员工工资
);
-- 添加数据
- INSERT INTO employee VALUES (1001,'孙悟空',1005,9000.00),
- (1002,'猪八戒',1005,8000.00),
- (1003,'沙和尚',1005,8500.00),
- (1004,'小白龙',1005,7900.00),
- (1005,'唐僧',NULL,15000.00),
- (1006,'武松',1009,7600.00),
- (1007,'李逵',1009,7400.00),
- (1008,'林冲',1009,8100.00),
- (1009,'宋江',NULL,16000.00);
+ INSERT INTO employee VALUES (1001,'孙悟空',1005,9000.00),..,(1009,'宋江',NULL,16000.00);
```
-
+
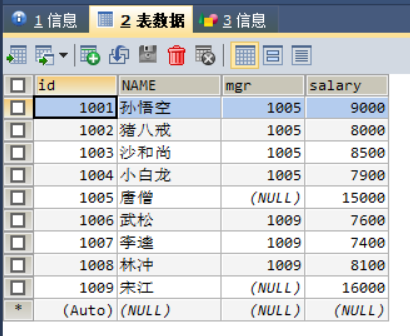
-
+
* 数据查询
```mysql
@@ -2334,7 +2326,7 @@ BNL 即 Block Nested-Loop Join 算法,由于要访问多次被驱动表,会
子查询物化会产生建立临时表的成本,但是将子查询转化为连接查询可以充分发挥优化器的作用,所以引入:半连接
-* t1 和 t2 表进行半连接,对于 t1 表中的某条记录,只需要关心在 s2 表中是否存在,而不需要关心有多少条记录与之匹配,最终结果集只保留 t1 的记录
+* t1 和 t2 表进行半连接,对于 t1 表中的某条记录,只需要关心在 t2 表中是否存在,而不需要关心有多少条记录与之匹配,最终结果集只保留 t1 的记录
* 半连接只是执行子查询的一种方式,MySQL 并没有提供面向用户的半连接语法
@@ -3585,7 +3577,7 @@ MySQL 支持的存储引擎:
MyISAM 存储引擎:
* 特点:不支持事务和外键,读取速度快,节约资源
-* 应用场景:查询和插入操作为主,只有很少更新和删除操作,并对事务的完整性、并发性要求不高
+* 应用场景:**适用于读多写少的场景**,对事务的完整性要求不高,比如一些数仓、离线数据、支付宝的年度总结之类的场景,业务进行只读操作,查询起来会更快
* 存储方式:
* 每个 MyISAM 在磁盘上存储成 3 个文件,其文件名都和表名相同,拓展名不同
* 表的定义保存在 .frm 文件,表数据保存在 .MYD (MYData) 文件中,索引保存在 .MYI (MYIndex) 文件中
@@ -3601,7 +3593,7 @@ InnoDB 存储引擎:(MySQL5.5 版本后默认的存储引擎)
MEMORY 存储引擎:
- 特点:每个 MEMORY 表实际对应一个磁盘文件 ,该文件中只存储表的结构,表数据保存在内存中,且默认**使用 HASH 索引**,所以数据默认就是无序的,但是在需要快速定位记录可以提供更快的访问,**服务一旦关闭,表中的数据就会丢失**,存储不安全
-- 应用场景:通常用于更新不太频繁的小表,用以快速得到访问结果,类似缓存
+- 应用场景:**缓存型存储引擎**,通常用于更新不太频繁的小表,用以快速得到访问结果
- 存储方式:表结构保存在 .frm 中
MERGE 存储引擎:
@@ -3650,14 +3642,10 @@ MERGE 存储引擎:
| 批量插入速度 | 高 | 低 | 高 |
| **外键** | **不支持** | **支持** | **不支持** |
-MyISAM 和 InnoDB 的区别?
-
-* 事务:InnoDB 支持事务,MyISAM 不支持事务
-* 外键:InnoDB 支持外键,MyISAM 不支持外键
-* 索引:InnoDB 是聚集(聚簇)索引,MyISAM 是非聚集(非聚簇)索引
+只读场景 MyISAM 比 InnoDB 更快:
-* 锁粒度:InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁
-* 存储结构:参考本节上半部分
+* 底层存储结构有差别,MyISAM 是非聚簇索引,叶子节点保存的是数据的具体地址,不用回表查询
+* InnoDB 每次查询需要维护 MVCC 版本状态,保证并发状态下的读写冲突问题
@@ -3720,7 +3708,7 @@ MyISAM 和 InnoDB 的区别?
#### 基本介绍
-MySQL 官方对索引的定义为:索引(index)是帮助 MySQL 高效获取数据的一种数据结构,**本质是排好序的快速查找数据结构。**在表数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式指向数据, 这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
+MySQL 官方对索引的定义为:索引(index)是帮助 MySQL 高效获取数据的一种数据结构,**本质是排好序的快速查找数据结构。**在表数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式指向数据, 这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引
**索引是在存储引擎层实现的**,所以并没有统一的索引标准,即不同存储引擎的索引的工作方式并不一样
@@ -3772,7 +3760,7 @@ MySQL 官方对索引的定义为:索引(index)是帮助 MySQL 高效获
| R-tree | 不支持 | 支持 | 不支持 |
| Full-text | 5.6 版本之后支持 | 支持 | 不支持 |
-联合索引图示:根据身高年龄建立的组合索引(height,age)
+联合索引图示:根据身高年龄建立的组合索引(height、age)
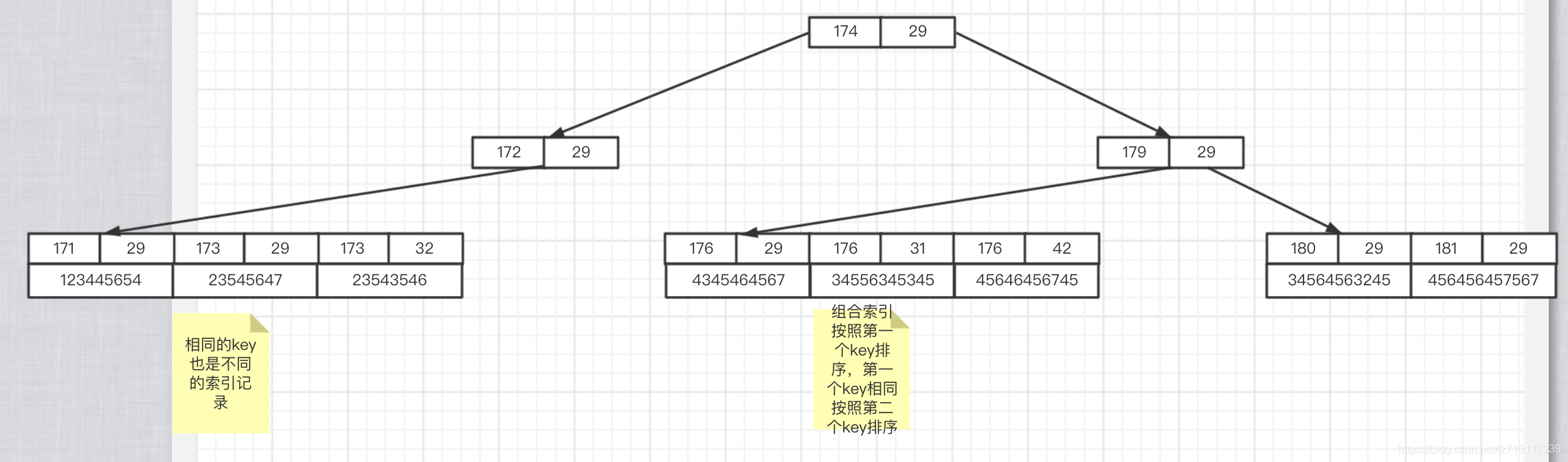
@@ -3999,6 +3987,8 @@ InnoDB 存储引擎中有页(Page)的概念,页是 MySQL 磁盘管理的
* InnoDB 引擎将若干个地址连接磁盘块,以此来达到页的大小 16KB
* 在查询数据时如果一个页中的每条数据都能有助于定位数据记录的位置,这将会减少磁盘 I/O 次数,提高查询效率
+超过 16KB 的一条记录,主键索引页只会存储部分数据和指向**溢出页**的指针,剩余数据都会分散存储在溢出页中
+
数据页物理结构,从上到下:
* File Header:上一页和下一页的指针、该页的类型(索引页、数据页、日志页等)、**校验和**、LSN(最近一次修改当前页面时的系统 lsn 值,事务持久性部分详解)等信息
@@ -4147,9 +4137,11 @@ B+ 树为了保持索引的有序性,在插入新值的时候需要做相应
一般选用数据小的字段做索引,字段长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小
-自增主键的插入数据模式,可以让主键索引尽量地保持递增顺序插入,不涉及到挪动其他记录,**避免了页分裂**
+自增主键的插入数据模式,可以让主键索引尽量地保持递增顺序插入,不涉及到挪动其他记录,**避免了页分裂**,页分裂的目的就是保证后一个数据页中的所有行主键值比前一个数据页中主键值大
+
+参考文章:https://developer.aliyun.com/article/919861
@@ -4256,7 +4248,7 @@ B+ 树为了保持索引的有序性,在插入新值的时候需要做相应
* 需要存储引擎将索引中的数据与条件进行判断(所以**条件列必须都在同一个索引中**),所以优化是基于存储引擎的,只有特定引擎可以使用,适用于 InnoDB 和 MyISAM
* 存储引擎没有调用跨存储引擎的能力,跨存储引擎的功能有存储过程、触发器、视图,所以调用这些功能的不可以进行索引下推优化
-* 对于 InnoDB 引擎只适用于二级索引,InnoDB 的聚簇索引会将整行数据读到缓冲区,不再需要去回表查询了,索引下推的目的减少回表的 IO 次数也就失去了意义
+* 对于 InnoDB 引擎只适用于二级索引,InnoDB 的聚簇索引会将整行数据读到缓冲区,不再需要去回表查询了
工作过程:用户表 user,(name, age) 是联合索引
@@ -4434,8 +4426,8 @@ INSERT INTO t VALUES('2017-4-1',1),('2018-4-1',1);-- 这两行记录分别落在
分区表的特点:
-* 一个是第一次访问的时候需要访问所有分区
-* 在 Server 层认为这是同一张表,因此所有分区共用同一个 MDL 锁
+* 第一次访问的时候需要访问所有分区
+* 在 Server 层认为这是同一张表,因此**所有分区共用同一个 MDL 锁**
* 在引擎层认为这是不同的表,因此 MDL 锁之后的执行过程,会根据分区表规则,只访问需要的分区
@@ -4448,14 +4440,14 @@ INSERT INTO t VALUES('2017-4-1',1),('2018-4-1',1);-- 这两行记录分别落在
分区表的优点:
-* 对业务透明,相对于用户分表来说,使用分区表的业务代码更简洁。
+* 对业务透明,相对于用户分表来说,使用分区表的业务代码更简洁
* 分区表可以很方便的清理历史数据。按照时间分区的分区表,就可以直接通过 `alter table t drop partition` 这个语法直接删除分区文件,从而删掉过期的历史数据,与使用 drop 语句删除数据相比,优势是速度快、对系统影响小
使用分区表,不建议创建太多的分区,注意事项:
* 分区并不是越细越好,单表或者单分区的数据一千万行,只要没有特别大的索引,对于现在的硬件能力来说都已经是小表
-* 分区不要提前预留太多,在使用之前预先创建即可。比如是按月分区,每年年底时再把下一年度的 12 个新分区创建上即可,并且对于没有数据的历史分区,要及时的 drop 掉。
+* 分区不要提前预留太多,在使用之前预先创建即可。比如是按月分区,每年年底时再把下一年度的 12 个新分区创建上即可,并且对于没有数据的历史分区,要及时的 drop 掉
@@ -4587,8 +4579,6 @@ select v from ht where k >= M order by t_modified desc limit 100;
#### 执行频率
-随着生产数据量的急剧增长,很多 SQL 语句逐渐显露出性能问题,对生产的影响也越来越大,此时有问题的 SQL 语句就成为整个系统性能的瓶颈,因此必须要进行优化
-
MySQL 客户端连接成功后,查询服务器状态信息:
```mysql
@@ -4720,12 +4710,10 @@ EXPLAIN SELECT * FROM table_1 WHERE id = 1;
MySQL **执行计划的局限**:
* 只是计划,不是执行 SQL 语句,可以随着底层优化器输入的更改而更改
-* EXPLAIN 不会告诉显示关于触发器、存储过程的信息对查询的影响情况
-* EXPLAIN 不考虑各种 Cache
+* EXPLAIN 不会告诉显示关于触发器、存储过程的信息对查询的影响情况, 不考虑各种 Cache
* EXPLAIN 不能显示 MySQL 在执行查询时的动态,因为执行计划在执行**查询之前生成**
-* EXPALIN 部分统计信息是估算的,并非精确值
* EXPALIN 只能解释 SELECT 操作,其他操作要重写为 SELECT 后查看执行计划
-* EXPLAIN PLAN 显示的是在解释语句时数据库将如何运行 SQL 语句,由于执行环境和 EXPLAIN PLAN 环境的不同,此计划可能与 SQL 语句**实际的执行计划不同**
+* EXPLAIN PLAN 显示的是在解释语句时数据库将如何运行 SQL 语句,由于执行环境和 EXPLAIN PLAN 环境的不同,此计划可能与 SQL 语句**实际的执行计划不同**,部分统计信息是估算的,并非精确值
SHOW WARINGS:在使用 EXPALIN 命令后执行该语句,可以查询与执行计划相关的拓展信息,展示出 Level、Code、Message 三个字段,当 Code 为 1003 时,Message 字段展示的信息类似于将查询语句重写后的信息,但是不是等价,不能执行复制过来运行
@@ -4865,7 +4853,7 @@ key_len:
* Using where:搜索的数据需要在 Server 层判断,无法使用索引下推
* Using join buffer:连接查询被驱动表无法利用索引,需要连接缓冲区来存储中间结果
* Using filesort:无法利用索引完成排序(优化方向),需要对数据使用外部排序算法,将取得的数据在内存或磁盘中进行排序
-* Using temporary:表示 MySQL 需要使用临时表来存储结果集,常见于排序、去重、分组等场景
+* Using temporary:表示 MySQL 需要使用临时表来存储结果集,常见于**排序、去重(UNION)、分组**等场景
* Select tables optimized away:说明仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
* No tables used:Query 语句中使用 from dual 或不含任何 from 子句
@@ -5049,7 +5037,7 @@ CREATE INDEX idx_seller_name_sta_addr ON tb_seller(name, status, address); # 联
* **字符串不加单引号**,造成索引失效:隐式类型转换,当字符串和数字比较时会**把字符串转化为数字**
- 在查询时,没有对字符串加单引号,查询优化器会调用 CAST 函数将 status 转换为 int 进行比较,造成索引失效
+ 没有对字符串加单引号,查询优化器会调用 CAST 函数将 status 转换为 int 进行比较,造成索引失效
```mysql
EXPLAIN SELECT * FROM tb_seller WHERE name='小米科技' AND status = 1;
@@ -5142,7 +5130,7 @@ CREATE INDEX idx_seller_name_sta_addr ON tb_seller(name, status, address); # 联
EXPLAIN SELECT * FROM tb_seller WHERE sellerId NOT IN ('alibaba','huawei');
```
-* [MySQL 实战 45 讲](https://time.geekbang.org/column/article/74687)该章节最后提出了一种场景,获取到数据以后 Server 层还会做判断
+* [MySQL 实战 45 讲](https://time.geekbang.org/column/article/74687)该章节最后提出了一种慢查询场景,获取到数据以后 Server 层还会做判断
@@ -5210,7 +5198,7 @@ SHOW GLOBAL STATUS LIKE 'Handler_read%';
##### 自增机制
-自增主键可以让主键索引尽量地保持递增顺序插入,避免了页分裂,因此索引更紧凑
+自增主键可以让主键索引尽量地保持在数据页中递增顺序插入,不自增需要寻找其他页插入,导致随机 IO 和页分裂的情况
表的结构定义存放在后缀名为.frm 的文件中,但是并不会保存自增值,不同的引擎对于自增值的保存策略不同:
@@ -5252,7 +5240,7 @@ MySQL 不同的自增 id 在达到上限后的表现不同:
```c++
do {
- new_id = thread_id_counter++;
+ new_id = thread_id_counter++;
} while (!thread_ids.insert_unique(new_id).second);
```
@@ -5396,7 +5384,7 @@ CREATE TABLE `emp` (
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4;
INSERT INTO `emp` (`id`, `name`, `age`, `salary`) VALUES('1','Tom','25','2300');-- ...
-CREATE INDEX idx_emp_age_salary ON emp(age,salary);
+CREATE INDEX idx_emp_age_salary ON emp(age, salary);
```
* 第一种是通过对返回数据进行排序,所有不通过索引直接返回结果的排序都叫 FileSort 排序,会在内存中重新排序
@@ -5433,7 +5421,7 @@ CREATE INDEX idx_emp_age_salary ON emp(age,salary);
内存临时表,MySQL 有两种 Filesort 排序算法:
-* rowid 排序:首先根据条件(回表)取出排序字段和信息,然后在**排序区 sort buffer(Server 层)**中排序,如果 sort buffer 不够,则在临时表 temporary table 中存储排序结果。完成排序后再根据行指针**回表读取记录**,该操作可能会导致大量随机 I/O 操作
+* rowid 排序:首先根据条件取出排序字段和信息,然后在**排序区 sort buffer(Server 层)**中排序,如果 sort buffer 不够,则在临时表 temporary table 中存储排序结果。完成排序后再根据行指针**回表读取记录**,该操作可能会导致大量随机 I/O 操作
说明:对于临时内存表,回表过程只是简单地根据数据行的位置,直接访问内存得到数据,不会导致多访问磁盘,优先选择该方式
@@ -5486,7 +5474,7 @@ GROUP BY 也会进行排序操作,与 ORDER BY 相比,GROUP BY 主要只是
* 创建索引:索引本身有序,不需要临时表,也不需要再额外排序
```mysql
- CREATE INDEX idx_emp_age_salary ON emp(age,salary);
+ CREATE INDEX idx_emp_age_salary ON emp(age, salary);
```

@@ -5562,7 +5550,7 @@ MySQL 4.1 版本之后,开始支持 SQL 的子查询

- 连接查询之所以效率更高 ,是因为不需要在内存中创建临时表来完成逻辑上需要两个步骤的查询工作
+ 连接查询之所以效率更高 ,是因为**不需要在内存中创建临时表**来完成逻辑上需要两个步骤的查询工作
@@ -5597,7 +5585,7 @@ MySQL 4.1 版本之后,开始支持 SQL 的子查询
* 优化方式二:方案适用于主键自增的表,可以把 LIMIT 查询转换成某个位置的查询
```mysql
- EXPLAIN SELECT * FROM tb_user_1 WHERE id > 200000 LIMIT 10; -- 写法 1
+ EXPLAIN SELECT * FROM tb_user_1 WHERE id > 200000 LIMIT 10; -- 写法 1
EXPLAIN SELECT * FROM tb_user_1 WHERE id BETWEEN 200000 and 200010; -- 写法 2
```
@@ -5761,7 +5749,7 @@ Flush 链表是一个用来**存储脏页**的链表,对于已经修改过的
* 从 Flush 链表中刷新一部分页面到磁盘:
* **后台线程定时**从 Flush 链表刷脏,根据系统的繁忙程度来决定刷新速率,这种方式称为 BUF_FLUSH_LIST
- * 线程刷脏的比较慢,导致用户线程加载一个新的数据页时发现没有空闲缓冲页,此时会尝试从 LRU 链表尾部寻找未修改的缓冲页直接释放,如果没有就将 LRU 链表尾部的一个脏页**同步刷新**到磁盘,速度较慢,这种方式称为 BUF_FLUSH_SINGLE_PAGE
+ * 线程刷脏的比较慢,导致用户线程加载一个新的数据页时发现没有空闲缓冲页,此时会尝试从 LRU 链表尾部寻找缓冲页直接释放,如果该页面是已经修改过的脏页就**同步刷新**到磁盘,速度较慢,这种方式称为 BUF_FLUSH_SINGLE_PAGE
* 从 LRU 链表的冷数据中刷新一部分页面到磁盘,即:BUF_FLUSH_LRU
* 后台线程会定时从 LRU 链表的尾部开始扫描一些页面,扫描的页面数量可以通过系统变量 `innodb_lru_scan_depth` 指定,如果在 LRU 链表中发现脏页,则把它们刷新到磁盘,这种方式称为 BUF_FLUSH_LRU
* 控制块里会存储该缓冲页是否被修改的信息,所以可以很容易的获取到某个缓冲页是否是脏页
@@ -5778,9 +5766,9 @@ Flush 链表是一个用来**存储脏页**的链表,对于已经修改过的
##### LRU 链表
-当 Buffer Pool 中没有空闲缓冲页时就需要淘汰掉最近最少使用的部分缓冲页,为了实现这个功能,MySQL 创建了一个 LRU 链表,当访问某个页时:
+Buffer Pool 需要保证缓存的命中率,所以 MySQL 创建了一个 LRU 链表,当访问某个页时:
-* 如果该页不在 Buffer Pool 中,把该页从磁盘加载进来后会将该缓冲页对应的控制块作为节点放入 **LRU 链表的头部**
+* 如果该页不在 Buffer Pool 中,把该页从磁盘加载进来后会将该缓冲页对应的控制块作为节点放入 **LRU 链表的头部**,保证热点数据在链表头
* 如果该页在 Buffer Pool 中,则直接把该页对应的控制块移动到 LRU 链表的头部,所以 LRU 链表尾部就是最近最少使用的缓冲页
MySQL 基于局部性原理提供了预读功能:
@@ -5788,7 +5776,7 @@ MySQL 基于局部性原理提供了预读功能:
* 线性预读:系统变量 `innodb_read_ahead_threshold`,如果顺序访问某个区(extent:16 KB 的页,连续 64 个形成一个区,一个区默认 1MB 大小)的页面数超过了该系统变量值,就会触发一次**异步读取**下一个区中全部的页面到 Buffer Pool 中
* 随机预读:如果某个区 13 个连续的页面都被加载到 Buffer Pool,无论这些页面是否是顺序读取,都会触发一次**异步读取**本区所有的其他页面到 Buffer Pool 中
-预读会造成加载太多用不到的数据页,造成那些使用**频率很高的数据页被挤到 LRU 链表尾部**,所以 InnoDB 将 LRU 链表分成两段:
+预读会造成加载太多用不到的数据页,造成那些使用频率很高的数据页被挤到 LRU 链表尾部,所以 InnoDB 将 LRU 链表分成两段,**冷热数据隔离**:
* 一部分存储使用频率很高的数据页,这部分链表也叫热数据,young 区,靠近链表头部的区域
* 一部分存储使用频率不高的冷数据,old 区,靠近链表尾部,默认占 37%,可以通过系统变量 `innodb_old_blocks_pct` 指定
@@ -5855,7 +5843,7 @@ MySQL 5.7.5 之前 `innodb_buffer_pool_size` 只支持在系统启动时修改
#### Change
-InnoDB 管理的 Buffer Pool 中有一块内存叫 Change Buffer 用来对**增删改操作**提供缓存,参数 `innodb_change_buffer_max_size ` 来动态设置,设置为 50 时表示 Change Buffer 的大小最多只能占用 Buffer Pool 的 50%
+InnoDB 管理的 Buffer Pool 中有一块内存叫 Change Buffer 用来对**增删改操作**提供缓存,可以通过参数来动态设置,设置为 50 时表示 Change Buffer 的大小最多占用 Buffer Pool 的 50%
* 唯一索引的更新不能使用 Change Buffer,需要将数据页读入内存,判断没有冲突在写入
* 普通索引可以使用 Change Buffer,**直接写入 Buffer 就结束**,不用校验唯一性
@@ -5912,7 +5900,7 @@ SHOW PROCESSLIST 获取线程信息后,处于 Sending to client 状态代表
read_rnd_buffer 是 MySQL 的随机读缓冲区,当按任意顺序读取记录行时将分配一个随机读取缓冲区,进行排序查询时,MySQL 会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,大小是由 read_rnd_buffer_size 参数控制的
-**Multi-Range Read 优化**,将随机 IO 转化为顺序 IO 以降低查询过程中 IO 开销,因为大多数的数据都是按照主键递增顺序插入得到,所以按照主键的递增顺序查询的话,对磁盘的读比较接近顺序读,能够提升读性能
+Multi-Range Read 优化,**将随机 IO 转化为顺序 IO** 以降低查询过程中 IO 开销,因为大多数的数据都是按照主键递增顺序插入得到,所以按照主键的递增顺序查询的话,对磁盘的读比较接近顺序读,能够提升读性能
二级索引为 a,聚簇索引为 id,优化回表流程:
@@ -6324,7 +6312,7 @@ InnoDB 存储引擎支持事务,所以加锁分析是基于该存储引擎
* Read Committed 级别,增删改操作会加写锁(行锁),读操作不加锁
- 在 Server 层过滤条件时发现不满足的记录会调用 unlock_row 方法释放该记录的行锁,保证最后只有满足条件的记录加锁,但是扫表过程中每条记录的**加锁操作不能省略**。所以对数据量很大的表做批量修改时,如果无法使用相应的索引(全表扫描),在Server 过滤数据时就会特别慢,出现虽然没有修改某些行的数据,但是还是被锁住了的现象(锁表),这种情况同样适用于 RR
+ 在 Server 层过滤条件时发现不满足的记录会调用 unlock_row 方法释放该记录的行锁,保证最后只有满足条件的记录加锁,但是扫表过程中每条记录的**加锁操作不能省略**。所以对数据量很大的表做批量修改时,如果无法使用相应的索引(全表扫描),在 Server 过滤数据时就会特别慢,出现虽然没有修改某些行的数据,但是还是被锁住了的现象(锁表),这种情况同样适用于 RR
* Repeatable Read 级别,增删改操作会加写锁,读操作不加锁。因为读写锁不兼容,**加了读锁后其他事务就无法修改数据**,影响了并发性能,为了保证隔离性和并发性,MySQL 通过 MVCC 解决了读写冲突。RR 级别下的锁有很多种,锁机制章节详解
@@ -6354,7 +6342,7 @@ InnoDB 存储引擎提供了两种事务日志:redo log(重做日志)和 u
* redo log 用于保证事务持久性
* undo log 用于保证事务原子性和隔离性
-undo log 属于逻辑日志,根据每行操作进行记录,记录了 SQL 执行相关的信息,用来回滚行记录到某个版本
+undo log 属于**逻辑日志**,根据每行操作进行记录,记录了 SQL 执行相关的信息,用来回滚行记录到某个版本
当事务对数据库进行修改时,InnoDB 会先记录对应的 undo log,如果事务执行失败或调用了 rollback 导致事务回滚,InnoDB 会根据 undo log 的内容**做与之前相反的操作**:
@@ -6438,9 +6426,9 @@ roll_pointer 是一个指针,**指向记录对应的 undo log 日志**,一
* 将旧纪录进行 delete mark,在更新语句提交后由 purge 线程移入垃圾链表
* 根据更新的各列的值创建一条新纪录,插入到聚簇索引中
-在对一条记录修改前会**将记录的隐藏列 trx_id 和 roll_pointer 的旧值记录到 undo log 对应的属性中**,这样当前记录的 roll_pointer 指向当前 undo log 记录,当前 undo log 记录的 roll_pointer 指向旧的 undo log 记录,**形成一个版本链**
+在对一条记录修改前会**将记录的隐藏列 trx_id 和 roll_pointer 的旧值记录到当前 undo log 对应的属性中**,这样当前记录的 roll_pointer 指向当前 undo log 记录,当前 undo log 记录的 roll_pointer 指向旧的 undo log 记录,**形成一个版本链**
-UPDATE、DELETE 操作产生的 undo 日志可能会用于其他事务的 MVCC 操作,所以不能立即删除
+UPDATE、DELETE 操作产生的 undo 日志会用于其他事务的 MVCC 操作,所以不能立即删除,INSERT 可以删除的原因是 MVCC 是对现有数据的快照
@@ -6561,7 +6549,7 @@ undo log 是逻辑日志,记录的是每个事务对数据执行的操作,
undo log 的作用:
* 保证事务进行 rollback 时的原子性和一致性,当事务进行回滚的时候可以用 undo log 的数据进行恢复
-* 用于 MVCC 快照读,通过读取 undo log 的历史版本数据可以实现不同事务版本号都拥有自己独立的快照数据版本
+* 用于 MVCC 快照读,通过读取 undo log 的历史版本数据可以实现不同事务版本号都拥有自己独立的快照数据
undo log 主要分为两种:
@@ -6607,7 +6595,7 @@ Read View 几个属性:
creator 创建一个 Read View,进行可见性算法分析:(解决了读未提交)
* db_trx_id == creator_trx_id:表示这个数据就是当前事务自己生成的,自己生成的数据自己肯定能看见,所以此数据对 creator 是可见的
-* db_trx_id < min_trx_id:该版本对应的事务 ID 小于 Read view 中的最小活跃事务 ID,则这个事务在当前事务之前就已经被提交了,对 creator 可见(因为比已提交的最大事务 ID 小的并不一定已经提交,所以应该先判断是否在活跃事务列表)
+* db_trx_id < min_trx_id:该版本对应的事务 ID 小于 Read view 中的最小活跃事务 ID,则这个事务在当前事务之前就已经被提交了,对 creator 可见(因为比已提交的最大事务 ID 小的并不一定已经提交,所以应该判断是否在活跃事务列表)
* db_trx_id >= max_trx_id:该版本对应的事务 ID 大于 Read view 中当前系统的最大事务 ID,则说明该数据是在当前 Read view 创建之后才产生的,对 creator 不可见
* min_trx_id<= db_trx_id < max_trx_id:判断 db_trx_id 是否在活跃事务列表 m_ids 中
@@ -6723,7 +6711,7 @@ Buffer Pool 的使用提高了读写数据的效率,但是如果 MySQL 宕机
* redo log **记录数据页的物理修改**,而不是某一行或某几行的修改,用来恢复提交后的数据页,只能**恢复到最后一次提交**的位置
* redo log 采用的是 WAL(Write-ahead logging,**预写式日志**),所有修改要先写入日志,再更新到磁盘,保证了数据不会因 MySQL 宕机而丢失,从而满足了持久性要求
-* 简单的 redo log 是纯粹的物理日志,负责的 redo log 会存在物理日志和逻辑日志
+* 简单的 redo log 是纯粹的物理日志,复杂的 redo log 会存在物理日志和逻辑日志
工作过程:MySQL 发生了宕机,InnoDB 会判断一个数据页在崩溃恢复时丢失了更新,就会将它读到内存,然后根据 redo log 内容更新内存,更新完成后,内存页变成脏页,然后进行刷脏
@@ -6749,15 +6737,15 @@ Buffer Pool 的使用提高了读写数据的效率,但是如果 MySQL 宕机
log buffer 被划分为若干 redo log block(块,类似数据页的概念),每个默认大小 512 字节,每个 block 由 12 字节的 log block head、496 字节的 log block body、4 字节的 log block trailer 组成
* 当数据修改时,先修改 Change Buffer 中的数据,然后在 redo log buffer 记录这次操作,写入 log buffer 的过程是**顺序写入**的(先写入前面的 block,写满后继续写下一个)
-* log buffer 中有一个指针 buf_free,来标识该位置之前都是填满的 block,该位置之后都是空闲区域(**碰撞指针**)
+* log buffer 中有一个指针 buf_free,来标识该位置之前都是填满的 block,该位置之后都是空闲区域
MySQL 规定对底层页面的一次原子访问称为一个 Mini-Transaction(MTR),比如在 B+ 树上插入一条数据就算一个 MTR
* 一个事务包含若干个 MTR,一个 MTR 对应一组若干条 redo log,一组 redo log 是不可分割的,在进行数据恢复时也把一组 redo log 当作一个不可分割的整体处理
-* 所以不是每生成一条 redo 日志就将其插入到 log buffer 中,而是一个 MTR 结束后**将一组 redo 日志写入 log buffer**
+* 不是每生成一条 redo 日志就将其插入到 log buffer 中,而是一个 MTR 结束后**将一组 redo 日志写入**
-InnoDB 的 redo log 是**固定大小**的,redo 日志在磁盘中以文件组的形式存储,同一组中的每个文件大小一样格式一样,
+InnoDB 的 redo log 是**固定大小**的,redo 日志在磁盘中以文件组的形式存储,同一组中的每个文件大小一样格式一样
* `innodb_log_group_home_dir` 代表磁盘存储 redo log 的文件目录,默认是当前数据目录
* `innodb_log_file_size` 代表文件大小,默认 48M,`innodb_log_files_in_group` 代表文件个数,默认 2 最大 100,所以日志的文件大小为 `innodb_log_file_size * innodb_log_files_in_group`
@@ -6774,10 +6762,10 @@ redo 日志文件也是由若干个 512 字节的 block 组成,日志文件的
##### 日志刷盘
-redo log 需要在事务提交时将日志写入磁盘,但是比将内存中的 Buffer Pool 修改的数据写入磁盘的速度快,原因:
+redo log 需要在事务提交时将日志写入磁盘,但是比 Buffer Pool 修改的数据写入磁盘的速度快,原因:
* 刷脏是随机 IO,因为每次修改的数据位置随机;redo log 和 binlog 都是**顺序写**,磁盘的顺序 IO 比随机 IO 速度要快
-* 刷脏是以数据页(Page)为单位的,一个页上的一个小修改都要整页写入;redo log 中只包含真正需要写入的部分,减少无效 IO
+* 刷脏是以数据页(Page)为单位的,一个页上的一个小修改都要整页写入;redo log 中只包含真正需要写入的部分,好几页的数据修改可能只记录在一个 redo log 页中,减少无效 IO
* **组提交机制**,可以大幅度降低磁盘的 IO 消耗
InnoDB 引擎会在适当的时候,把内存中 redo log buffer 持久化(fsync)到磁盘,具体的**刷盘策略**:
@@ -6788,7 +6776,6 @@ InnoDB 引擎会在适当的时候,把内存中 redo log buffer 持久化(fs
* 2:在事务提交时将缓冲区的 redo 日志异步写入到磁盘,不能保证提交时肯定会写入,只是有这个动作。日志已经在操作系统的缓存,如果操作系统没有宕机而 MySQL 宕机,也是可以恢复数据的
* 写入 redo log buffer 的日志超过了总容量的一半,就会将日志刷入到磁盘文件,这会影响执行效率,所以开发中应**避免大事务**
* 服务器关闭时
-* checkpoint 时(下小节详解)
* 并行的事务提交(组提交)时,会将将其他事务的 redo log 持久化到磁盘。假设事务 A 已经写入 redo log buffer 中,这时另外一个线程的事务 B 提交,如果 innodb_flush_log_at_trx_commit 设置的是 1,那么事务 B 要把 redo log buffer 里的日志全部持久化到磁盘,**因为多个事务共用一个 redo log buffer**,所以一次 fsync 可以刷盘多个事务的 redo log,提升了并发量
服务器启动后 redo 磁盘空间不变,所以 redo 磁盘中的日志文件是被**循环使用**的,采用循环写数据的方式,写完尾部重新写头部,所以要确保头部 log 对应的修改已经持久化到磁盘
@@ -6807,7 +6794,7 @@ lsn (log sequence number) 代表已经写入的 redo 日志量、flushed_to_disk
MTR 的执行过程中修改过的页对应的控制块会加到 Buffer Pool 的 flush 链表中,链表中脏页是按照第一次修改的时间进行排序的(头插),控制块中有两个指针用来记录脏页被修改的时间:
-* oldest_modification:第一次修改 Buffer Pool 中某个缓冲页时,将修改该页的 MTR **开始时**对应的 lsn 值写入这个属性,所以链表页是以该值进行排序的
+* oldest_modification:第一次修改 Buffer Pool 中某个缓冲页时,将修改该页的 MTR **开始时**对应的 lsn 值写入这个属性
* newest_modification:每次修改页面,都将 MTR 结束时全局的 lsn 值写入这个属性,所以该值是该页面最后一次修改后的 lsn 值
全局变量 checkpoint_lsn 表示**当前系统可以被覆盖的 redo 日志总量**,当 redo 日志对应的脏页已经被刷新到磁盘后,该文件空间就可以被覆盖重用,此时执行一次 checkpoint 来更新 checkpoint_lsn 的值存入管理信息(刷脏和执行一次 checkpoint 并不是同一个线程),该值的增量就代表磁盘文件中当前位置向后可以被覆盖的文件的量,所以该值是一直增大的
@@ -6840,10 +6827,8 @@ SHOW ENGINE INNODB STATUS\G
恢复的过程:按照 redo log 依次执行恢复数据,优化方式
-* 使用哈希表:根据 redo log 的 space ID 和 page number 属性计算出哈希值,将对同一页面的修改放入同一个槽里,可以一次性完成对某页的恢复,**避免了随机 IO**
-* 跳过已经刷新到磁盘中的页面:数据页的 File Header 中的 FILE_PAGE_LSN 属性(类似 newest_modification)表示最近一次修改页面时的 lsn 值,如果在 checkpoint 后,数据页被刷新到磁盘中,那么该页 lsn 属性肯定大于 checkpoint_lsn
-
-总结:先写 redo buffer,在写 change buffer,先刷 redo log,再刷脏,在删除完成刷脏 redo log
+* 使用哈希表:根据 redo log 的 space id 和 page number 属性计算出哈希值,将对同一页面的修改放入同一个槽里,可以一次性完成对某页的恢复,**避免了随机 IO**
+* 跳过已经刷新到磁盘中的页面:数据页的 File Header 中的 FILE_PAGE_LSN 属性(类似 newest_modification)表示最近一次修改页面时的 lsn 值,数据页被刷新到磁盘中,那么该页 lsn 属性肯定大于 checkpoint_lsn
@@ -6866,7 +6851,7 @@ MySQL 中还存在 binlog(二进制日志)也可以记录写操作并用于
* 内容不同:redo log 是物理日志,内容基于磁盘的 Page;binlog 的内容是二进制的,根据 binlog_format 参数的不同,可能基于SQL 语句、基于数据本身或者二者的混合(日志部分详解)
* 写入时机不同:binlog 在事务提交时一次写入;redo log 的写入时机相对多元
-binlog 为什么不支持奔溃恢复?
+binlog 为什么不支持崩溃恢复?
* binlog 记录的是语句,并不记录数据页级的数据(哪个页改了哪些地方),所以没有能力恢复数据页
* binlog 是追加写,保存全量的日志,没有标志确定从哪个点开始的数据是已经刷盘了,而 redo log 只要在 checkpoint_lsn 后面的就是没有刷盘的
@@ -6881,14 +6866,14 @@ binlog 为什么不支持奔溃恢复?
更新一条记录的过程:写之前一定先读
-* 在 B+ 树中定位到该记录(这个过程也被称作加锁读),如果该记录所在的页面不在 Buffer Pool 里,先将其加载进内存
+* 在 B+ 树中定位到该记录,如果该记录所在的页面不在 Buffer Pool 里,先将其加载进内存
* 首先更新该记录对应的聚簇索引,更新聚簇索引记录时:
* 更新记录前向 undo 页面写 undo 日志,由于这是更改页面,所以需要记录一下相应的 redo 日志
- 注意:修改 undo页面也是在**修改页面**,事务凡是修改页面就需要先记录相应的 redo 日志
+ 注意:修改 undo 页面也是在**修改页面**,事务只要修改页面就需要先记录相应的 redo 日志
- * 然后**先记录对应的的 redo 日志**(等待 MTR 提交后写入 redo log buffer),**最后进行真正的更新记录**
+ * 然后**记录对应的 redo 日志**(等待 MTR 提交后写入 redo log buffer),**最后进行真正的更新记录**
* 更新其他的二级索引记录,不会再记录 undo log,只记录 redo log 到 buffer 中
@@ -6929,7 +6914,7 @@ update T set c=c+1 where ID=2;
* Prepare 阶段:存储引擎将该事务的 **redo 日志刷盘**,并且将本事务的状态设置为 PREPARE,代表执行完成随时可以提交事务
* Commit 阶段:先将事务执行过程中产生的 binlog 刷新到硬盘,再执行存储引擎的提交工作,引擎把 redo log 改成提交状态
-redo log 和 binlog 都可以用于表示事务的提交状态,而**两阶段提交就是让这两个状态保持逻辑上的一致**,也有利于主从复制,更好的保持主从数据的一致性
+存储引擎层的 redo log 和 server 层的 binlog 可以认为是一个分布式事务, 都可以用于表示事务的提交状态,而**两阶段提交就是让这两个状态保持逻辑上的一致**,也有利于主从复制,更好的保持主从数据的一致性
@@ -6941,12 +6926,12 @@ redo log 和 binlog 都可以用于表示事务的提交状态,而**两阶段
系统崩溃前没有提交的事务的 redo log 可能已经刷盘(定时线程或者 checkpoint),怎么处理崩溃恢复?
-工作流程:通过 undo log 在服务器重启时将未提交的事务回滚掉。首先定位到 128 个回滚段遍历 slot,获取 undo 链表首节点页面的 undo segement header 中的 TRX_UNDO_STATE 属性,表示当前链表的事务属性,事务状态是活跃的就全部回滚,如果是 PREPARE 状态,就需要根据 binlog 的状态进行判断:
+工作流程:获取 undo 链表首节点页面的 undo segement header 中的 TRX_UNDO_STATE 属性,表示当前链表的事务属性,**事务状态是活跃(未提交)的就全部回滚**,如果是 PREPARE 状态,就需要根据 binlog 的状态进行判断:
* 如果在时刻 A 发生了崩溃(crash),由于此时 binlog 还没完成,所以需要进行回滚
* 如果在时刻 B 发生了崩溃,redo log 和 binlog 有一个共**同的数据字段叫 XID**,崩溃恢复的时候,会按顺序扫描 redo log:
* 如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,说明 binlog 也已经记录完整,直接从 redo log 恢复数据
- * 如果 redo log 里面的事务只有 prepare,就根据 XID 去 binlog 中判断对应的事务是否存在并完整,如果完整可以恢复数据,提交事务
+ * 如果 redo log 里面的事务只有 prepare,就根据 XID 去 binlog 中判断对应的事务是否存在并完整,如果完整可以恢复数据
判断一个事务的 binlog 是否完整的方法:
@@ -7285,7 +7270,7 @@ InnoDB 与 MyISAM 的最大不同有两点:一是支持事务;二是采用
行级锁,也称为记录锁(Record Lock),InnoDB 实现了以下两种类型的行锁:
- 共享锁 (S):又称为读锁,简称 S 锁,多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改
-- 排他锁 (X):又称为写锁,简称 X 锁,不能与其他锁并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁,只有获取排他锁的事务是可以对数据读取和修改
+- 排他锁 (X):又称为写锁,简称 X 锁,不能与其他锁并存,获取排他锁的事务是可以对数据读取和修改
RR 隔离界别下,对于 UPDATE、DELETE 和 INSERT 语句,InnoDB 会**自动给涉及数据集加排他锁**(行锁),在 commit 时自动释放;对于普通 SELECT 语句,不会加任何锁(只是针对 InnoDB 层来说的,因为在 Server 层会**加 MDL 读锁**),通过 MVCC 防止并发冲突
@@ -7416,7 +7401,7 @@ InnoDB 会对间隙(GAP)进行加锁,就是间隙锁 (RR 隔离级别下
InnoDB 加锁的基本单位是 next-key lock,该锁是行锁和 gap lock 的组合(X or S 锁),但是加锁过程是分为间隙锁和行锁两段执行
-* 可以**保护当前记录和前面的间隙**,遵循左开右闭原则,单纯的是间隙锁左开右开
+* 可以**保护当前记录和前面的间隙**,遵循左开右闭原则,单纯的间隙锁是左开右开
* 假设有 10、11、13,那么可能的间隙锁包括:(负无穷,10]、(10,11]、(11,13]、(13,正无穷)
几种索引的加锁情况:
@@ -7426,7 +7411,7 @@ InnoDB 加锁的基本单位是 next-key lock,该锁是行锁和 gap lock 的
* 范围查询无论是否是唯一索引,都需要访问到不满足条件的第一个值为止
* 对于联合索引且是唯一索引,如果 where 条件只包括联合索引的一部分,那么会加间隙锁
-间隙锁优点:RR 级别下间隙锁可以解决事务的一部分的**幻读问题**,通过对间隙加锁,可以防止读取过程中数据条目发生变化。一部分的意思是不会对全部间隙加锁,只能加锁一部分的间隙。
+间隙锁优点:RR 级别下间隙锁可以**解决事务的一部分的幻读问题**,通过对间隙加锁,可以防止读取过程中数据条目发生变化。一部分的意思是不会对全部间隙加锁,只能加锁一部分的间隙
间隙锁危害:
@@ -7505,7 +7490,7 @@ InnoDB 为了支持多粒度的加锁,允许行锁和表锁同时存在,支
* 0:全部采用 AUTO_INC 锁
* 1:全部采用轻量级锁
-* 2:混合使用,在插入记录的数量确定是采用轻量级锁,不确定时采用 AUTO_INC 锁
+* 2:混合使用,在插入记录的数量确定时采用轻量级锁,不确定时采用 AUTO_INC 锁
@@ -7762,7 +7747,7 @@ MySQL 的主从之间维持了一个**长连接**。主库内部有一个线程
主从复制主要依赖的是 binlog,MySQL 默认是异步复制,需要三个线程:
-- binlog thread:在主库事务提交时,负责把数据变更记录在二进制日志文件 binlog 中,并通知 slave 有数据更新
+- binlog thread:在主库事务提交时,把数据变更记录在日志文件 binlog 中,并通知 slave 有数据更新
- I/O thread:负责从主服务器上**拉取二进制日志**,并将 binlog 日志内容依次写到 relay log 中转日志的最末端,并将新的 binlog 文件名和 offset 记录到 master-info 文件中,以便下一次读取日志时从指定 binlog 日志文件及位置开始读取新的 binlog 日志内容
- SQL thread:监测本地 relay log 中新增了日志内容,读取中继日志并重做其中的 SQL 语句,从库在 relay-log.info 中记录当前应用中继日志的文件名和位点以便下一次执行
@@ -7846,7 +7831,7 @@ coordinator 就是原来的 SQL Thread,并行复制中它不再直接更新数
* 线程分配完成并不是立即执行,为了防止造成更新覆盖,更新同一 DB 的两个事务必须被分发到同一个工作线程
* 同一个事务不能被拆开,必须放到同一个工作线程
-MySQL 5.6 版本的策略:每个线程对应一个 hash 表,用于保存当前这个线程的执行队列里的事务所涉及的表,hash 表的 key 是数据库 名,value 是一个数字,表示队列中有多少个事务修改这个库,适用于主库上有多个 DB 的情况
+MySQL 5.6 版本的策略:每个线程对应一个 hash 表,用于保存当前这个线程的执行队列里的事务所涉及的表,hash 表的 key 是数据库名,value 是一个数字,表示队列中有多少个事务修改这个库,适用于主库上有多个 DB 的情况
每个事务在分发的时候,跟线程的**冲突**(事务操作的是同一个库)关系包括以下三种情况:
@@ -7856,7 +7841,7 @@ MySQL 5.6 版本的策略:每个线程对应一个 hash 表,用于保存当
优缺点:
-* 构造 hash 值的时候很快,只需要库名,而且一个实例上 DB 数也不会很多,不会出现需要构造很多个项的情况
+* 构造 hash 值的时候很快,只需要库名,而且一个实例上 DB 数也不会很多,不会出现需要构造很多项的情况
* 不要求 binlog 的格式,statement 格式的 binlog 也可以很容易拿到库名(日志章节详解了 binlog)
* 主库上的表都放在同一个 DB 里面,这个策略就没有效果了;或者不同 DB 的热点不同,比如一个是业务逻辑库,一个是系统配置库,那也起不到并行的效果,需要**把相同热度的表均匀分到这些不同的 DB 中**,才可以使用这个策略
@@ -7987,7 +7972,7 @@ SELECT master_pos_wait(file, pos[, timeout]);
* 选定一个从库执行判断位点语句,如果返回值是 >=0 的正整数,说明从库已经同步完事务,可以在这个从库执行查询语句
* 如果出现其他情况,需要到主库执行查询语句
-注意:如果所有的从库都延迟超过 timeout 秒,查询压力就都跑到主库上,所以需要进行权衡
+注意:如果所有的从库都延迟超过 timeout 秒,查询压力就都跑到主库上,所以需要进行权衡
@@ -8289,7 +8274,7 @@ GTID=source_id:transaction_id
* source_id:是一个实例第一次启动时自动生成的,是一个全局唯一的值
* transaction_id:初始值是 1,每次提交事务的时候分配给这个事务,并加 1,是连续的(区分事务 ID,事务 ID 是在执行时生成)
-启动 MySQL 实例时,加上参数 `gtid_mode=on` 和 `enforce_gtid_consistency=on` 就可以启动 GTID 模式,每个事务都会和一个 GTID 一一对应,每个 MySQL 实例都维护了一个 **GTID 集合**,用来对应当前实例执行过的所有事务
+启动 MySQL 实例时,加上参数 `gtid_mode=on` 和 `enforce_gtid_consistency=on` 就可以启动 GTID 模式,每个事务都会和一个 GTID 一一对应,每个 MySQL 实例都维护了一个 GTID 集合,用来存储当前实例**执行过的所有事务**
GTID 有两种生成方式,使用哪种方式取决于 session 变量 gtid_next:
@@ -8357,7 +8342,7 @@ GTID 有两种生成方式,使用哪种方式取决于 session 变量 gtid_nex
### 日志分类
-在任何一种数据库中,都会有各种各样的日志,记录着数据库工作的过程,可以帮助数据库管理员追踪数据库曾经发生过的各种事件。
+在任何一种数据库中,都会有各种各样的日志,记录着数据库工作的过程,可以帮助数据库管理员追踪数据库曾经发生过的各种事件
MySQL日志主要包括六种:
@@ -8558,7 +8543,7 @@ mysqlbinlog log-file;
#### 数据恢复
-误删库或者表时,需要根据 binlog 进行数据恢复,
+误删库或者表时,需要根据 binlog 进行数据恢复
一般情况下数据库有定时的全量备份,假如每天 0 点定时备份,12 点误删了库,恢复流程:
@@ -8611,7 +8596,7 @@ SELECT * FROM tb_book WHERE id < 8
### 慢日志
-慢查询日志记录所有执行时间超过 long_query_time 并且扫描记录数不小于 min_examined_row_limit 的所有的 SQL 语句的日志。long_query_time 默认为 10 秒,最小为 0, 精度到微秒
+慢查询日志记录所有执行时间超过 long_query_time 并且扫描记录数不小于 min_examined_row_limit 的所有的 SQL 语句的日志long_query_time 默认为 10 秒,最小为 0, 精度到微秒
慢查询日志默认是关闭的,可以通过两个参数来控制慢查询日志,配置文件 `/etc/mysql/my.cnf`:
@@ -8747,9 +8732,9 @@ long_query_time=10
### 概述
-NoSQL(Not-Only SQL):泛指非关系型的数据库,作为关系型数据库的补充。
+NoSQL(Not-Only SQL):泛指非关系型的数据库,作为关系型数据库的补充
-MySQL 支持 ACID 特性,保证可靠性和持久性,读取性能不高,因此需要缓存的来减缓数据库的访问压力。
+MySQL 支持 ACID 特性,保证可靠性和持久性,读取性能不高,因此需要缓存的来减缓数据库的访问压力
作用:应对基于海量用户和海量数据前提下的数据处理问题
@@ -8792,17 +8777,6 @@ Redis (REmote DIctionary Server) :用 C 语言开发的一个开源的高性
* 有序集合类型:zset/sorted_set(TreeSet)
* 支持持久化,可以进行数据灾难恢复
-应用:
-
-* 为热点数据加速查询(主要场景),如热点商品、热点新闻、热点资讯、推广类等高访问量信息等
-
-* 即时信息查询,如排行榜、网站访问统计、公交到站信息、在线人数(聊天室、网站)、设备信号等
-
-* 时效性信息控制,如验证码控制、投票控制等
-
-* 分布式数据共享,如分布式集群架构中的 session 分离
-* 消息队列
-
***
@@ -9097,7 +9071,7 @@ redis[1]>
#### key space
-Redis 是一个键值对(key-value pair)数据库服务器,每个数据库都由一个 redisDb 结构表示,redisDb.dict 字典中保存了数据库的所有键值对,将这个字典称为键空间(key space)
+Redis 是一个键值对(key-value pair)数据库服务器,每个数据库都由一个 redisDb 结构表示,redisDb.dict **字典中保存了数据库的所有键值对**,将这个字典称为键空间(key space)
```c
typedef struct redisDB {
@@ -9274,7 +9248,7 @@ Redis 通过过期字典可以检查一个给定键是否过期:
* AOF 重写,会对数据库中的键进行检查,忽略已经过期的键
* 复制:当服务器运行在复制模式下时,从服务器的过期键删除动作由主服务器控制
* 主服务器在删除一个过期键之后,会显式地向所有从服务器发送一个 DEL 命令,告知从服务器删除这个过期键
- * 从服务器在执行客户端发送的读命令时,即使碰到过期键也不会将过期键删除,会当作未过期键处理,只有在接到主服务器发来的 DEL 命令之后,才会删除过期键
+ * 从服务器在执行客户端发送的读命令时,即使碰到过期键也不会将过期键删除,会当作未过期键处理,只有在接到主服务器发来的 DEL 命令之后,才会删除过期键(数据不一致)
@@ -9293,7 +9267,7 @@ Redis 通过过期字典可以检查一个给定键是否过期:
针对过期数据有三种删除策略:
- 定时删除
-- 惰性删除
+- 惰性删除(被动删除)
- 定期删除
Redis 采用惰性删除和定期删除策略的结合使用
@@ -9348,15 +9322,13 @@ Redis 采用惰性删除和定期删除策略的结合使用
* 如果删除操作执行得太频繁,或者执行时间太长,就会退化成定时删除策略,将 CPU 时间过多地消耗在删除过期键上
* 如果删除操作执行得太少,或者执行时间太短,定期删除策略又会和惰性删除策略一样,出现浪费内存的情况
-所以采用定期删除策略的话,服务器必须根据情况合理地设置删除操作的执行时长和执行频率
-
定期删除是**周期性轮询 Redis 库中的时效性**数据,从过期字典中随机抽取一部分键检查,利用过期数据占比的方式控制删除频度
- Redis 启动服务器初始化时,读取配置 server.hz 的值,默认为 10,执行指令 info server 可以查看,每秒钟执行 server.hz 次 `serverCron() → activeExpireCycle()`
- activeExpireCycle() 对某个数据库中的每个 expires 进行检测,工作模式:
- * 轮询每个数据库,从数据库中取出一定数量的随机键进行检查,并删除其中的过期键
+ * 轮询每个数据库,从数据库中取出一定数量的随机键进行检查,并删除其中的过期键,如果过期 key 的比例超过了 25%,则继续重复此过程,直到过期 key 的比例下降到 25% 以下,或者这次任务的执行耗时超过了 25 毫秒
* 全局变量 current_db 用于记录 activeExpireCycle() 的检查进度(哪一个数据库),下一次调用时接着该进度处理
* 随着函数的不断执行,服务器中的所有数据库都会被检查一遍,这时将 current_db 重置为 0,然后再次开始新一轮的检查
@@ -9512,7 +9484,7 @@ SORT key ALPHA #对key中字母排序,按照字典序
对于 `SORT key [ASC/DESC]` 函数:
* 在执行升序排序时,排序算法使用的对比函数产生升序对比结果
-* 在执行降序排序时,排序算法所使用的对比函数产生降序对比结果
+* 在执行降序排序时,排序算法使用的对比函数产生降序对比结果
@@ -9744,7 +9716,7 @@ Redis 基于 Reactor 模式开发了网络事件处理器,这个处理器被
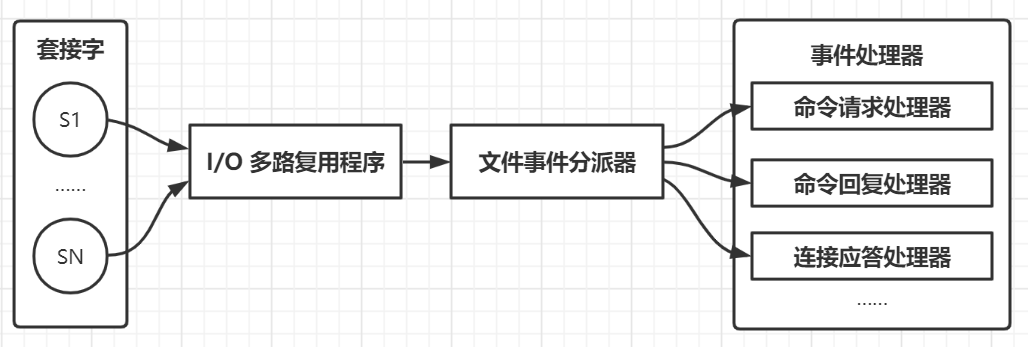 -尽管多个文件事件可能会并发出现,但是 I/O 多路复用程序将所有产生事件的套接字处理请求放入一个**单线程的执行队列**中,通过队列有序、同步的向文件事件分派器传送套接字,上一个套接字产生的事件处理完后,才会继续向分派器传送下一个
+I/O 多路复用程序将所有产生事件的套接字处理请求放入一个**单线程的执行队列**中,通过队列有序、同步的向文件事件分派器传送套接字,上一个套接字产生的事件处理完后,才会继续向分派器传送下一个
-尽管多个文件事件可能会并发出现,但是 I/O 多路复用程序将所有产生事件的套接字处理请求放入一个**单线程的执行队列**中,通过队列有序、同步的向文件事件分派器传送套接字,上一个套接字产生的事件处理完后,才会继续向分派器传送下一个
+I/O 多路复用程序将所有产生事件的套接字处理请求放入一个**单线程的执行队列**中,通过队列有序、同步的向文件事件分派器传送套接字,上一个套接字产生的事件处理完后,才会继续向分派器传送下一个
 @@ -9763,7 +9735,7 @@ Redis 单线程也能高效的原因:
##### 多路复用
-Redis 的 I/O 多路复用程序的所有功能都是通过包装常见的 select 、epoll、 evport 和 kqueue 这些函数库来实现的,Redis在 I/O 多路复用程序的实现源码中用 #include 宏定义了相应的规则,编译时自动选择系统中**性能最高的多路复用函数**来作为底层实现
+Redis 的 I/O 多路复用程序的所有功能都是通过包装常见的 select 、epoll、 evport 和 kqueue 这些函数库来实现的,Redis 在 I/O 多路复用程序的实现源码中用 #include 宏定义了相应的规则,编译时自动选择系统中**性能最高的多路复用函数**来作为底层实现
I/O 多路复用程序监听多个套接字的 AE_READABLE 事件和 AE_WRITABLE 事件,这两类事件和套接字操作之间的对应关系如下:
@@ -9790,9 +9762,9 @@ Redis 为文件事件编写了多个处理器,这些事件处理器分别用
Redis 客户端与服务器进行连接并发送命令的整个过程:
* Redis 服务器正在运作监听套接字的 AE_READABLE 事件,关联连接应答处理器
-* 当 Redis 客户端向服务器发起连接,监听套接字将产生 AE_READABLE 事件,触发连接应答处理器执行,对客户端的连接请求进行应答,创建客户端套接字以及客户端状态,并将客户端套接字的 AE_READABLE 事件与命令请求处理器进行关联
+* 当 Redis 客户端向服务器发起连接,监听套接字将产生 AE_READABLE 事件,触发连接应答处理器执行,对客户端的连接请求进行应答,创建客户端套接字以及客户端状态,并将客户端套接字的 **AE_READABLE 事件与命令请求处理器**进行关联
* 客户端向服务器发送命令请求,客户端套接字产生 AE_READABLE 事件,引发命令请求处理器执行,读取客户端的命令内容传给相关程序去执行
-* 执行命令会产生相应的命令回复,为了将这些命令回复传送回客户端,服务器会将客户端套接字的 AE_WRITABLE 事件与命令回复处理器进行关联
+* 执行命令会产生相应的命令回复,为了将这些命令回复传送回客户端,服务器会将客户端套接字的 **AE_WRITABLE 事件与命令回复处理器**进行关联
* 当客户端尝试读取命令回复时,客户端套接字产生 AE_WRITABLE 事件,触发命令回复处理器执行,在命令回复全部写入套接字后,服务器就会解除客户端套接字的 AE_WRITABLE 事件与命令回复处理器之间的关联
@@ -9829,8 +9801,6 @@ Redis 的时间事件分为以下两类:
无序链表并不影响时间事件处理器的性能,因为正常模式下的 Redis 服务器**只使用 serverCron 一个时间事件**,在 benchmark 模式下服务器也只使用两个时间事件,所以无序链表不会影响服务器的性能,几乎可以按照一个指针处理
-服务器 → serverCron 详解该时间事件
-
***
@@ -9842,18 +9812,6 @@ Redis 的时间事件分为以下两类:
服务器中同时存在文件事件和时间事件两种事件类型,调度伪代码:
```python
-# Redis 服务器的主函数的伪代码
-def main():
- # 初始化服务器
- init_server()
-
- # 循环处理事件,直到服务器关闭
- while server_is_not_shutdown():
- aeProcessEvents()
-
- # 服务器关闭
- clean_server()
-
# 事件调度伪代码
def aeProcessEvents():
# 获取到达时间离当前时间最接近的时间事件
@@ -9997,7 +9955,7 @@ typedef struct redisClient {
客户端状态包括两类属性
* 一类是比较通用的属性,这些属性很少与特定功能相关,无论客户端执行的是什么工作,都要用到这些属性
-* 另一类是和特定功能相关的属性,比如操作数据库时用到的 db 属性和 dict id属性,执行事务时用到的 mstate 属性,以及执行 WATCH 命令时用到的 watched_keys 属性等,代码中没有列出
+* 另一类是和特定功能相关的属性,比如操作数据库时用到的 db 属性和 dict id 属性,执行事务时用到的 mstate 属性,以及执行 WATCH 命令时用到的 watched_keys 属性等,代码中没有列出
@@ -10156,7 +10114,7 @@ obuf_soft_limit_reached_time 属性记录了**输出缓冲区第一次到达软
服务器使用不同的方式来创建和关闭不同类型的客户端
-如果客户端是通过网络连接与服务器进行连接的普通客户端,那么在客户端使用 connect 函数连接到服务器时,服务器就会调用连接事件处理器为客户端创建相应的客户端状态,并将这个新的客户端状态添加到服务器状态结构 clients 链表的末尾
+如果客户端是通过网络连接与服务器进行连接的普通客户端,那么在客户端使用 connect 函数连接到服务器时,服务器就会调用连接应答处理器为客户端创建相应的客户端状态,并将这个新的客户端状态添加到服务器状态结构 clients 链表的末尾

@@ -10338,7 +10296,7 @@ struct redisCommand {
##### 基本介绍
-Redis 服务器以周期性事件的方式来运行 serverCron 函数,服务器初始化时读取配置 server.hz 的值,默认为 10,代表每秒钟执行 10 次,即每隔 100 毫秒执行一次,执行指令 info server 可以查看
+Redis 服务器以周期性事件的方式来运行 serverCron 函数,服务器初始化时读取配置 server.hz 的值,默认为 10,代表每秒钟执行 10 次,即**每隔 100 毫秒执行一次**,执行指令 info server 可以查看
serverCron 函数负责定期对自身的资源和状态进行检查和调整,从而确保服务器可以长期、稳定地运行
@@ -10507,7 +10465,7 @@ clientsCron 函数对一定数量的客户端进行以下两个检查:
* 如果客户端与服务器之间的连接巳经超时(很长一段时间客户端和服务器都没有互动),那么程序释放这个客户端
* 如果客户端在上一次执行命令请求之后,输入缓冲区的大小超过了一定的长度,那么程序会释放客户端当前的输入缓冲区,并重新创建一个默认大小的输入缓冲区,从而防止客户端的输入缓冲区耗费了过多的内存
-databasesCron 函数会对服务器中的一部分数据库进行检查,删除其中的过期键,并在有需要时 对字典进行收缩操作
+databasesCron 函数会对服务器中的一部分数据库进行检查,删除其中的过期键,并在有需要时对字典进行收缩操作
@@ -10517,7 +10475,7 @@ databasesCron 函数会对服务器中的一部分数据库进行检查,删除
##### 持久状态
-服务器状态中记录执行 BGSAVE 命令和 BGREWRITEAOF 命令的子进程的 ID,
+服务器状态中记录执行 BGSAVE 命令和 BGREWRITEAOF 命令的子进程的 ID
```c
struct redisServer {
@@ -10570,7 +10528,7 @@ serverCron 函数会检查 BGSAVE 或者 BGREWRITEAOF 命令是否正在执行
-##### cronloops
+##### 执行次数
服务器状态的 cronloops 属性记录了 serverCron 函数执行的次数
@@ -10622,7 +10580,7 @@ struct redisServer {
initServer 还进行了非常重要的设置操作:
* 为服务器设置进程信号处理器
-* 创建共享对象,包含 OK、ERR、整数 1 到 10000 的字符串对象等
+* 创建共享对象,包含 OK、ERR、**整数 1 到 10000 的字符串对象**等
* **打开服务器的监听端口**
* **为 serverCron 函数创建时间事件**, 等待服务器正式运行时执行 serverCron 函数
* 如果 AOF 持久化功能已经打开,那么打开现有的 AOF 文件,如果 AOF 文件不存在,那么创建并打开一个新的 AOF 文件 ,为 AOF 写入做好准备
@@ -10788,7 +10746,7 @@ struct sdshdr {
};
```
-SDS 遵循 C 字符串**以空字符结尾**的惯例, 保存空字符的 1 字节不计算在 len 属性,SDS 会自动为空字符分配额外的 1 字节空间和添加空字符到字符串末尾,所以空字符对于 SDS 的使用者来说是完全透明的
+SDS 遵循 C 字符串**以空字符结尾**的惯例,保存空字符的 1 字节不计算在 len 属性,SDS 会自动为空字符分配额外的 1 字节空间和添加空字符到字符串末尾,所以空字符对于 SDS 的使用者来说是完全透明的
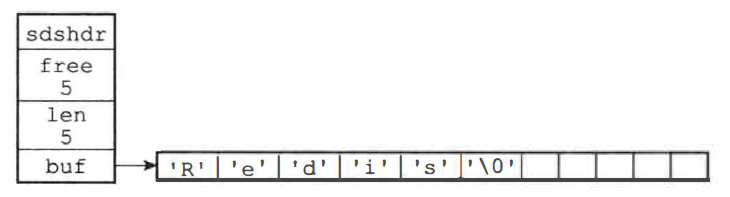
@@ -10818,7 +10776,7 @@ SDS 遵循 C 字符串**以空字符结尾**的惯例, 保存空字符的 1
二进制安全:
* C 字符串中的字符必须符合某种编码(比如 ASCII)方式,除了字符串末尾以外其他位置不能包含空字符,否则会被误认为是字符串的结尾,所以只能保存文本数据
-* SDS 的 API 都是二进制安全的,使用字节数组 buf 保存一系列的二进制数据,使用 len 属性来判断数据的结尾,所以可以保存图片、视频、压缩文件等二进制数据
+* SDS 的 API 都是二进制安全的,使用字节数组 buf 保存一系列的二进制数据,**使用 len 属性来判断数据的结尾**,所以可以保存图片、视频、压缩文件等二进制数据
兼容 C 字符串的函数:SDS 会在为 buf 数组分配空间时多分配一个字节来保存空字符,所以可以重用一部分 C 字符串函数库的函数
@@ -10836,7 +10794,7 @@ SDS 通过未使用空间解除了字符串长度和底层数组长度之间的
内存重分配涉及复杂的算法,需要执行**系统调用**,是一个比较耗时的操作,SDS 的两种优化策略:
-* 空间预分配:当 SDS 的 API 进行修改并且需要进行空间扩展时,程序不仅会为 SDS 分配修改所必需的空间, 还会为 SDS 分配额外的未使用空间
+* 空间预分配:当 SDS 需要进行空间扩展时,程序不仅会为 SDS 分配修改所必需的空间, 还会为 SDS 分配额外的未使用空间
* 对 SDS 修改之后,SDS 的长度(len 属性)小于 1MB,程序分配和 len 属性同样大小的未使用空间,此时 len 和 free 相等
@@ -10848,7 +10806,7 @@ SDS 通过未使用空间解除了字符串长度和底层数组长度之间的
在扩展 SDS 空间前,API 会先检查 free 空间是否足够,如果足够就无需执行内存重分配,所以通过预分配策略,SDS 将连续增长 N 次字符串所需内存的重分配次数从**必定 N 次降低为最多 N 次**
-* 惰性空间释放:当 SDS 的 API 需要缩短字符串时,程序并不立即使用内存重分配来回收缩短后多出来的字节,而是使用 free 属性将这些字节的数量记录起来,并等待将来使用
+* 惰性空间释放:当 SDS 缩短字符串时,程序并不立即使用内存重分配来回收缩短后多出来的字节,而是使用 free 属性将这些字节的数量记录起来,并等待将来复用
SDS 提供了相应的 API 来真正释放 SDS 的未使用空间,所以不用担心空间惰性释放策略造成的内存浪费问题
@@ -11047,7 +11005,7 @@ load_factor = ht[0].used / ht[0].size
原因:执行该命令的过程中,Redis 需要创建当前服务器进程的子进程,而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率,通过提高执行扩展操作的负载因子,尽可能地避免在子进程存在期间进行哈希表扩展操作,可以避免不必要的内存写入操作,最大限度地节约内存
-哈希表执行收缩的条件:负载因子小于 0.1(自动执行,servreCron 中检测),缩小为字典中数据个数的 50% 左右
+哈希表执行收缩的条件:负载因子小于 0.1(自动执行,servreCron 中检测)
@@ -11063,7 +11021,7 @@ load_factor = ht[0].used / ht[0].size
* 如果执行的是扩展操作,ht[1] 的大小为第一个大于等于 $ht[0].used * 2$ 的 $2^n$
* 如果执行的是收缩操作,ht[1] 的大小为第一个大于等于 $ht[0].used$ 的 $2^n$
* 将保存在 ht[0] 中所有的键值对重新计算哈希值和索引值,迁移到 ht[1] 上
-* 当 ht[0] 包含的所有键值对都迁移到了 ht[1] 之后(ht[0]变为空表), 释放 ht[0],将 ht[1] 设置为 ht[0],并在 ht[1] 创建一个新的空白哈希表,为下一次 rehash 做准备
+* 当 ht[0] 包含的所有键值对都迁移到了 ht[1] 之后(ht[0] 变为空表),释放 ht[0],将 ht[1] 设置为 ht[0],并在 ht[1] 创建一个新的空白哈希表,为下一次 rehash 做准备
如果哈希表里保存的键值对数量很少,rehash 就可以在瞬间完成,但是如果哈希表里数据很多,那么要一次性将这些键值对全部 rehash 到 ht[1] 需要大量计算,可能会导致服务器在一段时间内停止服务
@@ -11071,8 +11029,8 @@ Redis 对 rehash 做了优化,使 rehash 的动作并不是一次性、集中
* 为 ht[1] 分配空间,此时字典同时持有 ht[0] 和 ht[1] 两个哈希表
* 在字典中维护了一个索引计数器变量 rehashidx,并将变量的值设为 0,表示 rehash 正式开始
-* 在 rehash 进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1],rehash 完成之后**将 rehashidx 属性的值增一**
-* 随着字典操作的不断执行,最终在某个时间点上 ht[0] 的所有键值对都被 rehash 至 ht[1],这时程序将 rehashidx 属性的值设为 -1,表示 rehash 操作已完成
+* 在 rehash 进行期间,每次对字典执行增删改查操作时,程序除了执行指定的操作以外,还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1],rehash 完成之后**将 rehashidx 属性的值增一**
+* 随着字典操作的不断执行,最终在某个时间点 ht[0] 的所有键值对都被 rehash 至 ht[1],将 rehashidx 属性的值设为 -1
渐进式 rehash 采用**分而治之**的方式,将 rehash 键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,从而避免了集中式 rehash 带来的庞大计算量
@@ -11145,23 +11103,23 @@ typedef struct zskiplistNode {
层:level 数组包含多个元素,每个元素包含指向其他节点的指针。根据幕次定律(power law,越大的数出现的概率越小)**随机**生成一个介于 1 和 32 之间的值(Redis5 之后最大为 64)作为 level 数组的大小,这个大小就是层的高度,节点的第一层是 level[0] = L1
-前进指针:forward 用于从表头到表尾方向正序(升序)遍历节点,遇到 NULL 停止遍历
+前进指针:forward 用于从表头到表尾方向**正序(升序)遍历节点**,遇到 NULL 停止遍历
-跨度:span 用于记录两个节点之间的距离,用来**计算排位(rank)**:
+跨度:span 用于记录两个节点之间的距离,用来计算排位(rank):
* 两个节点之间的跨度越大相距的就越远,指向 NULL 的所有前进指针的跨度都为 0
-* 在查找某个节点的过程中,将沿途访问过的所有层的跨度累计起来,结果就是目标节点在跳跃表中的排位,按照上图所示:
+* 在查找某个节点的过程中,**将沿途访问过的所有层的跨度累计起来,结果就是目标节点在跳跃表中的排位**,按照上图所示:
查找分值为 3.0 的节点,沿途经历的层:查找的过程只经过了一个层,并且层的跨度为 3,所以目标节点在跳跃表中的排位为 3
查找分值为 2.0 的节点,沿途经历的层:经过了两个跨度为 1 的节点,因此可以计算出目标节点在跳跃表中的排位为 2
-后退指针:backward 用于从表尾到表头方向逆序(降序)遍历节点
+后退指针:backward 用于从表尾到表头方向**逆序(降序)遍历节点**
-分值:score 属性一个 double 类型的浮点数,跳跃表中的所有节点都**按分值从小到大来排序**
+分值:score 属性一个 double 类型的浮点数,跳跃表中的所有节点都按分值从小到大来排序
-成员对象:obj 属性是一个指针,指向一个 SDS 字符串对象。同一个跳跃表中,各个节点保存的成员对象必须是唯一的,但是多个节点保存的分值可以是相同的,分值相同的节点将按照成员对象在字典序中的大小来进行排序(从小到大)
+成员对象:obj 属性是一个指针,指向一个 SDS 字符串对象。同一个跳跃表中,各个节点保存的**成员对象必须是唯一的**,但是多个节点保存的分值可以是相同的,分值相同的节点将按照成员对象在字典序中的大小来进行排序(从小到大)
@@ -11206,7 +11164,7 @@ encoding 取值为三种:INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT6
-#### 升级降级
+#### 类型升级
整数集合添加的新元素的类型比集合现有所有元素的类型都要长时,需要先进行升级(upgrade),升级流程:
@@ -11233,7 +11191,7 @@ encoding 取值为三种:INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT6
* 节约内存:要让数组可以同时保存 int16、int32、int64 三种类型的值,可以直接使用 int64_t 类型的数组作为整数集合的底层实现,但是会造成内存浪费,整数集合可以确保升级操作只会在有需要的时候进行,尽量节省内存
-整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态
+整数集合**不支持降级操作**,一旦对数组进行了升级,编码就会一直保持升级后的状态
@@ -11251,7 +11209,7 @@ encoding 取值为三种:INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT6

-* zlbytes:uint32_t 类型 4 字节,记录整个压缩列表占用的内存字节数,在对压缩列表进行内存重分或者计算 zlend 的位置时使用
+* zlbytes:uint32_t 类型 4 字节,记录整个压缩列表占用的内存字节数,在对压缩列表进行内存重分配或者计算 zlend 的位置时使用
* zltail:uint32_t 类型 4 字节,记录压缩列表表尾节点距离起始地址有多少字节,通过这个偏移量程序无须遍历整个压缩列表就可以确定表尾节点的地址
* zllen:uint16_t 类型 2 字节,记录了压缩列表包含的节点数量,当该属性的值小于 UINT16_MAX (65535) 时,该值就是压缩列表中节点的数量;当这个值等于 UINT16_MAX 时节点的真实数量需要遍历整个压缩列表才能计算得出
* entryX:列表节点,压缩列表中的各个节点,**节点的长度由节点保存的内容决定**
@@ -11273,14 +11231,14 @@ encoding 取值为三种:INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT6

-previous_entry_length:以字节为单位记录了压缩列表中前一个节点的长度,程序可以通过指针运算,根据当前节点的起始地址来计算出前一个节点的起始地址,完成从表尾向表头遍历操作
+previous_entry_length:以字节为单位记录了压缩列表中前一个节点的长度,程序可以通过指针运算,根据当前节点的起始地址来计算出前一个节点的起始地址,完成**从表尾向表头遍历**操作
* 如果前一节点的长度小于 254 字节,该属性的长度为 1 字节,前一节点的长度就保存在这一个字节里
* 如果前一节点的长度大于等于 254 字节,该属性的长度为 5 字节,其中第一字节会被设置为 0xFE(十进制 254),之后的四个字节则用于保存前一节点的长度
encoding:记录了节点的 content 属性所保存的数据类型和长度
-* 长度为 1 字节、2 字节或者 5 字节,值的最高位为 00、01 或者 10 的是字节数组编码,数组的长度由编码除去最高两位之后的其他位记录,下划线 `_` 表示留空,而 `b`、`x` 等变量则代表实际的二进制数据
+* **长度为 1 字节、2 字节或者 5 字节**,值的最高位为 00、01 或者 10 的是字节数组编码,数组的长度由编码除去最高两位之后的其他位记录,下划线 `_` 表示留空,而 `b`、`x` 等变量则代表实际的二进制数据

@@ -11369,7 +11327,7 @@ typedef struct redisObiect {
Redis 并没有直接使用数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象,而每种对象又通过不同的编码映射到不同的底层数据结构
-Redis 自身是一个 Map,其中所有的数据都是采用 key : value 的形式存储,**键对象都是字符串对象**,而值对象有五种基本类型和三种高级类型对象
+Redis 是一个 Map 类型,其中所有的数据都是采用 key : value 的形式存储,**键对象都是字符串对象**,而值对象有五种基本类型和三种高级类型对象
@@ -11590,7 +11548,7 @@ Redis 所有操作都是**原子性**的,采用**单线程**机制,命令是
-#### 对象
+#### 实现
字符串对象的编码可以是 int、raw、embstr 三种
@@ -12127,8 +12085,8 @@ set 类型:与 hash 存储结构哈希表完全相同,只是仅存储键不
使用字典加跳跃表的优势:
-* 字典为有序集合创建了一个从成员到分值的映射,用 O(1) 复杂度查找给定成员的分值
-* 排序操作使用跳跃表完成,节省每次重新排序带来的时间成本和空间成本
+* 字典为有序集合创建了一个**从成员到分值的映射**,用 O(1) 复杂度查找给定成员的分值
+* **排序操作使用跳跃表完成**,节省每次重新排序带来的时间成本和空间成本
使用 ziplist 格式存储需要满足以下两个条件:
@@ -12137,6 +12095,11 @@ set 类型:与 hash 存储结构哈希表完全相同,只是仅存储键不
当元素比较多时,此时 ziplist 的读写效率会下降,时间复杂度是 O(n),跳表的时间复杂度是 O(logn)
+为什么用跳表而不用平衡树?
+
+* 在做范围查找的时候,跳表操作简单(前进指针或后退指针),平衡树需要回旋查找
+* 跳表比平衡树实现简单,平衡树的插入和删除操作可能引发子树的旋转调整,而跳表的插入和删除只需要修改相邻节点的指针
+
***
@@ -12391,7 +12354,7 @@ AOF:将数据的操作过程进行保存,日志形式,存储操作过程
#### 文件创建
-RDB 持久化功能所生成的 RDB 文件 是一个经过压缩的紧凑二进制文件,通过该文件可以还原生成 RDB 文件时的数据库状态,有两个 Redis 命令可以生成 RDB 文件,一个是 SAVE,另一个是 BGSAVE
+RDB 持久化功能所生成的 RDB 文件是一个经过压缩的紧凑二进制文件,通过该文件可以还原生成 RDB 文件时的数据库状态,有两个 Redis 命令可以生成 RDB 文件,一个是 SAVE,另一个是 BGSAVE
@@ -12424,7 +12387,7 @@ BGSAVE:bg 是 background,代表后台执行,命令的完成需要两个进
@@ -9763,7 +9735,7 @@ Redis 单线程也能高效的原因:
##### 多路复用
-Redis 的 I/O 多路复用程序的所有功能都是通过包装常见的 select 、epoll、 evport 和 kqueue 这些函数库来实现的,Redis在 I/O 多路复用程序的实现源码中用 #include 宏定义了相应的规则,编译时自动选择系统中**性能最高的多路复用函数**来作为底层实现
+Redis 的 I/O 多路复用程序的所有功能都是通过包装常见的 select 、epoll、 evport 和 kqueue 这些函数库来实现的,Redis 在 I/O 多路复用程序的实现源码中用 #include 宏定义了相应的规则,编译时自动选择系统中**性能最高的多路复用函数**来作为底层实现
I/O 多路复用程序监听多个套接字的 AE_READABLE 事件和 AE_WRITABLE 事件,这两类事件和套接字操作之间的对应关系如下:
@@ -9790,9 +9762,9 @@ Redis 为文件事件编写了多个处理器,这些事件处理器分别用
Redis 客户端与服务器进行连接并发送命令的整个过程:
* Redis 服务器正在运作监听套接字的 AE_READABLE 事件,关联连接应答处理器
-* 当 Redis 客户端向服务器发起连接,监听套接字将产生 AE_READABLE 事件,触发连接应答处理器执行,对客户端的连接请求进行应答,创建客户端套接字以及客户端状态,并将客户端套接字的 AE_READABLE 事件与命令请求处理器进行关联
+* 当 Redis 客户端向服务器发起连接,监听套接字将产生 AE_READABLE 事件,触发连接应答处理器执行,对客户端的连接请求进行应答,创建客户端套接字以及客户端状态,并将客户端套接字的 **AE_READABLE 事件与命令请求处理器**进行关联
* 客户端向服务器发送命令请求,客户端套接字产生 AE_READABLE 事件,引发命令请求处理器执行,读取客户端的命令内容传给相关程序去执行
-* 执行命令会产生相应的命令回复,为了将这些命令回复传送回客户端,服务器会将客户端套接字的 AE_WRITABLE 事件与命令回复处理器进行关联
+* 执行命令会产生相应的命令回复,为了将这些命令回复传送回客户端,服务器会将客户端套接字的 **AE_WRITABLE 事件与命令回复处理器**进行关联
* 当客户端尝试读取命令回复时,客户端套接字产生 AE_WRITABLE 事件,触发命令回复处理器执行,在命令回复全部写入套接字后,服务器就会解除客户端套接字的 AE_WRITABLE 事件与命令回复处理器之间的关联
@@ -9829,8 +9801,6 @@ Redis 的时间事件分为以下两类:
无序链表并不影响时间事件处理器的性能,因为正常模式下的 Redis 服务器**只使用 serverCron 一个时间事件**,在 benchmark 模式下服务器也只使用两个时间事件,所以无序链表不会影响服务器的性能,几乎可以按照一个指针处理
-服务器 → serverCron 详解该时间事件
-
***
@@ -9842,18 +9812,6 @@ Redis 的时间事件分为以下两类:
服务器中同时存在文件事件和时间事件两种事件类型,调度伪代码:
```python
-# Redis 服务器的主函数的伪代码
-def main():
- # 初始化服务器
- init_server()
-
- # 循环处理事件,直到服务器关闭
- while server_is_not_shutdown():
- aeProcessEvents()
-
- # 服务器关闭
- clean_server()
-
# 事件调度伪代码
def aeProcessEvents():
# 获取到达时间离当前时间最接近的时间事件
@@ -9997,7 +9955,7 @@ typedef struct redisClient {
客户端状态包括两类属性
* 一类是比较通用的属性,这些属性很少与特定功能相关,无论客户端执行的是什么工作,都要用到这些属性
-* 另一类是和特定功能相关的属性,比如操作数据库时用到的 db 属性和 dict id属性,执行事务时用到的 mstate 属性,以及执行 WATCH 命令时用到的 watched_keys 属性等,代码中没有列出
+* 另一类是和特定功能相关的属性,比如操作数据库时用到的 db 属性和 dict id 属性,执行事务时用到的 mstate 属性,以及执行 WATCH 命令时用到的 watched_keys 属性等,代码中没有列出
@@ -10156,7 +10114,7 @@ obuf_soft_limit_reached_time 属性记录了**输出缓冲区第一次到达软
服务器使用不同的方式来创建和关闭不同类型的客户端
-如果客户端是通过网络连接与服务器进行连接的普通客户端,那么在客户端使用 connect 函数连接到服务器时,服务器就会调用连接事件处理器为客户端创建相应的客户端状态,并将这个新的客户端状态添加到服务器状态结构 clients 链表的末尾
+如果客户端是通过网络连接与服务器进行连接的普通客户端,那么在客户端使用 connect 函数连接到服务器时,服务器就会调用连接应答处理器为客户端创建相应的客户端状态,并将这个新的客户端状态添加到服务器状态结构 clients 链表的末尾

@@ -10338,7 +10296,7 @@ struct redisCommand {
##### 基本介绍
-Redis 服务器以周期性事件的方式来运行 serverCron 函数,服务器初始化时读取配置 server.hz 的值,默认为 10,代表每秒钟执行 10 次,即每隔 100 毫秒执行一次,执行指令 info server 可以查看
+Redis 服务器以周期性事件的方式来运行 serverCron 函数,服务器初始化时读取配置 server.hz 的值,默认为 10,代表每秒钟执行 10 次,即**每隔 100 毫秒执行一次**,执行指令 info server 可以查看
serverCron 函数负责定期对自身的资源和状态进行检查和调整,从而确保服务器可以长期、稳定地运行
@@ -10507,7 +10465,7 @@ clientsCron 函数对一定数量的客户端进行以下两个检查:
* 如果客户端与服务器之间的连接巳经超时(很长一段时间客户端和服务器都没有互动),那么程序释放这个客户端
* 如果客户端在上一次执行命令请求之后,输入缓冲区的大小超过了一定的长度,那么程序会释放客户端当前的输入缓冲区,并重新创建一个默认大小的输入缓冲区,从而防止客户端的输入缓冲区耗费了过多的内存
-databasesCron 函数会对服务器中的一部分数据库进行检查,删除其中的过期键,并在有需要时 对字典进行收缩操作
+databasesCron 函数会对服务器中的一部分数据库进行检查,删除其中的过期键,并在有需要时对字典进行收缩操作
@@ -10517,7 +10475,7 @@ databasesCron 函数会对服务器中的一部分数据库进行检查,删除
##### 持久状态
-服务器状态中记录执行 BGSAVE 命令和 BGREWRITEAOF 命令的子进程的 ID,
+服务器状态中记录执行 BGSAVE 命令和 BGREWRITEAOF 命令的子进程的 ID
```c
struct redisServer {
@@ -10570,7 +10528,7 @@ serverCron 函数会检查 BGSAVE 或者 BGREWRITEAOF 命令是否正在执行
-##### cronloops
+##### 执行次数
服务器状态的 cronloops 属性记录了 serverCron 函数执行的次数
@@ -10622,7 +10580,7 @@ struct redisServer {
initServer 还进行了非常重要的设置操作:
* 为服务器设置进程信号处理器
-* 创建共享对象,包含 OK、ERR、整数 1 到 10000 的字符串对象等
+* 创建共享对象,包含 OK、ERR、**整数 1 到 10000 的字符串对象**等
* **打开服务器的监听端口**
* **为 serverCron 函数创建时间事件**, 等待服务器正式运行时执行 serverCron 函数
* 如果 AOF 持久化功能已经打开,那么打开现有的 AOF 文件,如果 AOF 文件不存在,那么创建并打开一个新的 AOF 文件 ,为 AOF 写入做好准备
@@ -10788,7 +10746,7 @@ struct sdshdr {
};
```
-SDS 遵循 C 字符串**以空字符结尾**的惯例, 保存空字符的 1 字节不计算在 len 属性,SDS 会自动为空字符分配额外的 1 字节空间和添加空字符到字符串末尾,所以空字符对于 SDS 的使用者来说是完全透明的
+SDS 遵循 C 字符串**以空字符结尾**的惯例,保存空字符的 1 字节不计算在 len 属性,SDS 会自动为空字符分配额外的 1 字节空间和添加空字符到字符串末尾,所以空字符对于 SDS 的使用者来说是完全透明的

@@ -10818,7 +10776,7 @@ SDS 遵循 C 字符串**以空字符结尾**的惯例, 保存空字符的 1
二进制安全:
* C 字符串中的字符必须符合某种编码(比如 ASCII)方式,除了字符串末尾以外其他位置不能包含空字符,否则会被误认为是字符串的结尾,所以只能保存文本数据
-* SDS 的 API 都是二进制安全的,使用字节数组 buf 保存一系列的二进制数据,使用 len 属性来判断数据的结尾,所以可以保存图片、视频、压缩文件等二进制数据
+* SDS 的 API 都是二进制安全的,使用字节数组 buf 保存一系列的二进制数据,**使用 len 属性来判断数据的结尾**,所以可以保存图片、视频、压缩文件等二进制数据
兼容 C 字符串的函数:SDS 会在为 buf 数组分配空间时多分配一个字节来保存空字符,所以可以重用一部分 C 字符串函数库的函数
@@ -10836,7 +10794,7 @@ SDS 通过未使用空间解除了字符串长度和底层数组长度之间的
内存重分配涉及复杂的算法,需要执行**系统调用**,是一个比较耗时的操作,SDS 的两种优化策略:
-* 空间预分配:当 SDS 的 API 进行修改并且需要进行空间扩展时,程序不仅会为 SDS 分配修改所必需的空间, 还会为 SDS 分配额外的未使用空间
+* 空间预分配:当 SDS 需要进行空间扩展时,程序不仅会为 SDS 分配修改所必需的空间, 还会为 SDS 分配额外的未使用空间
* 对 SDS 修改之后,SDS 的长度(len 属性)小于 1MB,程序分配和 len 属性同样大小的未使用空间,此时 len 和 free 相等
@@ -10848,7 +10806,7 @@ SDS 通过未使用空间解除了字符串长度和底层数组长度之间的
在扩展 SDS 空间前,API 会先检查 free 空间是否足够,如果足够就无需执行内存重分配,所以通过预分配策略,SDS 将连续增长 N 次字符串所需内存的重分配次数从**必定 N 次降低为最多 N 次**
-* 惰性空间释放:当 SDS 的 API 需要缩短字符串时,程序并不立即使用内存重分配来回收缩短后多出来的字节,而是使用 free 属性将这些字节的数量记录起来,并等待将来使用
+* 惰性空间释放:当 SDS 缩短字符串时,程序并不立即使用内存重分配来回收缩短后多出来的字节,而是使用 free 属性将这些字节的数量记录起来,并等待将来复用
SDS 提供了相应的 API 来真正释放 SDS 的未使用空间,所以不用担心空间惰性释放策略造成的内存浪费问题
@@ -11047,7 +11005,7 @@ load_factor = ht[0].used / ht[0].size
原因:执行该命令的过程中,Redis 需要创建当前服务器进程的子进程,而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率,通过提高执行扩展操作的负载因子,尽可能地避免在子进程存在期间进行哈希表扩展操作,可以避免不必要的内存写入操作,最大限度地节约内存
-哈希表执行收缩的条件:负载因子小于 0.1(自动执行,servreCron 中检测),缩小为字典中数据个数的 50% 左右
+哈希表执行收缩的条件:负载因子小于 0.1(自动执行,servreCron 中检测)
@@ -11063,7 +11021,7 @@ load_factor = ht[0].used / ht[0].size
* 如果执行的是扩展操作,ht[1] 的大小为第一个大于等于 $ht[0].used * 2$ 的 $2^n$
* 如果执行的是收缩操作,ht[1] 的大小为第一个大于等于 $ht[0].used$ 的 $2^n$
* 将保存在 ht[0] 中所有的键值对重新计算哈希值和索引值,迁移到 ht[1] 上
-* 当 ht[0] 包含的所有键值对都迁移到了 ht[1] 之后(ht[0]变为空表), 释放 ht[0],将 ht[1] 设置为 ht[0],并在 ht[1] 创建一个新的空白哈希表,为下一次 rehash 做准备
+* 当 ht[0] 包含的所有键值对都迁移到了 ht[1] 之后(ht[0] 变为空表),释放 ht[0],将 ht[1] 设置为 ht[0],并在 ht[1] 创建一个新的空白哈希表,为下一次 rehash 做准备
如果哈希表里保存的键值对数量很少,rehash 就可以在瞬间完成,但是如果哈希表里数据很多,那么要一次性将这些键值对全部 rehash 到 ht[1] 需要大量计算,可能会导致服务器在一段时间内停止服务
@@ -11071,8 +11029,8 @@ Redis 对 rehash 做了优化,使 rehash 的动作并不是一次性、集中
* 为 ht[1] 分配空间,此时字典同时持有 ht[0] 和 ht[1] 两个哈希表
* 在字典中维护了一个索引计数器变量 rehashidx,并将变量的值设为 0,表示 rehash 正式开始
-* 在 rehash 进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1],rehash 完成之后**将 rehashidx 属性的值增一**
-* 随着字典操作的不断执行,最终在某个时间点上 ht[0] 的所有键值对都被 rehash 至 ht[1],这时程序将 rehashidx 属性的值设为 -1,表示 rehash 操作已完成
+* 在 rehash 进行期间,每次对字典执行增删改查操作时,程序除了执行指定的操作以外,还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1],rehash 完成之后**将 rehashidx 属性的值增一**
+* 随着字典操作的不断执行,最终在某个时间点 ht[0] 的所有键值对都被 rehash 至 ht[1],将 rehashidx 属性的值设为 -1
渐进式 rehash 采用**分而治之**的方式,将 rehash 键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,从而避免了集中式 rehash 带来的庞大计算量
@@ -11145,23 +11103,23 @@ typedef struct zskiplistNode {
层:level 数组包含多个元素,每个元素包含指向其他节点的指针。根据幕次定律(power law,越大的数出现的概率越小)**随机**生成一个介于 1 和 32 之间的值(Redis5 之后最大为 64)作为 level 数组的大小,这个大小就是层的高度,节点的第一层是 level[0] = L1
-前进指针:forward 用于从表头到表尾方向正序(升序)遍历节点,遇到 NULL 停止遍历
+前进指针:forward 用于从表头到表尾方向**正序(升序)遍历节点**,遇到 NULL 停止遍历
-跨度:span 用于记录两个节点之间的距离,用来**计算排位(rank)**:
+跨度:span 用于记录两个节点之间的距离,用来计算排位(rank):
* 两个节点之间的跨度越大相距的就越远,指向 NULL 的所有前进指针的跨度都为 0
-* 在查找某个节点的过程中,将沿途访问过的所有层的跨度累计起来,结果就是目标节点在跳跃表中的排位,按照上图所示:
+* 在查找某个节点的过程中,**将沿途访问过的所有层的跨度累计起来,结果就是目标节点在跳跃表中的排位**,按照上图所示:
查找分值为 3.0 的节点,沿途经历的层:查找的过程只经过了一个层,并且层的跨度为 3,所以目标节点在跳跃表中的排位为 3
查找分值为 2.0 的节点,沿途经历的层:经过了两个跨度为 1 的节点,因此可以计算出目标节点在跳跃表中的排位为 2
-后退指针:backward 用于从表尾到表头方向逆序(降序)遍历节点
+后退指针:backward 用于从表尾到表头方向**逆序(降序)遍历节点**
-分值:score 属性一个 double 类型的浮点数,跳跃表中的所有节点都**按分值从小到大来排序**
+分值:score 属性一个 double 类型的浮点数,跳跃表中的所有节点都按分值从小到大来排序
-成员对象:obj 属性是一个指针,指向一个 SDS 字符串对象。同一个跳跃表中,各个节点保存的成员对象必须是唯一的,但是多个节点保存的分值可以是相同的,分值相同的节点将按照成员对象在字典序中的大小来进行排序(从小到大)
+成员对象:obj 属性是一个指针,指向一个 SDS 字符串对象。同一个跳跃表中,各个节点保存的**成员对象必须是唯一的**,但是多个节点保存的分值可以是相同的,分值相同的节点将按照成员对象在字典序中的大小来进行排序(从小到大)
@@ -11206,7 +11164,7 @@ encoding 取值为三种:INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT6
-#### 升级降级
+#### 类型升级
整数集合添加的新元素的类型比集合现有所有元素的类型都要长时,需要先进行升级(upgrade),升级流程:
@@ -11233,7 +11191,7 @@ encoding 取值为三种:INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT6
* 节约内存:要让数组可以同时保存 int16、int32、int64 三种类型的值,可以直接使用 int64_t 类型的数组作为整数集合的底层实现,但是会造成内存浪费,整数集合可以确保升级操作只会在有需要的时候进行,尽量节省内存
-整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态
+整数集合**不支持降级操作**,一旦对数组进行了升级,编码就会一直保持升级后的状态
@@ -11251,7 +11209,7 @@ encoding 取值为三种:INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT6

-* zlbytes:uint32_t 类型 4 字节,记录整个压缩列表占用的内存字节数,在对压缩列表进行内存重分或者计算 zlend 的位置时使用
+* zlbytes:uint32_t 类型 4 字节,记录整个压缩列表占用的内存字节数,在对压缩列表进行内存重分配或者计算 zlend 的位置时使用
* zltail:uint32_t 类型 4 字节,记录压缩列表表尾节点距离起始地址有多少字节,通过这个偏移量程序无须遍历整个压缩列表就可以确定表尾节点的地址
* zllen:uint16_t 类型 2 字节,记录了压缩列表包含的节点数量,当该属性的值小于 UINT16_MAX (65535) 时,该值就是压缩列表中节点的数量;当这个值等于 UINT16_MAX 时节点的真实数量需要遍历整个压缩列表才能计算得出
* entryX:列表节点,压缩列表中的各个节点,**节点的长度由节点保存的内容决定**
@@ -11273,14 +11231,14 @@ encoding 取值为三种:INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT6

-previous_entry_length:以字节为单位记录了压缩列表中前一个节点的长度,程序可以通过指针运算,根据当前节点的起始地址来计算出前一个节点的起始地址,完成从表尾向表头遍历操作
+previous_entry_length:以字节为单位记录了压缩列表中前一个节点的长度,程序可以通过指针运算,根据当前节点的起始地址来计算出前一个节点的起始地址,完成**从表尾向表头遍历**操作
* 如果前一节点的长度小于 254 字节,该属性的长度为 1 字节,前一节点的长度就保存在这一个字节里
* 如果前一节点的长度大于等于 254 字节,该属性的长度为 5 字节,其中第一字节会被设置为 0xFE(十进制 254),之后的四个字节则用于保存前一节点的长度
encoding:记录了节点的 content 属性所保存的数据类型和长度
-* 长度为 1 字节、2 字节或者 5 字节,值的最高位为 00、01 或者 10 的是字节数组编码,数组的长度由编码除去最高两位之后的其他位记录,下划线 `_` 表示留空,而 `b`、`x` 等变量则代表实际的二进制数据
+* **长度为 1 字节、2 字节或者 5 字节**,值的最高位为 00、01 或者 10 的是字节数组编码,数组的长度由编码除去最高两位之后的其他位记录,下划线 `_` 表示留空,而 `b`、`x` 等变量则代表实际的二进制数据

@@ -11369,7 +11327,7 @@ typedef struct redisObiect {
Redis 并没有直接使用数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象,而每种对象又通过不同的编码映射到不同的底层数据结构
-Redis 自身是一个 Map,其中所有的数据都是采用 key : value 的形式存储,**键对象都是字符串对象**,而值对象有五种基本类型和三种高级类型对象
+Redis 是一个 Map 类型,其中所有的数据都是采用 key : value 的形式存储,**键对象都是字符串对象**,而值对象有五种基本类型和三种高级类型对象

@@ -11590,7 +11548,7 @@ Redis 所有操作都是**原子性**的,采用**单线程**机制,命令是
-#### 对象
+#### 实现
字符串对象的编码可以是 int、raw、embstr 三种
@@ -12127,8 +12085,8 @@ set 类型:与 hash 存储结构哈希表完全相同,只是仅存储键不
使用字典加跳跃表的优势:
-* 字典为有序集合创建了一个从成员到分值的映射,用 O(1) 复杂度查找给定成员的分值
-* 排序操作使用跳跃表完成,节省每次重新排序带来的时间成本和空间成本
+* 字典为有序集合创建了一个**从成员到分值的映射**,用 O(1) 复杂度查找给定成员的分值
+* **排序操作使用跳跃表完成**,节省每次重新排序带来的时间成本和空间成本
使用 ziplist 格式存储需要满足以下两个条件:
@@ -12137,6 +12095,11 @@ set 类型:与 hash 存储结构哈希表完全相同,只是仅存储键不
当元素比较多时,此时 ziplist 的读写效率会下降,时间复杂度是 O(n),跳表的时间复杂度是 O(logn)
+为什么用跳表而不用平衡树?
+
+* 在做范围查找的时候,跳表操作简单(前进指针或后退指针),平衡树需要回旋查找
+* 跳表比平衡树实现简单,平衡树的插入和删除操作可能引发子树的旋转调整,而跳表的插入和删除只需要修改相邻节点的指针
+
***
@@ -12391,7 +12354,7 @@ AOF:将数据的操作过程进行保存,日志形式,存储操作过程
#### 文件创建
-RDB 持久化功能所生成的 RDB 文件 是一个经过压缩的紧凑二进制文件,通过该文件可以还原生成 RDB 文件时的数据库状态,有两个 Redis 命令可以生成 RDB 文件,一个是 SAVE,另一个是 BGSAVE
+RDB 持久化功能所生成的 RDB 文件是一个经过压缩的紧凑二进制文件,通过该文件可以还原生成 RDB 文件时的数据库状态,有两个 Redis 命令可以生成 RDB 文件,一个是 SAVE,另一个是 BGSAVE
@@ -12424,7 +12387,7 @@ BGSAVE:bg 是 background,代表后台执行,命令的完成需要两个进
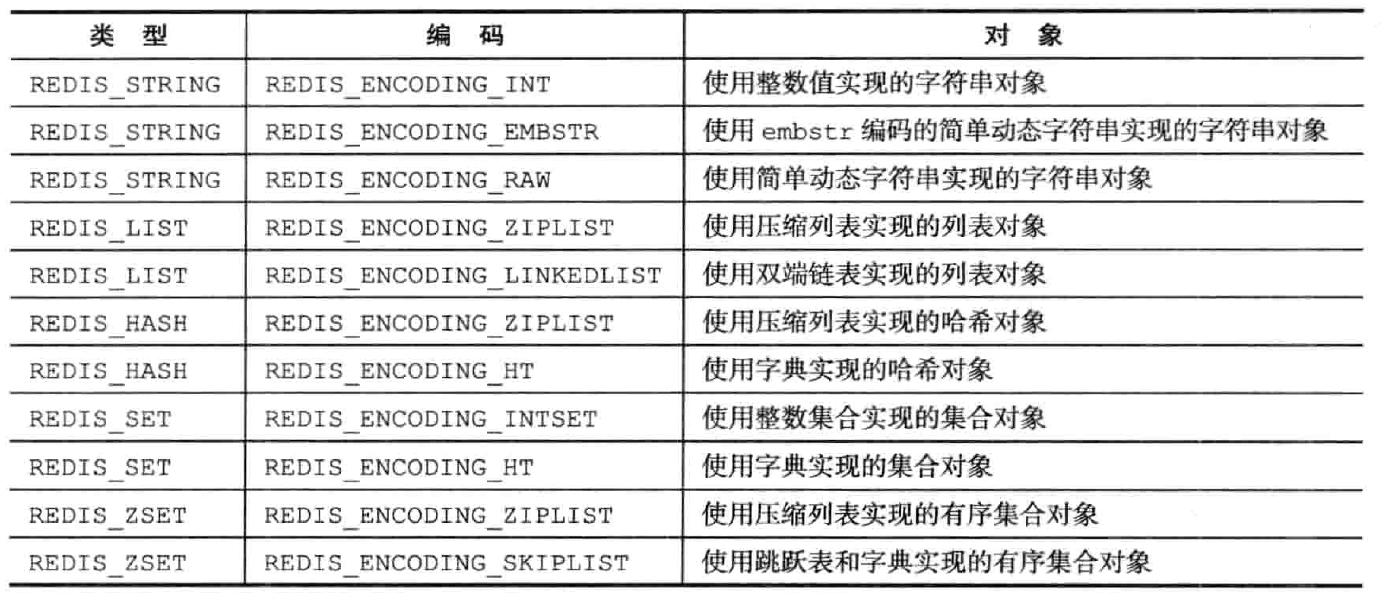
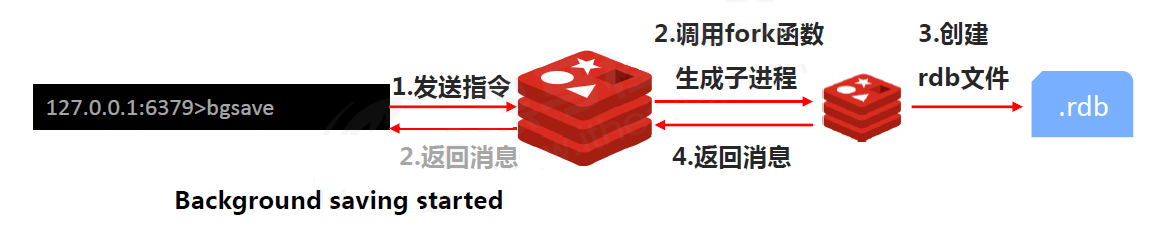 -流程:客户端发出 BGSAVE 指令,Redis 服务器使用 fork 函数创建一个子进程,然后响应后台已经开始执行的信息给客户端。子进程会去执行持久化的操作,持久化过程是先将数据写入到一个临时文件中,持久化操作结束再用这个临时文件**替换**上次持久化的文件
+流程:客户端发出 BGSAVE 指令,Redis 服务器使用 fork 函数创建一个子进程,然后响应后台已经开始执行的信息给客户端。子进程会异步执行持久化的操作,持久化过程是先将数据写入到一个临时文件中,持久化操作结束再用这个临时文件**替换**上次持久化的文件
```python
# 创建子进程
@@ -12459,7 +12422,7 @@ rdbchecksum yes|no
* SAVE 命令会被服务器拒绝,服务器禁止 SAVE 和 BGSAVE 命令同时执行是为了避免父进程(服务器进程)和子进程同时执行两个 rdbSave 调用,产生竞争条件
* BGSAVE 命令也会被服务器拒绝,也会产生竞争条件
* BGREWRITEAOF 和 BGSAVE 两个命令不能同时执行
- * 如果 BGSAVE 命令正在执行,那么 BGREWRITEAOF 命令会被延迟到 BGSAVE 命令执行完毕之后执行
+ * 如果 BGSAVE 命令正在执行,那么 BGREWRITEAOF 命令会被**延迟**到 BGSAVE 命令执行完毕之后执行
* 如果 BGREWRITEAOF 命令正在执行,那么 BGSAVE 命令会被服务器拒绝
@@ -12679,7 +12642,7 @@ struct redisServer {
##### 文件写入
-服务器在处理文件事件时可能会执行写命令,追加一些内容到 aof_buf 缓冲区里,所以服务器每次结束一个事件循环之前,就会执行 flushAppendOnlyFile 函数,判断是否需要**将 aof_buf 缓冲区中的内容写入和保存到 AOF 文件**里
+服务器在处理文件事件时会执行**写命令,追加一些内容到 aof_buf 缓冲区**里,所以服务器每次结束一个事件循环之前,就会执行 flushAppendOnlyFile 函数,判断是否需要**将 aof_buf 缓冲区中的内容写入和保存到 AOF 文件**里
flushAppendOnlyFile 函数的行为由服务器配置的 appendfsync 选项的值来决定
@@ -12692,12 +12655,12 @@ appendfsync always|everysec|no #AOF写数据策略:默认为everysec
特点:安全性最高,数据零误差,但是性能较低,不建议使用
-- everysec:先将 aof_buf 缓冲区中的内容写入到 AOF 文件,判断上次同步 AOF 文件的时间距离现在超过一秒钟,再次对 AOF 文件进行同步,这个同步操作是由一个(子)线程专门负责执行的
+- everysec:先将 aof_buf 缓冲区中的内容写入到操作系统缓存,判断上次同步 AOF 文件的时间距离现在超过一秒钟,再次进行同步 fsync,这个同步操作是由一个(子)线程专门负责执行的
特点:在系统突然宕机的情况下丢失 1 秒内的数据,准确性较高,性能较高,建议使用,也是默认配置
-- no:将 aof_buf 缓冲区中的内容写入到 AOF 文件,但并不对 AOF 文件进行同步,何时同步由操作系统来决定
+- no:将 aof_buf 缓冲区中的内容写入到操作系统缓存,但并不进行同步,何时同步由操作系统来决定
特点:**整体不可控**,服务器宕机会丢失上次同步 AOF 后的所有写指令
@@ -12760,8 +12723,6 @@ Redis 读取 AOF 文件并还原数据库状态的步骤:
##### 重写策略
-随着命令不断写入 AOF,文件会越来越大,很可能对 Redis 服务器甚至整个宿主计算机造成影响,为了解决这个问题 Redis 引入了 AOF 重写机制压缩文件体积
-
AOF 重写:读取服务器当前的数据库状态,**生成新 AOF 文件来替换旧 AOF 文件**,不会对现有的 AOF 文件进行任何读取、分析或者写入操作,而是直接原子替换。新 AOF 文件不会包含任何浪费空间的冗余命令,所以体积通常会比旧 AOF 文件小得多
AOF 重写规则:
@@ -12797,7 +12758,7 @@ bgrewriteaof
* 子进程进行 AOF 重写期间,服务器进程(父进程)可以继续处理命令请求
-* 子进程带有服务器进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下, 保证数据的安全性
+* 子进程带有服务器进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下, 保证数据安全性

@@ -12806,7 +12767,7 @@ bgrewriteaof
工作流程:
* Redis 服务器执行完一个写命令,会同时将该命令追加到 AOF 缓冲区和 AOF 重写缓冲区(从创建子进程后才开始写入)
-* 当子进程完成 AOF 重写工作之后,会向父进程发送一个信号,父进程在接到该信号之后, 会调用一个信号处理函数,该函数执行时会**对服务器进程(父进程)造成阻塞**(影响很小),主要工作:
+* 当子进程完成 AOF 重写工作之后,会向父进程发送一个信号,父进程在接到该信号之后, 会调用一个信号处理函数,该函数执行时会**对服务器进程(父进程)造成阻塞**(影响很小,类似 JVM STW),主要工作:
* 将 AOF 重写缓冲区中的所有内容写入到新 AOF 文件中, 这时新 AOF 文件所保存的状态将和服务器当前的数据库状态一致
* 对新的 AOF 文件进行改名,**原子地(atomic)覆盖**现有的 AOF 文件,完成新旧两个 AOF 文件的替换
@@ -12863,7 +12824,7 @@ RDB 的特点
AOF 特点:
-* AOF 的优点:数据持久化有较好的实时性,通过 AOF 重写可以降低文件的体积
+* AOF 的优点:数据持久化有**较好的实时性**,通过 AOF 重写可以降低文件的体积
* AOF 的缺点:文件较大时恢复较慢
AOF 和 RDB 同时开启,系统默认取 AOF 的数据(数据不会存在丢失)
@@ -12992,7 +12953,7 @@ int main(void)
-流程:客户端发出 BGSAVE 指令,Redis 服务器使用 fork 函数创建一个子进程,然后响应后台已经开始执行的信息给客户端。子进程会去执行持久化的操作,持久化过程是先将数据写入到一个临时文件中,持久化操作结束再用这个临时文件**替换**上次持久化的文件
+流程:客户端发出 BGSAVE 指令,Redis 服务器使用 fork 函数创建一个子进程,然后响应后台已经开始执行的信息给客户端。子进程会异步执行持久化的操作,持久化过程是先将数据写入到一个临时文件中,持久化操作结束再用这个临时文件**替换**上次持久化的文件
```python
# 创建子进程
@@ -12459,7 +12422,7 @@ rdbchecksum yes|no
* SAVE 命令会被服务器拒绝,服务器禁止 SAVE 和 BGSAVE 命令同时执行是为了避免父进程(服务器进程)和子进程同时执行两个 rdbSave 调用,产生竞争条件
* BGSAVE 命令也会被服务器拒绝,也会产生竞争条件
* BGREWRITEAOF 和 BGSAVE 两个命令不能同时执行
- * 如果 BGSAVE 命令正在执行,那么 BGREWRITEAOF 命令会被延迟到 BGSAVE 命令执行完毕之后执行
+ * 如果 BGSAVE 命令正在执行,那么 BGREWRITEAOF 命令会被**延迟**到 BGSAVE 命令执行完毕之后执行
* 如果 BGREWRITEAOF 命令正在执行,那么 BGSAVE 命令会被服务器拒绝
@@ -12679,7 +12642,7 @@ struct redisServer {
##### 文件写入
-服务器在处理文件事件时可能会执行写命令,追加一些内容到 aof_buf 缓冲区里,所以服务器每次结束一个事件循环之前,就会执行 flushAppendOnlyFile 函数,判断是否需要**将 aof_buf 缓冲区中的内容写入和保存到 AOF 文件**里
+服务器在处理文件事件时会执行**写命令,追加一些内容到 aof_buf 缓冲区**里,所以服务器每次结束一个事件循环之前,就会执行 flushAppendOnlyFile 函数,判断是否需要**将 aof_buf 缓冲区中的内容写入和保存到 AOF 文件**里
flushAppendOnlyFile 函数的行为由服务器配置的 appendfsync 选项的值来决定
@@ -12692,12 +12655,12 @@ appendfsync always|everysec|no #AOF写数据策略:默认为everysec
特点:安全性最高,数据零误差,但是性能较低,不建议使用
-- everysec:先将 aof_buf 缓冲区中的内容写入到 AOF 文件,判断上次同步 AOF 文件的时间距离现在超过一秒钟,再次对 AOF 文件进行同步,这个同步操作是由一个(子)线程专门负责执行的
+- everysec:先将 aof_buf 缓冲区中的内容写入到操作系统缓存,判断上次同步 AOF 文件的时间距离现在超过一秒钟,再次进行同步 fsync,这个同步操作是由一个(子)线程专门负责执行的
特点:在系统突然宕机的情况下丢失 1 秒内的数据,准确性较高,性能较高,建议使用,也是默认配置
-- no:将 aof_buf 缓冲区中的内容写入到 AOF 文件,但并不对 AOF 文件进行同步,何时同步由操作系统来决定
+- no:将 aof_buf 缓冲区中的内容写入到操作系统缓存,但并不进行同步,何时同步由操作系统来决定
特点:**整体不可控**,服务器宕机会丢失上次同步 AOF 后的所有写指令
@@ -12760,8 +12723,6 @@ Redis 读取 AOF 文件并还原数据库状态的步骤:
##### 重写策略
-随着命令不断写入 AOF,文件会越来越大,很可能对 Redis 服务器甚至整个宿主计算机造成影响,为了解决这个问题 Redis 引入了 AOF 重写机制压缩文件体积
-
AOF 重写:读取服务器当前的数据库状态,**生成新 AOF 文件来替换旧 AOF 文件**,不会对现有的 AOF 文件进行任何读取、分析或者写入操作,而是直接原子替换。新 AOF 文件不会包含任何浪费空间的冗余命令,所以体积通常会比旧 AOF 文件小得多
AOF 重写规则:
@@ -12797,7 +12758,7 @@ bgrewriteaof
* 子进程进行 AOF 重写期间,服务器进程(父进程)可以继续处理命令请求
-* 子进程带有服务器进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下, 保证数据的安全性
+* 子进程带有服务器进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下, 保证数据安全性

@@ -12806,7 +12767,7 @@ bgrewriteaof
工作流程:
* Redis 服务器执行完一个写命令,会同时将该命令追加到 AOF 缓冲区和 AOF 重写缓冲区(从创建子进程后才开始写入)
-* 当子进程完成 AOF 重写工作之后,会向父进程发送一个信号,父进程在接到该信号之后, 会调用一个信号处理函数,该函数执行时会**对服务器进程(父进程)造成阻塞**(影响很小),主要工作:
+* 当子进程完成 AOF 重写工作之后,会向父进程发送一个信号,父进程在接到该信号之后, 会调用一个信号处理函数,该函数执行时会**对服务器进程(父进程)造成阻塞**(影响很小,类似 JVM STW),主要工作:
* 将 AOF 重写缓冲区中的所有内容写入到新 AOF 文件中, 这时新 AOF 文件所保存的状态将和服务器当前的数据库状态一致
* 对新的 AOF 文件进行改名,**原子地(atomic)覆盖**现有的 AOF 文件,完成新旧两个 AOF 文件的替换
@@ -12863,7 +12824,7 @@ RDB 的特点
AOF 特点:
-* AOF 的优点:数据持久化有较好的实时性,通过 AOF 重写可以降低文件的体积
+* AOF 的优点:数据持久化有**较好的实时性**,通过 AOF 重写可以降低文件的体积
* AOF 的缺点:文件较大时恢复较慢
AOF 和 RDB 同时开启,系统默认取 AOF 的数据(数据不会存在丢失)
@@ -12992,7 +12953,7 @@ int main(void)
 -在 p3224 和 p3225 执行完第二个循环后,main 函数退出,进程死亡。所以 p3226,p3227 就没有父进程了,成为孤儿进程,所以 p3226 和 p3227 的父进程就被置为 ID 为 1的 init 进程(笔记 Tool → Linux → 进程管理详解)
+在 p3224 和 p3225 执行完第二个循环后,main 函数退出,进程死亡。所以 p3226,p3227 就没有父进程了,成为孤儿进程,所以 p3226 和 p3227 的父进程就被置为 ID 为 1 的 init 进程(笔记 Tool → Linux → 进程管理详解)
参考文章:https://blog.csdn.net/love_gaohz/article/details/41727415
@@ -13197,7 +13158,7 @@ Redis 不支持事务回滚机制(rollback),即使事务队列中的某个
-在 p3224 和 p3225 执行完第二个循环后,main 函数退出,进程死亡。所以 p3226,p3227 就没有父进程了,成为孤儿进程,所以 p3226 和 p3227 的父进程就被置为 ID 为 1的 init 进程(笔记 Tool → Linux → 进程管理详解)
+在 p3224 和 p3225 执行完第二个循环后,main 函数退出,进程死亡。所以 p3226,p3227 就没有父进程了,成为孤儿进程,所以 p3226 和 p3227 的父进程就被置为 ID 为 1 的 init 进程(笔记 Tool → Linux → 进程管理详解)
参考文章:https://blog.csdn.net/love_gaohz/article/details/41727415
@@ -13197,7 +13158,7 @@ Redis 不支持事务回滚机制(rollback),即使事务队列中的某个
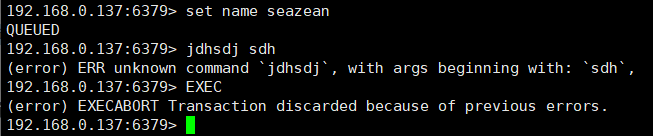 -* 执行错误:命令执行出现错误,例如对字符串进行 incr 操作,食物中正确的命令会被执行,运行错误的命令不会被执行
+* 执行错误:命令执行出现错误,例如对字符串进行 incr 操作,事务中正确的命令会被执行,运行错误的命令不会被执行
-* 执行错误:命令执行出现错误,例如对字符串进行 incr 操作,食物中正确的命令会被执行,运行错误的命令不会被执行
+* 执行错误:命令执行出现错误,例如对字符串进行 incr 操作,事务中正确的命令会被执行,运行错误的命令不会被执行
 @@ -13310,7 +13271,7 @@ Redis 服务器创建并修改 Lua 环境的整个过程:
* 创建 redis.pcall 函数的错误报告辅助函数 `_redis_err_handler `,这个函数可以打印出错代码的来源和发生错误的行数
-* 对 Lua环境中的全局环境进行保护,确保传入服务器的脚本不会因忘记使用 local 关键字,而将额外的全局变量添加到 Lua 环境
+* 对 Lua 环境中的全局环境进行保护,确保传入服务器的脚本不会因忘记使用 local 关键字,而将额外的全局变量添加到 Lua 环境
* 将完成修改的 Lua 环境保存到服务器状态的 lua 属性中,等待执行服务器传来的 Lua 脚本
@@ -13409,7 +13370,7 @@ EVAL 命令第二步是将客户端传入的脚本保存到服务器的 lua_scri
EVAL 命令第三步是执行脚本函数
-* 将 EVAL 命令中传入的**键名(key name)参数和脚本参数**分别保存到 KEYS 数组和 ARGV 数组,将这两个数组作为**全局变量**传入到 Lua 环境里
+* 将 EVAL 命令中传入的**键名参数和脚本参数**分别保存到 KEYS 数组和 ARGV 数组,将这两个数组作为**全局变量**传入到 Lua 环境
* 为 Lua 环境装载超时处理钩子(hook),这个钩子可以在脚本出现超时运行情况时,让客户端通过 `SCRIPT KILL` 命令停止脚本,或者通过 SHUTDOWN 命令直接关闭服务器
因为 Redis 是单线程的执行命令,当 Lua 脚本阻塞时需要兜底策略,可以中断执行
@@ -13477,8 +13438,6 @@ Redis 复制 EVAL、SCRIPT FLUSH、SCRIPT LOAD 三个命令的方法和复制普
-
-
***
@@ -13536,7 +13495,7 @@ Redis 分布式锁的基本使用,悲观锁
`NX`:只在键不存在时,才对键进行设置操作,`SET key value NX` 效果等同于 `SETNX key value`
- `XX` :只在键已经存在时,才对键进行设置操作
+ `XX`:只在键已经存在时,才对键进行设置操作
`EX`:设置键 key 的过期时间,单位时秒
@@ -13557,7 +13516,7 @@ Redis 分布式锁的基本使用,悲观锁
PEXPIRE lock-key milliseconds
```
- 通过 EXPIRE 设置过期时间缺乏原子性,如果在 SETNX 和 EXPIRE 之间出现异常,锁也无法释放
+ 通过 EXPIRE 设置过期时间缺乏原子性,如果在 SETNX 和 EXPIRE 之间出现异常,锁也无法释放
* 在 SET 时指定过期时间,保证原子性
@@ -13656,9 +13615,10 @@ end
超时释放:锁超时释放可以避免死锁,但如果是业务执行耗时较长,需要进行锁续时,防止业务未执行完提前释放锁
-看门狗 watchDog 机制:
+看门狗 Watch Dog 机制:
* 获取锁成功后,提交周期任务,每隔一段时间(Redisson 中默认为过期时间 / 3),重置一次超时时间
+* 如果服务宕机,Watch Dog 机制线程就停止,就不会再延长 key 的过期时间
* 释放锁后,终止周期任务
@@ -13673,7 +13633,7 @@ end
主从一致性:集群模式下,主从同步存在延迟,当加锁后主服务器宕机时,从服务器还没同步主服务器中的锁数据,此时从服务器升级为主服务器,其他线程又可以获取到锁
-将服务器升级为多主多从,:
+将服务器升级为多主多从:
* 获取锁需要从所有主服务器 SET 成功才算获取成功
* 某个 master 宕机,slave 还没有同步锁数据就升级为 master,其他线程尝试加锁会加锁失败,因为其他 master 上已经存在该锁
@@ -13705,7 +13665,7 @@ end
主从复制的特点:
-* **薪火相传**:一个 slave 可以是下一个 slave 的 master,slave 同样可以接收其他 slave 的连接和同步请求,那么该 slave 作为了链条中下一个的 master, 可以有效减轻 master 的写压力,去中心化降低风险
+* **薪火相传**:一个 slave 可以是下一个 slave 的 master,slave 同样可以接收其他 slave 的连接和同步请求,那么该 slave 作为了链条中下一个的 master,可以有效减轻 master 的写压力,去中心化降低风险
注意:主机挂了,从机还是从机,无法写数据了
@@ -14047,7 +14007,7 @@ PSYNC 命令的调用方法有两种
#### 心跳机制
-心跳机制:进入命令传播阶段,从服务器默认会以每秒一次的频率,向主服务器发送命令:`REPLCONF ACK `,re_offset 是从服务器当前的复制偏移量
+心跳机制:进入命令传播阶段,**从服务器**默认会以每秒一次的频率,**向主服务器发送命令**:`REPLCONF ACK `,replication_offset 是从服务器当前的复制偏移量
心跳的作用:
@@ -14086,16 +14046,19 @@ slavel: ip=127.0.0.1,port=22222,state=online,offset=456,lag=3 # 3秒之前发送
#### 配置选项
-Redis 的 min-slaves-to-write 和 min-slaves-max-lag 两个选项可以防止主服务器在**不安全的情况下**执行写命令
+Redis 的 min-slaves-to-write 和 min-slaves-max-lag 两个选项可以防止主服务器在**不安全的情况下**拒绝执行写命令
比如向主服务器设置:
+* min-slaves-to-write:主库最少有 N 个健康的从库存活才能执行写命令,没有足够的从库直接拒绝写入
+* min-slaves-max-lag:从库和主库进行数据复制时的 ACK 消息延迟的最大时间
+
```sh
min-slaves-to-write 5
min-slaves-max-lag 10
```
-那么在从服务器的数最少于 5 个,或者 5 个从服务器的延迟(lag)值都大于或等于10 秒时,主服务器将拒绝执行写命令
+那么在从服务器的数少于 5 个,或者 5 个从服务器的延迟(lag)值都大于或等于10 秒时,主服务器将拒绝执行写命令
@@ -14150,7 +14113,7 @@ master 的 CPU 占用过高或 slave 频繁断开连接
* 出现的原因:
* slave 每 1 秒发送 REPLCONF ACK 命令到 master
- * 当 slave 接到了慢查询时(keys * ,hgetall等),会大量占用 CPU 性能
+ * 当 slave 接到了慢查询时(keys * ,hgetall 等),会大量占用 CPU 性能
* master 每 1 秒调用复制定时函数 replicationCron(),比对 slave 发现长时间没有进行响应
最终导致 master 各种资源(输出缓冲区、带宽、连接等)被严重占用
@@ -14314,7 +14277,7 @@ Sentinel 本质上只是一个运行在特殊模式下的 Redis 服务器,当
#### 代码替换
-将一部分普通 Redis服务器使用的代码替换成 Sentinel 专用代码
+将一部分普通 Redis 服务器使用的代码替换成 Sentinel 专用代码
Redis 服务器端口:
@@ -14358,7 +14321,7 @@ struct sentinelState {
// 当前纪元,用于实现故障转移
uint64_t current_epoch;
- // 保存了所有被这个sentinel监视的主服务器
+ // 【保存了所有被这个sentinel监视的主服务器】
dict *masters;
// 是否进入了 TILT 模式
@@ -14475,10 +14438,10 @@ typedef struct sentinelAddr {
##### 主服务器
-Sentinel 默认会以每十秒一次的频率,通过命令连接向被监视的主服务器发送 INFO 命令,来获取主服务器的当前信息
+Sentinel 默认会以每十秒一次的频率,通过命令连接向被监视的主服务器发送 INFO 命令,来获取主服务器的信息
* 一部分是主服务器本身的信息,包括 runid 域记录的服务器运行 ID,以及 role 域记录的服务器角色
-* 另一部分是服务器属下所有从服务器的信息,每个从服务器都由一个 slave 字符串开头的行记录,根据这些 IP 地址和端口号,Sentinel 无须用户提供从服务器的地址信息,就可以自动发现从服务器
+* 另一部分是服务器属下所有从服务器的信息,每个从服务器都由一个 slave 字符串开头的行记录,根据这些 IP 地址和端口号,Sentinel 无须用户提供从服务器的地址信息,就可以**自动发现从服务器**
```sh
# Server
@@ -14507,7 +14470,7 @@ slave1: ip=l27.0.0.1, port=22222, state=online, offset=22, lag=0
##### 从服务器
-当 Sentinel 发现主服务器有新的从服务器出现时,会为这个新的从服务器创建相应的实例结构, 还会创建到从服务器的命令连接和订阅连接,所以 Sentinel 对所有的从服务器之间都可以进行命令操作
+当 Sentinel 发现主服务器有新的从服务器出现时,会为这个新的从服务器创建相应的实例结构,还会**创建到从服务器的命令连接和订阅连接**,所以 Sentinel 对所有的从服务器之间都可以进行命令操作
Sentinel 默认会以每十秒一次的频率,向从服务器发送 INFO 命令:
@@ -14574,26 +14537,13 @@ SUBSCRIBE _sentinel_:hello
* 如果信息中记录的 Sentinel 运行 ID 与自己的相同,不做进一步处理
* 如果不同,将根据信息中的各个参数,对相应主服务器的实例结构进行更新
-对于监视同一个服务器的多个 Sentinel 来说,**一个 Sentinel 发送的信息会被其他 Sentinel 接收到**,这些信息会被用于更新其他 Sentinel 对发送信息 Sentinel 的认知,也会被用于更新其他 Sentinel 对被监视的服务器的认知
-
-哨兵实例之间可以相互发现,要归功于 Redis 提供发布订阅机制
-
-
-
-***
-
-
-
-##### 更新字典
-
Sentinel 为主服务器创建的实例结构的 sentinels 字典保存所有同样监视这个**主服务器的 Sentinel 信息**(包括 Sentinel 自己),字典的键是 Sentinel 的名字,格式为 `ip:port`,值是键所对应 Sentinel 的实例结构
-当 Sentinel 接收到其他 Sentinel 发来的信息时(发送信息的为源 Sentinel,接收信息的为目标 Sentinel),目标 Sentinel 会分析提取参数,在自己的 Sentinel 状态 sentinelState.masters 中查找相应的主服务器实例结构,检查主服务器实例结构的 sentinels 字典中,源 Sentinel 的实例结构是否存在
+监视同一个服务器的 Sentinel 订阅的频道相同,Sentinel 发送的信息会被其他 Sentinel 接收到(发送信息的为源 Sentinel,接收信息的为目标 Sentinel),目标 Sentinel 在自己的 sentinelState.masters 中查找源 Sentinel 服务器的实例结构进行添加或更新
-* 如果源 Sentinel 的实例结构存在,那么对源 Sentinel 的实例结构进行更新
-* 如果源 Sentinel 的实例结构不存在,说明源 Sentinel 是刚开始监视主服务器,目标 Sentinel 会为源 Sentinel 创建一个新的实例结构,并将这个结构添加到 sentinels 字典里面
+因为 Sentinel 可以接收到的频道信息来感知其他 Sentinel 的存在,并通过发送频道信息来让其他 Sentinel 知道自己的存在,所以用户在使用 Sentinel 时并不需要提供各个 Sentinel 的地址信息,**监视同一个主服务器的多个 Sentinel 可以相互发现对方**
-因为 Sentinel 可以接收到的频道信息来获知其他 Sentinel 的存在,并通过发送频道信息来让其他 Sentinel 知道自己的存在,所以用户在使用 Sentinel 时并不需要提供各个 Sentinel 的地址信息,**监视同一个主服务器的多个 Sentinel 可以自动发现对方**
+哨兵实例之间可以相互发现,要归功于 Redis 提供发布订阅机制
@@ -14664,7 +14614,7 @@ SENTINEL is-master-down-by-addr
源 Sentinel 将统计其他 Sentinel 同意主服务器已下线的数量,当这一数量达到配置指定的判断客观下线所需的数量(quorum)时,Sentinel 会将主服务器对应实例结构 flags 属性的 SRI_O_DOWN 标识打开,代表客观下线,并对主服务器执行故障转移操作
-注意:不同 Sentinel 判断客观下线的条件可能不同,因为载入的配置文件中的属性(quorum)可能不同
+注意:**不同 Sentinel 判断客观下线的条件可能不同**,因为载入的配置文件中的属性 quorum 可能不同
@@ -14674,7 +14624,7 @@ SENTINEL is-master-down-by-addr
### 领头选举
-主服务器被判断为客观下线时,监视这个主服务器的各个 Sentinel 会进行协商,选举出一个领头 Sentinel 对下线服务器执行故障转移
+主服务器被判断为客观下线时,**监视该主服务器的各个 Sentinel 会进行协商**,选举出一个领头 Sentinel 对下线服务器执行故障转移
Redis 选举领头 Sentinel 的规则:
@@ -14683,7 +14633,7 @@ Redis 选举领头 Sentinel 的规则:
* 在一个配置纪元里,所有 Sentinel 都只有一次将某个 Sentinel 设置为局部领头 Sentinel 的机会,并且局部领头一旦设置,在这个配置纪元里就不能再更改
* Sentinel 设置局部领头 Sentinel 的规则是先到先得,最先向目标 Sentinel 发送设置要求的源 Sentinel 将成为目标 Sentinel 的局部领头 Sentinel,之后接收到的所有设置要求都会被目标 Sentinel 拒绝
-* 领头 Sentinel 的产生需要半数以上 Sentinel 的支持,并且每个 Sentinel 只有一票,所以一个配置纪元只会出现一个领头 Sentinel,比如 10 个 Sentinel 的系统中,至少需要 `10/2 + 1 = 6` 票
+* 领头 Sentinel 的产生**需要半数以上 Sentinel 的支持**,并且每个 Sentinel 只有一票,所以一个配置纪元只会出现一个领头 Sentinel,比如 10 个 Sentinel 的系统中,至少需要 `10/2 + 1 = 6` 票
选举过程:
@@ -14691,7 +14641,7 @@ Redis 选举领头 Sentinel 的规则:
* 目标 Sentinel 接受命令处理完成后,将返回一条命令回复,回复中的 leader_runid 和 leader_epoch 参数分别记录了目标 Sentinel 的局部领头 Sentinel 的运行 ID 和配置纪元
* 源 Sentinel 接收目标 Sentinel 命令回复之后,会判断 leader_epoch 是否和自己的相同,相同就继续判断 leader_runid 是否和自己的运行 ID 一致,成立表示目标 Sentinel 将源 Sentinel 设置成了局部领头 Sentinel,即获得一票
* 如果某个 Sentinel 被半数以上的 Sentinel 设置成了局部领头 Sentinel,那么这个 Sentinel 成为领头 Sentinel
-* 如果在给定时限内,没有一个 Sentinel 被选举为领头 Sentinel,那么各个 Sentinel 将在一段时间后再次选举,直到选出领头
+* 如果在给定时限内,没有一个 Sentinel 被选举为领头 Sentinel,那么各个 Sentinel 将在一段时间后**再次选举**,直到选出领头
* 每次进行领头 Sentinel 选举之后,不论选举是否成功,所有 Sentinel 的配置纪元(configuration epoch)都要自增一次
Sentinel 集群至少 3 个节点的原因:
@@ -14699,7 +14649,10 @@ Sentinel 集群至少 3 个节点的原因:
* 如果 Sentinel 集群只有 2 个 Sentinel 节点,则领头选举需要 `2/2 + 1 = 2` 票,如果一个节点挂了,那就永远选不出领头
* Sentinel 集群允许 1 个 Sentinel 节点故障则需要 3 个节点的集群,允许 2 个节点故障则需要 5 个节点集群
+**如何获取哨兵节点的半数数量**?
+* 客观下线是通过配置文件获取的数量,达到 quorum 就客观下线
+* 哨兵数量是通过主节点是实例结构中,保存着监视该主节点的所有哨兵信息,从而获取得到
@@ -14798,7 +14751,8 @@ typedef struct clusterState {
// 集群当前的状态,是在线还是下线
int state;
- // 集群中至少处理着一个槽的节点的数量,为0表示集群目前没有任何节点在处理槽
+ // 集群中至少处理着一个槽的(主)节点的数量,为0表示集群目前没有任何节点在处理槽
+ // 【选举时投票数量超过半数,从这里获取的】
int size;
// 集群节点名单(包括 myself 节点),字典的键为节点的名字,字典的值为节点对应的clusterNode结构
@@ -14894,7 +14848,7 @@ CLUSTER MEET
#### 基本操作
-Redis 集群通过分片的方式来保存数据库中的键值对,集群的整个数据库被分为16384 个槽(slot),数据库中的每个键都属于 16384 个槽中的一个,集群中的每个节点可以处理 0 个或最多 16384 个槽(**每个主节点存储的数据并不一样**)
+Redis 集群通过分片的方式来保存数据库中的键值对,集群的整个数据库被分为 16384 个槽(slot),数据库中的每个键都属于 16384 个槽中的一个,集群中的每个节点可以处理 0 个或最多 16384 个槽(**每个主节点存储的数据并不一样**)
* 当数据库中的 16384 个槽都有节点在处理时,集群处于上线状态(ok)
* 如果数据库中有任何一个槽得到处理,那么集群处于下线状态(fail)
@@ -14979,7 +14933,7 @@ typedef struct clusterState {
#### 集群数据
-集群节点保存键值对以及键值对过期时间的方式,与单机 Redis 服务器保存键值对以及键值对过期时间的方式完全相同,但是集群节点只能使用 0 号数据库,单机服务器可以任意使用
+集群节点保存键值对以及键值对过期时间的方式,与单机 Redis 服务器保存键值对以及键值对过期时间的方式完全相同,但是**集群节点只能使用 0 号数据库**,单机服务器可以任意使用
除了将键值对保存在数据库里面之外,节点还会用 clusterState 结构中的 slots_to_keys 跳跃表来**保存槽和键之间的关系**
@@ -15033,10 +14987,7 @@ def CLUSTER_KEYSLOT(key):
reply_client(slot);
```
-判断槽是否由当前节点负责处理:
-
-* 如果 clusterState.slots[i] 等于 clusterState.myself,那么说明槽 i 由当前节点负责,节点可以执行客户端发送的命令
-* 如果 clusterState.slots[i] 不等于 clusterState.myself,那么说明槽 i 并非由当前节点负责,节点会根据 clusterState.slots[i] 指向的clusterNode 结构所记录的节点 IP 和端口号,向客户端返回 MOVED 错误
+判断槽是否由当前节点负责处理:如果 clusterState.slots[i] 不等于 clusterState.myself,那么说明槽 i 并非由当前节点负责,节点会根据 clusterState.slots[i] 指向的 clusterNode 结构所记录的节点 IP 和端口号,向客户端返回 MOVED 错误
@@ -15101,8 +15052,8 @@ Redis 集群的重新分片操作可以将任意数量已经指派给某个节
Redis 的集群管理软件 redis-trib 负责执行重新分片操作,redis-trib 通过向源节点和目标节点发送命令来进行重新分片操作
-* redis-trib 向目标节点发送 `CLUSTER SETSLOT IMPORTING ` 命令,让目标节点准备好从源节点导入属于槽 slot 的键值对
-* redis-trib 向源节点发送 `CLUSTER SETSLOT MIGRATING ` 命令,让源节点准备好将属于槽 slot 的键值对迁移至目标节点
+* 向目标节点发送 `CLUSTER SETSLOT IMPORTING ` 命令,准备好从源节点导入属于槽 slot 的键值对
+* 向源节点发送 `CLUSTER SETSLOT MIGRATING ` 命令,让源节点准备好将属于槽 slot 的键值对迁移
* redis-trib 向源节点发送 `CLUSTER GETKEYSINSLOT ` 命令,获得最多 count 个属于槽 slot 的键值对的键名
* 对于每个 key,redis-trib 都向源节点发送一个 `MIGRATE 0 [-k ]
- ```
-
- 范例:100 个连接,5000 次请求对应的性能
-
- ```sh
- redis-benchmark -c 100 -n 5000
- ```
+参考文档:https://help.aliyun.com/document_detail/353223.html
- 
-* redis-cli
- monitor:启动服务器调试信息
+***
- ```sh
- monitor
- ```
- slowlog:慢日志
- ```sh
- slowlog [operator] #获取慢查询日志
- ```
+### 慢查询
- * get :获取慢查询日志信息
- * len :获取慢查询日志条目数
- * reset :重置慢查询日志
+确认服务和 Redis 之间的链路是否正常,排除网络原因后进行 Redis 的排查:
- 相关配置:
+* 使用复杂度过高的命令
+* 操作大 key,分配内存和释放内存会比较耗时
+* key 集中过期,导致定时任务需要更长的时间去清理
+* 实例内存达到上限,每次写入新的数据之前,Redis 必须先从实例中踢出一部分数据
- ```sh
- slowlog-log-slower-than 1000 #设置慢查询的时间下线,单位:微妙
- slowlog-max-len 100 #设置慢查询命令对应的日志显示长度,单位:命令数
- ```
+参考文章:https://www.cnblogs.com/traditional/p/15633919.html(非常好)
@@ -16557,227 +16357,6 @@ public class JDBCDemo01 {
-***
-
-
-
-### 工具类
-
-* 配置文件(在 src 下创建 config.properties)
-
- ```properties
- driverClass=com.mysql.jdbc.Driver
- url=jdbc:mysql://192.168.2.184:3306/db14
- username=root
- password=123456
- ```
-
-* 工具类
-
- ```java
- public class JDBCUtils {
- //1.私有构造方法
- private JDBCUtils(){
- };
-
- //2.声明配置信息变量
- private static String driverClass;
- private static String url;
- private static String username;
- private static String password;
- private static Connection con;
-
- //3.静态代码块中实现加载配置文件和注册驱动
- static{
- try{
- //通过类加载器返回配置文件的字节流
- InputStream is = JDBCUtils.class.getClassLoader().
- getResourceAsStream("config.properties");
-
- //创建Properties集合,加载流对象的信息
- Properties prop = new Properties();
- prop.load(is);
-
- //获取信息为变量赋值
- driverClass = prop.getProperty("driverClass");
- url = prop.getProperty("url");
- username = prop.getProperty("username");
- password = prop.getProperty("password");
-
- //注册驱动
- Class.forName(driverClass);
-
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
-
- //4.获取数据库连接的方法
- public static Connection getConnection() {
- try {
- con = DriverManager.getConnection(url,username,password);
- } catch (SQLException e) {
- e.printStackTrace();
- }
- return con;
- }
-
- //5.释放资源的方法
- public static void close(Connection con, Statement stat, ResultSet rs) {
- if(con != null) {
- try {
- con.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
-
- if(stat != null) {
- try {
- stat.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
-
- if(rs != null) {
- try {
- rs.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
- }
- //方法重载,可能没有返回值对象
- public static void close(Connection con, Statement stat) {
- close(con,stat,null);
- }
- }
- ```
-
-
-
-
-****
-
-
-
-### 数据封装
-
-从数据库读取数据并封装成 Student 对象,需要:
-
-- Student 类成员变量对应表中的列
-
-- 所有的基本数据类型需要使用包装类,**以防 null 值无法赋值**
-
- ```java
- public class Student {
- private Integer sid;
- private String name;
- private Integer age;
- private Date birthday;
- ........
- ```
-
-- 数据准备
-
- ```mysql
- -- 创建db14数据库
- CREATE DATABASE db14;
-
- -- 使用db14数据库
- USE db14;
-
- -- 创建student表
- CREATE TABLE student(
- sid INT PRIMARY KEY AUTO_INCREMENT, -- 学生id
- NAME VARCHAR(20), -- 学生姓名
- age INT, -- 学生年龄
- birthday DATE -- 学生生日
- );
-
- -- 添加数据
- INSERT INTO student VALUES (NULL,'张三',23,'1999-09-23'),(NULL,'李四',24,'1998-08-10'),(NULL,'王五',25,'1996-06-06'),(NULL,'赵六',26,'1994-10-20');
- ```
-
-- 操作数据库
-
- ```java
- public class StudentDaoImpl{
- //查询所有学生信息
- @Override
- public ArrayList findAll() {
- //1.
- ArrayList list = new ArrayList<>();
- Connection con = null;
- Statement stat = null;
- ResultSet rs = null;
- try{
- //2.获取数据库连接
- con = JDBCUtils.getConnection();
-
- //3.获取执行者对象
- stat = con.createStatement();
-
- //4.执行sql语句,并且接收返回的结果集
- String sql = "SELECT * FROM student";
- rs = stat.executeQuery(sql);
-
- //5.处理结果集
- while(rs.next()) {
- Integer sid = rs.getInt("sid");
- String name = rs.getString("name");
- Integer age = rs.getInt("age");
- Date birthday = rs.getDate("birthday");
-
- //封装Student对象
- Student stu = new Student(sid,name,age,birthday);
- //将student对象保存到集合中
- list.add(stu);
- }
- } catch(Exception e) {
- e.printStackTrace();
- } finally {
- //6.释放资源
- JDBCUtils.close(con,stat,rs);
- }
- //将集合对象返回
- return list;
- }
-
- //添加学生信息
- @Override
- public int insert(Student stu) {
- Connection con = null;
- Statement stat = null;
- int result = 0;
- try{
- con = JDBCUtils.getConnection();
-
- //3.获取执行者对象
- stat = con.createStatement();
-
- //4.执行sql语句,并且接收返回的结果集
- Date d = stu.getBirthday();
- SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
- String birthday = sdf.format(d);
- String sql = "INSERT INTO student VALUES ('"+stu.getSid()+"','"+stu.getName()+"','"+stu.getAge()+"','"+birthday+"')";
- result = stat.executeUpdate(sql);
-
- } catch(Exception e) {
- e.printStackTrace();
- } finally {
- //6.释放资源
- JDBCUtils.close(con,stat);
- }
- //将结果返回
- return result;
- }
- }
- ```
-
-
-
***
@@ -16856,292 +16435,15 @@ PreparedStatement:预编译 sql 语句的执行者对象,继承 `PreparedSta
-****
-
-
-
-#### 自定义池
-
-DataSource 接口概述:
-
-* java.sql.DataSource 接口:数据源(数据库连接池)
-* Java 中 DataSource 是一个标准的数据源接口,官方提供的数据库连接池规范,连接池类实现该接口
-* 获取数据库连接对象:`Connection getConnection()`
-
-自定义连接池:
-
-```java
-public class MyDataSource implements DataSource{
- //1.定义集合容器,用于保存多个数据库连接对象
- private static List pool = Collections.synchronizedList(new ArrayList());
-
- //2.静态代码块,生成10个数据库连接保存到集合中
- static {
- for (int i = 0; i < 10; i++) {
- Connection con = JDBCUtils.getConnection();
- pool.add(con);
- }
- }
- //3.返回连接池的大小
- public int getSize() {
- return pool.size();
- }
-
- //4.从池中返回一个数据库连接
- @Override
- public Connection getConnection() {
- if(pool.size() > 0) {
- //从池中获取数据库连接
- return pool.remove(0);
- }else {
- throw new RuntimeException("连接数量已用尽");
- }
- }
-}
-```
-
-测试连接池功能:
-
-```java
-public class MyDataSourceTest {
- public static void main(String[] args) throws Exception{
- //创建数据库连接池对象
- MyDataSource dataSource = new MyDataSource();
-
- System.out.println("使用之前连接池数量:" + dataSource.getSize());//10
-
- //获取数据库连接对象
- Connection con = dataSource.getConnection();
- System.out.println(con.getClass());// JDBC4Connection
-
- //查询学生表全部信息
- String sql = "SELECT * FROM student";
- PreparedStatement pst = con.prepareStatement(sql);
- ResultSet rs = pst.executeQuery();
-
- while(rs.next()) {
- System.out.println(rs.getInt("sid") + "\t" + rs.getString("name") + "\t" + rs.getInt("age") + "\t" + rs.getDate("birthday"));
- }
-
- //释放资源
- rs.close();
- pst.close();
- //目前的连接对象close方法,是直接关闭连接,而不是将连接归还池中
- con.close();
-
- System.out.println("使用之后连接池数量:" + dataSource.getSize());//9
- }
-}
-```
-
-结论:释放资源并没有把连接归还给连接池
-
-
-
-***
-
-
-
-#### 归还连接
-
-归还数据库连接的方式:继承方式、装饰者设计者模式、适配器设计模式、动态代理方式
-
-##### 继承方式
-
-继承(无法解决)
-
-- 通过打印连接对象,发现 DriverManager 获取的连接实现类是 JDBC4Connection
-- 自定义一个类,继承 JDBC4Connection 这个类,重写 close() 方法
-- 查看 JDBC 工具类获取连接的方法发现:虽然自定义了一个子类,完成了归还连接的操作。但是 DriverManager 获取的还是 JDBC4Connection 这个对象,并不是我们的子类对象
-
-代码实现
-
-* 自定义继承连接类
-
- ```java
- //1.定义一个类,继承JDBC4Connection
- public class MyConnection1 extends JDBC4Connection{
- //2.定义Connection连接对象和容器对象的成员变量
- private Connection con;
- private List pool;
-
- //3.通过有参构造方法为成员变量赋值
- public MyConnection1(String hostToConnectTo, int portToConnectTo, Properties info, String databaseToConnectTo, String url,Connection con,List pool) throws SQLException {
- super(hostToConnectTo, portToConnectTo, info, databaseToConnectTo, url);
- this.con = con;
- this.pool = pool;
- }
-
- //4.重写close方法,完成归还连接
- @Override
- public void close() throws SQLException {
- pool.add(con);
- }
- }
- ```
-
-* 自定义连接池类
-
- ```java
- //将之前的连接对象换成自定义的子类对象
- private static MyConnection1 con;
-
- //4.获取数据库连接的方法
- public static Connection getConnection() {
- try {
- //等效于:MyConnection1 con = new JDBC4Connection(); 语法错误!
- con = DriverManager.getConnection(url,username,password);
- } catch (SQLException e) {
- e.printStackTrace();
- }
-
- return con;
- }
- ```
-
-
-
-***
-
-
-
-##### 装饰者
-
-自定义类实现 Connection 接口,通过装饰设计模式,实现和 mysql 驱动包中的 Connection 实现类相同的功能
-
-在实现类对每个获取的 Connection 进行装饰:把连接和连接池参数传递进行包装
-特点:通过装饰设计模式连接类我们发现,有很多需要重写的方法,代码太繁琐
-
-* 装饰设计模式类
-
- ```java
- //1.定义一个类,实现Connection接口
- public class MyConnection2 implements Connection {
- //2.定义Connection连接对象和连接池容器对象的变量
- private Connection con;
- private List pool;
-
- //3.提供有参构造方法,接收连接对象和连接池对象,对变量赋值
- public MyConnection2(Connection con,List pool) {
- this.con = con;
- this.pool = pool;
- }
-
- //4.在close()方法中,完成连接的归还
- @Override
- public void close() throws SQLException {
- pool.add(con);
- }
- //5.剩余方法,只需要调用mysql驱动包的连接对象完成即可
- @Override
- public Statement createStatement() throws SQLException {
- return con.createStatement();
- }
- ..........
- }
- ```
-
-* 自定义连接池类
-
- ```java
- @Override
- public Connection getConnection() {
- if(pool.size() > 0) {
- //从池中获取数据库连接
- Connection con = pool.remove(0);
- //通过自定义连接对象进行包装
- MyConnection2 mycon = new MyConnection2(con,pool);
- //返回包装后的连接对象
- return mycon;
- }else {
- throw new RuntimeException("连接数量已用尽");
- }
- }
- ```
-
-
***
-##### 适配器
-
-使用适配器设计模式改进,提供一个适配器类,实现 Connection 接口,将所有功能进行实现(除了 close 方法),自定义连接类只需要继承这个适配器类,重写需要改进的 close() 方法即可。
-
-特点:自定义连接类中很简洁。剩余所有的方法抽取到了适配器类中,但是适配器这个类还是我们自己编写。
-
-* 适配器类
-
- ```java
- public abstract class MyAdapter implements Connection {
-
- // 定义数据库连接对象的变量
- private Connection con;
-
- // 通过构造方法赋值
- public MyAdapter(Connection con) {
- this.con = con;
- }
-
- // 所有的方法,均调用mysql的连接对象实现
- @Override
- public Statement createStatement() throws SQLException {
- return con.createStatement();
- }
- }
- ```
-* 自定义连接类
- ```java
- public class MyConnection3 extends MyAdapter {
- //2.定义Connection连接对象和连接池容器对象的变量
- private Connection con;
- private List pool;
-
- //3.提供有参构造方法,接收连接对象和连接池对象,对变量赋值
- public MyConnection3(Connection con,List pool) {
- super(con); // 将接收的数据库连接对象给适配器父类传递
- this.con = con;
- this.pool = pool;
- }
-
- //4.在close()方法中,完成连接的归还
- @Override
- public void close() throws SQLException {
- pool.add(con);
- }
- }
- ```
-
-* 自定义连接池类
-
- ```java
- //从池中返回一个数据库连接
- @Override
- public Connection getConnection() {
- if(pool.size() > 0) {
- //从池中获取数据库连接
- Connection con = pool.remove(0);
- //通过自定义连接对象进行包装
- MyConnection3 mycon = new MyConnection3(con,pool);
- //返回包装后的连接对象
- return mycon;
- }else {
- throw new RuntimeException("连接数量已用尽");
- }
- }
- ```
-
-
-
-***
-
-
-
-##### 动态代理
+#### 归还连接
使用动态代理的方式来改进
@@ -17326,101 +16628,6 @@ Druid 连接池:
-***
-
-
-
-#### 工具类
-
-数据库连接池的工具类:
-
-```java
-public class DataSourceUtils {
- //1.私有构造方法
- private DataSourceUtils(){}
-
- //2.声明数据源变量
- private static DataSource dataSource;
-
- //3.提供静态代码块,完成配置文件的加载和获取数据库连接池对象
- static{
- try{
- //完成配置文件的加载
- InputStream is = DataSourceUtils.class.getClassLoader().getResourceAsStream("druid.properties");
- Properties prop = new Properties();
- prop.load(is);
-
- //获取数据库连接池对象
- dataSource = DruidDataSourceFactory.createDataSource(prop);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
-
- //4.提供一个获取数据库连接的方法
- public static Connection getConnection() {
- Connection con = null;
- try {
- con = dataSource.getConnection();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- return con;
- }
-
- //5.提供一个获取数据库连接池对象的方法
- public static DataSource getDataSource() {
- return dataSource;
- }
-
- //6.释放资源
- public static void close(Connection con, Statement stat, ResultSet rs) {
- if(con != null) {
- try {
- con.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
-
- if(stat != null) {
- try {
- stat.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
-
- if(rs != null) {
- try {
- rs.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
- }
- //方法重载
- public static void close(Connection con, Statement stat) {
- if(con != null) {
- try {
- con.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
-
- if(stat != null) {
- try {
- stat.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
- }
-}
-
-```
-
diff --git a/Frame.md b/Frame.md
index 65b948a..f00ae48 100644
--- a/Frame.md
+++ b/Frame.md
@@ -739,9 +739,13 @@ Maven 的插件用来执行生命周期中的相关事件
### 继承
-作用:通过继承可以实现在子工程中沿用父工程中的配置
+Maven 中的继承与 Java 中的继承相似,可以实现在子工程中沿用父工程中的配置
-- Maven 中的继承与 Java 中的继承相似,在子工程中配置继承关系
+dependencyManagement 里只是声明依赖,并不实现引入,所以子工程需要显式声明需要用的依赖
+
+- 如果子工程中未声明依赖,则不会从父项目继承下来
+- 在子工程中声明该依赖项,并且不指定具体版本,才会从父项目中继承该项,version 和 scope 都继承取自父工程 pom 文件
+- 如果子工程中指定了版本号,那么使用子工程中指定的 jar 版本
制作方式:
@@ -1544,9 +1548,9 @@ Reactor 对象通过 select 监控客户端请求事件,收到事件后通过
采用多个 Reactor ,执行流程:
-* Reactor 主线程 MainReactor 通过 select 监控建立连接事件,收到事件后通过 Acceptor 接收,处理建立连接事件,处理完成后 MainReactor 会将连接分配给 Reactor 子线程的 SubReactor(有多个)处理
+* Reactor 主线程 MainReactor 通过 select **监控建立连接事件**,收到事件后通过 Acceptor 接收,处理建立连接事件,处理完成后 MainReactor 会将连接分配给 Reactor 子线程的 SubReactor(有多个)处理
-* SubReactor 将连接加入连接队列进行监听,并创建一个 Handler 用于处理该连接的事件,当有新的事件发生时,SubReactor 会调用连接对应的 Handler 进行响应
+* SubReactor 将连接加入连接队列进行监听其他事件,并创建一个 Handler 用于处理该连接的事件,当有新的事件发生时,SubReactor 会调用连接对应的 Handler 进行响应
* Handler 通过 read 读取数据后,会分发给 Worker 线程池进行业务处理
@@ -3073,7 +3077,7 @@ Protobuf 是以 message 的方式来管理数据,支持跨平台、跨语言
```protobuf
syntax = "proto3"; // 版本
option java_outer_classname = "StudentPOJO"; // 生成的外部类名,同时也是文件名
- // protobuf 使用 message 管理数据
+
message Student { // 在 StudentPOJO 外部类种生成一个内部类 Student,是真正发送的 POJO 对象
int32 id = 1; // Student 类中有一个属性:名字为 id 类型为 int32(protobuf类型) ,1表示属性序号,不是值
string name = 2;
@@ -3435,6 +3439,8 @@ RCVBUF_ALLOCATOR:属于 SocketChannal 参数
### 消息队列
+#### 应用场景
+
消息队列是一种先进先出的数据结构,常见的应用场景:
* 应用解耦:系统的耦合性越高,容错性就越低
@@ -3443,7 +3449,7 @@ RCVBUF_ALLOCATOR:属于 SocketChannal 参数
-* 流量削峰:应用系统如果遇到系统请求流量的瞬间猛增,有可能会将系统压垮,使用消息队列可以将大量请求缓存起来,分散到很长一段时间处理,这样可以提高系统的稳定性和用户体验。
+* 流量削峰:应用系统如果遇到系统请求流量的瞬间猛增,有可能会将系统压垮,使用消息队列可以将大量请求缓存起来,分散到很长一段时间处理,这样可以提高系统的稳定性和用户体验
@@ -3459,6 +3465,36 @@ RCVBUF_ALLOCATOR:属于 SocketChannal 参数
+***
+
+
+
+#### 技术选型
+
+RocketMQ 对比 Kafka 的优点
+
+* 支持 Pull和 Push 两种消息模式
+
+- 支持延时消息、死信队列、消息重试、消息回溯、消息跟踪、事务消息等高级特性
+- 对消息可靠性做了改进,**保证消息不丢失并且至少消费一次**,与 Kafka 一样是先写 PageCache 再落盘,并且数据有多副本
+- RocketMQ 存储模型是所有的 Topic 都写到同一个 Commitlog 里,是一个 append only 操作,在海量 Topic 下也能将磁盘的性能发挥到极致,并且保持稳定的写入时延。Kafka 的吞吐非常高(零拷贝、操作系统页缓存、磁盘顺序写),但是在多 Topic 下时延不够稳定(顺序写入特性会被破坏从而引入大量的随机 I/O),不适合实时在线业务场景
+- 经过阿里巴巴多年双 11 验证过、可以支持亿级并发的开源消息队列
+
+Kafka 比 RocketMQ 吞吐量高:
+
+* Kafka 将 Producer 端将多个小消息合并,采用异步批量发送的机制,当发送一条消息时,消息并没有发送到 Broker 而是缓存起来,直接向业务返回成功,当缓存的消息达到一定数量时再批量发送
+
+* 减少了网络 I/O,提高了消息发送的性能,但是如果消息发送者宕机,会导致消息丢失,降低了可靠性
+* RocketMQ 缓存过多消息会导致频繁 GC,并且为了保证可靠性没有采用这种方式
+
+Topic 的 partition 数量过多时,Kafka 的性能不如 RocketMQ:
+
+* 两者都使用文件存储,但是 Kafka 是一个分区一个文件,Topic 过多时分区的总量也会增加,过多的文件导致对消息刷盘时出现文件竞争磁盘,造成性能的下降。**一个分区只能被一个消费组中的一个消费线程进行消费**,因此可以同时消费的消费端也比较少
+
+* RocketMQ 所有队列都存储在一个文件中,每个队列存储的消息量也比较小,因此多 Topic 的对 RocketMQ 的性能的影响较小
+
+
+
****
@@ -3970,9 +4006,9 @@ Broker 可以配置 messageDelayLevel,该属性是 Broker 的属性,不属
- 1<=level<=maxLevel:消息延迟特定时间,例如 level==1,延迟 1s
- level > maxLevel:则 level== maxLevel,例如 level==20,延迟 2h
-定时消息会暂存在名为 SCHEDULE_TOPIC_XXXX 的 Topic 中,并根据 delayTimeLevel 存入特定的 queue,队列的标识 `queueId = delayTimeLevel – 1`,即**一个 queue 只存相同延迟的消息**,保证具有相同发送延迟的消息能够顺序消费。Broker 会调度地消费 SCHEDULE_TOPIC_XXXX,将消息写入真实的 Topic
+定时消息会暂存在名为 SCHEDULE_TOPIC_XXXX 的 Topic 中,并根据 delayTimeLevel 存入特定的 queue,队列的标识 `queueId = delayTimeLevel – 1`,即**一个 queue 只存相同延迟的消息**,保证具有相同发送延迟的消息能够顺序消费。Broker 会为每个延迟级别提交一个定时任务,调度地消费 SCHEDULE_TOPIC_XXXX,将消息写入真实的 Topic
-注意:定时消息在第一次写入和调度写入真实 Topic 时都会计数,因此发送数量、tps 都会变高。
+注意:定时消息在第一次写入和调度写入真实 Topic 时都会计数,因此发送数量、tps 都会变高
@@ -4555,7 +4591,7 @@ RocketMQ 消息的存储是由 ConsumeQueue 和 CommitLog 配合完成 的,Com
* ConsumerQueue:消息消费队列,存储消息在 CommitLog 的索引。RocketMQ 消息消费时要遍历 CommitLog 文件,并根据主题 Topic 检索消息,这是非常低效的。引入 ConsumeQueue 作为消费消息的索引,**保存了指定 Topic 下的队列消息在 CommitLog 中的起始物理偏移量 offset**,消息大小 size 和消息 Tag 的 HashCode 值,每个 ConsumeQueue 文件大小约 5.72M
* IndexFile:为了消息查询提供了一种通过 Key 或时间区间来查询消息的方法,通过 IndexFile 来查找消息的方法**不影响发送与消费消息的主流程**。IndexFile 的底层存储为在文件系统中实现的 HashMap 结构,故 RocketMQ 的索引文件其底层实现为 **hash 索引**
-RocketMQ 采用的是混合型的存储结构,即为 Broker 单个实例下所有的队列共用一个日志数据文件(CommitLog)来存储。混合型存储结构(多个 Topic 的消息实体内容都存储于一个 CommitLog 中)针对 Producer 和 Consumer 分别采用了**数据和索引部分相分离**的存储结构,Producer 发送消息至 Broker 端,然后 Broker 端使用同步或者异步的方式对消息刷盘持久化,保存至 CommitLog 中。只要消息被持久化至磁盘文件 CommitLog 中,Producer 发送的消息就不会丢失,Consumer 也就肯定有机会去消费这条消息
+RocketMQ 采用的是混合型的存储结构,即为 Broker 单个实例下所有的队列共用一个日志数据文件(CommitLog)来存储,多个 Topic 的消息实体内容都存储于一个 CommitLog 中。混合型存储结构针对 Producer 和 Consumer 分别采用了**数据和索引部分相分离**的存储结构,Producer 发送消息至 Broker 端,然后 Broker 端使用同步或者异步的方式对消息刷盘持久化,保存至 CommitLog 中。只要消息被持久化至磁盘文件 CommitLog 中,Producer 发送的消息就不会丢失,Consumer 也就肯定有机会去消费这条消息
服务端支持长轮询模式,当消费者无法拉取到消息后,可以等下一次消息拉取,Broker 允许等待 30s 的时间,只要这段时间内有新消息到达,将直接返回给消费端。RocketMQ 的具体做法是,使用 Broker 端的后台服务线程 ReputMessageService 不停地分发请求并异步构建 ConsumeQueue(逻辑消费队列)和 IndexFile(索引文件)数据
@@ -4593,7 +4629,7 @@ MappedByteBuffer 内存映射的方式**限制**一次只能映射 1.5~2G 的文
页缓存(PageCache)是 OS 对文件的缓存,每一页的大小通常是 4K,用于加速对文件的读写。因为 OS 将一部分的内存用作 PageCache,所以程序对文件进行顺序读写的速度几乎接近于内存的读写速度
-* 对于数据的写入,OS 会先写入至 Cache 内,随后通过异步的方式由 pdflush 内核线程将 Cache 内的数据刷盘至物理磁盘上
+* 对于数据的写入,OS 会先写入至 Cache 内,随后**通过异步的方式由 pdflush 内核线程将 Cache 内的数据刷盘至物理磁盘上**
* 对于数据的读取,如果一次读取文件时出现未命中 PageCache 的情况,OS 从物理磁盘上访问读取文件的同时,会顺序对其他相邻块的数据文件进行**预读取**(局部性原理,最大 128K)
在 RocketMQ 中,ConsumeQueue 逻辑消费队列存储的数据较少,并且是顺序读取,在 PageCache 机制的预读取作用下,Consume Queue 文件的读性能几乎接近读内存,即使在有消息堆积情况下也不会影响性能。但是 CommitLog 消息存储的日志数据文件读取内容时会产生较多的随机访问读取,严重影响性能。选择合适的系统 IO 调度算法和固态硬盘,比如设置调度算法为 Deadline,随机读的性能也会有所提升
@@ -4627,8 +4663,6 @@ RocketMQ 采用文件系统的方式,无论同步还是异步刷盘,都使
-
-
****
@@ -4698,7 +4732,9 @@ BrokerServer 的高可用通过 Master 和 Slave 的配合:
* Slave 只负责读,当 Master 不可用,对应的 Slave 仍能保证消息被正常消费
* 配置多组 Master-Slave 组,其他的 Master-Slave 组也会保证消息的正常发送和消费
-* 目前不支持把 Slave 自动转成 Master,需要手动停止 Slave 角色的 Broker,更改配置文件,用新的配置文件启动 Broker
+* **目前不支持把 Slave 自动转成 Master**,需要手动停止 Slave 角色的 Broker,更改配置文件,用新的配置文件启动 Broker
+
+ 所以需要配置多个 Master 保证可用性,否则一个 Master 挂了导致整体系统的写操作不可用
生产端的高可用:在创建 Topic 的时候,把 Topic 的**多个 Message Queue 创建在多个 Broker 组**上(相同 Broker 名称,不同 brokerId 的机器),当一个 Broker 组的 Master 不可用后,其他组的 Master 仍然可用,Producer 仍然可以发送消息
@@ -4716,7 +4752,7 @@ BrokerServer 的高可用通过 Master 和 Slave 的配合:
如果一个 Broker 组有 Master 和 Slave,消息需要从 Master 复制到 Slave 上,有同步和异步两种复制方式:
-* 同步复制方式:Master 和 Slave 均写成功后才反馈给客户端写成功状态。在同步复制方式下,如果 Master 出故障, Slave 上有全部的备份数据,容易恢复,但是同步复制会增大数据写入延迟,降低系统吞吐量
+* 同步复制方式:Master 和 Slave 均写成功后才反馈给客户端写成功状态(写 Page Cache)。在同步复制方式下,如果 Master 出故障, Slave 上有全部的备份数据,容易恢复,但是同步复制会增大数据写入延迟,降低系统吞吐量
* 异步复制方式:只要 Master 写成功,即可反馈给客户端写成功状态,系统拥有较低的延迟和较高的吞吐量,但是如果 Master 出了故障,有些数据因为没有被写入 Slave,有可能会丢失
@@ -4737,6 +4773,8 @@ RocketMQ 支持消息的高可靠,影响消息可靠性的几种情况:
后两种属于单点故障,且无法恢复,一旦发生,在此单点上的消息全部丢失。RocketMQ 在这两种情况下,通过主从异步复制,可保证 99% 的消息不丢,但是仍然会有极少量的消息可能丢失。通过**同步双写技术**可以完全避免单点,但是会影响性能,适合对消息可靠性要求极高的场合,RocketMQ 从 3.0 版本开始支持同步双写
+一般而言,我们会建议采取同步双写 + 异步刷盘的方式,在消息的可靠性和性能间有一个较好的平衡
+
****
@@ -4786,7 +4824,7 @@ LatencyFaultTolerance 机制是实现消息发送高可用的核心关键所在

-集群模式下,**queue 都是只允许分配只一个实例**,如果多个实例同时消费一个 queue 的消息,由于拉取哪些消息是 Consumer 主动控制的,会导致同一个消息在不同的实例下被消费多次
+集群模式下,**queue 都是只允许分配一个实例**,如果多个实例同时消费一个 queue 的消息,由于拉取哪些消息是 Consumer 主动控制的,会导致同一个消息在不同的实例下被消费多次
通过增加 Consumer 实例去分摊 queue 的消费,可以起到水平扩展的消费能力的作用。而当有实例下线时,会重新触发负载均衡,这时候原来分配到的 queue 将分配到其他实例上继续消费。但是如果 Consumer 实例的数量比 Message Queue 的总数量还多的话,多出来的 Consumer 实例将无法分到 queue,也就无法消费到消息,也就无法起到分摊负载的作用了,所以需要**控制让 queue 的总数量大于等于 Consumer 的数量**
@@ -4802,7 +4840,7 @@ LatencyFaultTolerance 机制是实现消息发送高可用的核心关键所在
Consumer 端实现负载均衡的核心类 **RebalanceImpl**
-在 Consumer 实例的启动流程中的会启动 MQClientInstance 实例,完成负载均衡服务线程 RebalanceService 的启动(每隔 20s 执行一次),RebalanceService 线程的 run() 方法最终调用的是 RebalanceImpl 类的 rebalanceByTopic() 方法,该方法是实现 Consumer 端负载均衡的核心。rebalanceByTopic() 方法会根据消费者通信类型为广播模式还是集群模式做不同的逻辑处理。这里主要看下集群模式下的处理流程:
+在 Consumer 实例的启动流程中的会启动 MQClientInstance 实例,完成负载均衡服务线程 RebalanceService 的启动(**每隔 20s 执行一次**负载均衡),RebalanceService 线程的 run() 方法最终调用的是 RebalanceImpl 类的 rebalanceByTopic() 方法,该方法是实现 Consumer 端负载均衡的核心。rebalanceByTopic() 方法会根据广播模式还是集群模式做不同的逻辑处理。主要看集群模式:
* 从 rebalanceImpl 实例的本地缓存变量 topicSubscribeInfoTable 中,获取该 Topic 主题下的消息消费队列集合 mqSet
@@ -4822,7 +4860,7 @@ Consumer 端实现负载均衡的核心类 **RebalanceImpl**
对比下 RebalancePushImpl 和 RebalancePullImpl 两个实现类的 dispatchPullRequest() 方法,RebalancePullImpl 类里面的该方法为空
-消息消费队列在同一消费组不同消费者之间的负载均衡,其核心设计理念是在**一个消息消费队列在同一时间只允许被同一消费组内的一个消费者消费,一个消息消费者能同时消费多个消息队列**
+消息消费队列在**同一消费组不同消费者之间的负载均衡**,其核心设计理念是在**一个消息消费队列在同一时间只允许被同一消费组内的一个消费者消费,一个消息消费者能同时消费多个消息队列**
@@ -4883,7 +4921,7 @@ IndexFile 文件的存储在 `$HOME\store\index${fileName}`,文件名 fileName
#### 消息重投
-生产者在发送消息时,同步消息和异步消息失败会重投,oneway 没有任何保证。消息重投保证消息尽可能发送成功、不丢失,但当出现消息量大、网络抖动时,可能会造成消息重复;生产者主动重发、Consumer 负载变化也会导致重复消息。
+生产者在发送消息时,同步消息和异步消息失败会重投,oneway 没有任何保证。消息重投保证消息尽可能发送成功、不丢失,但当出现消息量大、网络抖动时,可能会造成消息重复;生产者主动重发、Consumer 负载变化也会导致重复消息
如下方法可以设置消息重投策略:
@@ -4915,7 +4953,7 @@ RocketMQ 会为每个消费组都设置一个 Topic 名称为 `%RETRY%+consumerG
* 无序消息(普通、定时、延时、事务消息)的重试,可以通过设置返回状态达到消息重试的结果。无序消息的重试只针对集群消费方式生效,广播方式不提供失败重试特性,即消费失败后,失败消息不再重试,继续消费新的消息
-**无序消息情况下**,因为异常恢复需要一些时间,会为重试队列设置多个重试级别,每个重试级别都有对应的重新投递延时,重试次数越多投递延时就越大。RocketMQ 对于重试消息的处理是先保存至 Topic 名称为 `SCHEDULE_TOPIC_XXXX` 的延迟队列中,后台定时任务按照对应的时间进行 Delay 后重新保存至 `%RETRY%+consumerGroup` 的重试队列中
+**无序消息情况下**,因为异常恢复需要一些时间,会为重试队列设置多个重试级别,每个重试级别都有对应的重新投递延时,重试次数越多投递延时就越大。RocketMQ 对于重试消息的处理是先保存至 Topic 名称为 `SCHEDULE_TOPIC_XXXX` 的延迟队列中,后台定时任务**按照对应的时间进行 Delay 后**重新保存至 `%RETRY%+consumerGroup` 的重试队列中
消息队列 RocketMQ 默认允许每条消息最多重试 16 次,每次重试的间隔时间如下表示:
@@ -5045,6 +5083,31 @@ public class MessageListenerImpl implements MessageListener {
+***
+
+
+
+### 高可靠性
+
+RocketMQ 消息丢失可能发生在以下三个阶段:
+
+- 生产阶段:消息在 Producer 发送端创建出来,经过网络传输发送到 Broker 存储端
+ - 生产者得到一个成功的响应,就可以认为消息的存储和消息的消费都是可靠的
+ - 消息重投机制
+- 存储阶段:消息在 Broker 端存储,如果是主备或者多副本,消息会在这个阶段被复制到其他的节点或者副本上
+ - 单点:刷盘机制(同步或异步)
+ - 主从:消息同步机制(异步复制或同步双写,主从复制章节详解)
+ - 过期删除:操作 CommitLog、ConsumeQueue 文件是基于文件内存映射机制,并且在启动的时候会将所有的文件加载,为了避免内存与磁盘的浪费,让磁盘能够循环利用,防止磁盘不足导致消息无法写入等引入了文件过期删除机制。最终使得磁盘水位保持在一定水平,最终保证新写入消息的可靠存储
+- 消费阶段:Consumer 消费端从 Broker存储端拉取消息,经过网络传输发送到 Consumer 消费端上
+ - 消息重试机制来最大限度的保证消息的消费
+ - 消费失败的进行消息回退,重试次数过多的消息放入死信队列
+
+
+
+推荐文章:https://cdn.modb.pro/db/394751
+
+
+
****
@@ -7374,7 +7437,7 @@ AllocateMappedFileService **创建 MappedFile 服务**
ReputMessageService 消息分发服务,用于构**建 ConsumerQueue 和 IndexFile 文件**
-* run():**循环执行 doReput 方法**,所以发送的消息存储进 CL 就可以产生对应的 CQ,每执行一次线程休眠 1 毫秒
+* run():**循环执行 doReput 方法**,**所以发送的消息存储进 CL 就可以产生对应的 CQ**,每执行一次线程休眠 1 毫秒
```java
public void run()
@@ -7566,7 +7629,7 @@ public GetMessageResult getMessage(final String group, final String topic, final
`if ((bufferTotal + sizePy) > ...)`:热数据一次 pull 请求最大允许获取 256kb 的消息
- `if (messageTotal > ...)`:冷数据一次 pull 请求最大允许获取32 条消息
+ `if (messageTotal > ...)`:冷数据一次 pull 请求最大允许获取 32 条消息
* `if (messageFilter != null)`:按照消息 tagCode 进行过滤
@@ -10209,16 +10272,17 @@ ConsumeRequest 是 ConsumeMessageOrderlyService 的内部类,是一个 Runnabl
生产流程:
-* 首先获取当前消息主题的发布信息,获取不到去 Namesrv 获取(默认有 TBW102),并将获取的到的路由数据转化为发布数据,**创建 MQ 队列**,客户端实例同样更新订阅数据,创建 MQ 队列,放入负载均衡服务 topicSubscribeInfoTable 中
+* 首先获取当前消息主题的发布信息,获取不到去 Namesrv 获取(默认有 TBW102),并将获取的到的路由数据转化为发布数据,**创建 MQ 队列在多个 Broker 组**(一组代表一主多从的 Broker 架构),客户端实例同样更新订阅数据,创建 MQ 队列,放入负载均衡服务 topicSubscribeInfoTable 中
* 然后从发布数据中选择一个 MQ 队列发送消息
-* Broker 端通过 SendMessageProcessor 对发送的消息进行持久化处理,存储到 CommitLog。将重试次数过多的消息加入死信队列,将延迟消息的主题和队列修改为调度主题和调度队列 ID
+* Broker 端通过 SendMessageProcessor 对发送的消息进行持久化处理,存储到 CommitLog。将重试次数过多的消息加入**死信队列**,将延迟消息的主题和队列修改为调度主题和调度队列 ID
* Broker 启动 ScheduleMessageService 服务会为每个延迟级别创建一个延迟任务,让延迟消息得到有效的处理,将到达交付时间的消息修改为原始主题的原始 ID 存入 CommitLog,消费者就可以进行消费了
消费流程:
+* 消息消费队列 ConsumerQueue 存储消息在 CommitLog 的索引,消费者通过该队列来读取消息实体内容,一个 MQ 就对应一个 CQ
* 首先通过负载均衡服务,将分配到当前消费者实例的 MQ 创建 PullRequest,并放入 PullMessageService 的本地阻塞队列内
* PullMessageService 循环从阻塞队列获取请求对象,发起拉消息请求,并创建 PullCallback 回调对象,将正常拉取的消息**提交到消费任务线程池**,并设置请求的下一次拉取位点,重新放入阻塞队列,形成闭环
-* 消费任务服务对消费失败的消息进行回退,回退失败的消息会再次提交消费任务重新消费
+* 消费任务服务对消费失败的消息进行回退,通过内部生产者实例发送回退消息,回退失败的消息会再次提交消费任务重新消费
* Broker 端对拉取消息的请求进行处理(processRequestCommand),查询成功将消息放入响应体,通过 Netty 写回客户端,当 `pullRequest.offset == queue.maxOffset` 说明该队列已经没有需要获取的消息,将请求放入长轮询集合等待有新消息
* PullRequestHoldService 负责长轮询,每 5 秒遍历一次长轮询集合,将满足条件的 PullRequest 再次提交到线程池内处理
@@ -10519,7 +10583,7 @@ Zookeepe 集群三个角色:
* Epoch:每个 Leader 任期的代号,同一轮选举投票过程中的该值是相同的,投完一次票就增加
-选举机制:半数机制,超过半数的投票旧通过
+选举机制:半数机制,超过半数的投票就通过
* 第一次启动选举规则:投票过半数时,服务器 ID 大的胜出
@@ -10712,7 +10776,7 @@ CAP 理论指的是在一个分布式系统中,Consistency(一致性)、Av
CAP 三个基本需求,因为 P 是必须的,因此分布式系统选择就在 CP 或者 AP 中:
* 一致性:指数据在多个副本之间是否能够保持数据一致的特性,当一个系统在数据一致的状态下执行更新操作后,也能保证系统的数据仍然处于一致的状态
-* 可用性:指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果
+* 可用性:指系统提供的服务必须一直处于可用的状态,即使集群中一部分节点故障,对于用户的每一个操作请求总是能够在有限的时间内返回结果
* 分区容错性:分布式系统在遇到任何网络分区故障时,仍然能够保证对外提供服务,不会宕机,除非是整个网络环境都发生了故障
@@ -11223,7 +11287,7 @@ FastLeaderElection 中有 WorkerReceiver 线程
-### 状态同步
+#### 状态同步
选举结束后,每个节点都需要根据角色更新自己的状态,Leader 更新状态为 Leader,其他节点更新状态为 Follower,整体流程:
diff --git a/Java.md b/Java.md
index 26fbec9..23a9e8b 100644
--- a/Java.md
+++ b/Java.md
@@ -6,25 +6,22 @@
#### 变量类型
-| | 成员变量 | 局部变量 | 静态变量 |
-| :------: | :------------: | :------------------------: | :-------------------------: |
-| 定义位置 | 在类中,方法外 | 方法中或者方法的形参 | 在类中,方法外 |
-| 初始化值 | 有默认初始化值 | 无,先定义,赋值后才能使用 | 有默认初始化值 |
-| 调用方法 | 对象调用 | | 对象调用,类名调用 |
-| 存储位置 | 堆中 | 栈中 | 方法区(JDK8 以后移到堆中) |
-| 生命周期 | 与对象共存亡 | 与方法共存亡 | 与类共存亡 |
-| 别名 | 实例变量 | | 类变量,静态成员变量 |
+| | 成员变量 | 局部变量 | 静态变量 |
+| :------: | :------------: | :------------------: | :-------------------------: |
+| 定义位置 | 在类中,方法外 | 方法中或者方法的形参 | 在类中,方法外 |
+| 初始化值 | 有默认初始化值 | 无,赋值后才能使用 | 有默认初始化值 |
+| 调用方法 | 对象调用 | | 对象调用,类名调用 |
+| 存储位置 | 堆中 | 栈中 | 方法区(JDK8 以后移到堆中) |
+| 生命周期 | 与对象共存亡 | 与方法共存亡 | 与类共存亡 |
+| 别名 | 实例变量 | | 类变量,静态成员变量 |
-**静态变量只有一个,成员变量是类中的变量,局部变量是方法中的变量**
+静态变量只有一个,成员变量是类中的变量,局部变量是方法中的变量
-初学时笔记内容参考视频:https://www.bilibili.com/video/BV1TE41177mP,随着学习的深入又增加了很多知识
+初学时笔记内容参考视频:https://www.bilibili.com/video/BV1TE41177mP,随着学习的深入又增加很多知识
-给初学者的一些个人建议:
-* 初学者对编程的认知比较浅显,一些专有词汇和概念难以理解,所以建议观看视频进行入门,大部分公开课视频讲的比较基础
-* 在有了一定的编程基础后,需要看一些经典书籍和技术博客,来扩容自己的知识广度和深度,可以长期保持记录笔记的好习惯
@@ -40,9 +37,8 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
**byte:**
-- byte 数据类型是 8 位、有符号的,以**二进制补码**表示的整数,**8 位一个字节**,首位是符号位
-- 最小值是 -128(-2^7)
-- 最大值是 127(2^7-1)
+- byte 数据类型是 8 位、有符号的,以二进制补码表示的整数,**8 位一个字节**,首位是符号位
+- 最小值是 -128(-2^7)、最大值是 127(2^7-1)
- 默认值是 `0`
- byte 类型用在大型数组中节约空间,主要代替整数,byte 变量占用的空间只有 int 类型的四分之一
- 例子:`byte a = 100,byte b = -50`
@@ -50,8 +46,7 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
**short:**
- short 数据类型是 16 位、有符号的以二进制补码表示的整数
-- 最小值是 -32768(-2^15)
-- 最大值是 32767(2^15 - 1)
+- 最小值是 -32768(-2^15)、最大值是 32767(2^15 - 1)
- short 数据类型也可以像 byte 那样节省空间,一个 short 变量是 int 型变量所占空间的二分之一
- 默认值是 `0`
- 例子:`short s = 1000,short r = -20000`
@@ -59,8 +54,7 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
**int:**
- int 数据类型是 32 位 4 字节、有符号的以二进制补码表示的整数
-- 最小值是 -2,147,483,648(-2^31)
-- 最大值是 2,147,483,647(2^31 - 1)
+- 最小值是 -2,147,483,648(-2^31)、最大值是 2,147,483,647(2^31 - 1)
- 一般地整型变量默认为 int 类型
- 默认值是 `0`
- 例子:`int a = 100000, int b = -200000`
@@ -68,12 +62,10 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
**long:**
- long 数据类型是 64 位 8 字节、有符号的以二进制补码表示的整数
-- 最小值是 -9,223,372,036,854,775,808(-2^63)
-- 最大值是 9,223,372,036,854,775,807(2^63 -1)
+- 最小值是 -9,223,372,036,854,775,808(-2^63)、最大值是 9,223,372,036,854,775,807(2^63 -1)
- 这种类型主要使用在需要比较大整数的系统上
- 默认值是 ` 0L`
-- 例子: `long a = 100000L,Long b = -200000L`
- L 理论上不分大小写,但是若写成 I 容易与数字 1 混淆,不容易分辩,所以最好大写
+- 例子: `long a = 100000L,Long b = -200000L`,L 理论上不分大小写,但是若写成 I 容易与数字 1 混淆,不容易分辩
**float:**
@@ -104,7 +96,7 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
- char 类型是一个单一的 16 位**两个字节**的 Unicode 字符
- 最小值是 `\u0000`(即为 0)
- 最大值是 `\uffff`(即为 65535)
-- char 数据类型可以存储任何字符
+- char 数据类型可以**存储任何字符**
- 例子:`char c = 'A'`,`char c = '张'`
@@ -117,7 +109,7 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
* float 与 double:
- Java 不能隐式执行**向下转型**,因为这会使得精度降低(参考多态),但是可以向上转型
+ Java 不能隐式执行**向下转型**,因为这会使得精度降低,但是可以向上转型
```java
//1.1字面量属于double类型,不能直接将1.1直接赋值给 float 变量,因为这是向下转型
@@ -146,7 +138,7 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
字面量 1 是 int 类型,比 short 类型精度要高,因此不能隐式地将 int 类型向下转型为 short 类型
- 使用 += 或者 ++ 运算符会执行隐式类型转换:
+ 使用 += 或者 ++ 运算符会执行类型转换:
```java
short s1 = 1;
@@ -177,12 +169,12 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
基本数据类型 包装类(引用数据类型)
byte Byte
short Short
-int Integer(特殊)
+int Integer
long Long
float Float
double Double
-char Character(特殊)
+char Character
boolean Boolean
```
Java 为包装类做了一些特殊功能,具体来看特殊功能主要有:
@@ -209,17 +201,15 @@ Java 为包装类做了一些特殊功能,具体来看特殊功能主要有:
String itStr1 = Integer.toString(it);
System.out.println(itStr1+1);//1001
// c.直接把基本数据类型+空字符串就得到了字符串。
- String itStr2 = it+"";
+ String itStr2 = it + "";
System.out.println(itStr2+1);// 1001
- // 2.把字符串类型的数值转换成对应的基本数据类型的值。(真的很有用)
+ // 2.把字符串类型的数值转换成对应的基本数据类型的值
String numStr = "23";
- //int numInt = Integer.parseInt(numStr);
int numInt = Integer.valueOf(numStr);
System.out.println(numInt+1);//24
String doubleStr = "99.9";
- //double doubleDb = Double.parseDouble(doubleStr);
double doubleDb = Double.valueOf(doubleStr);
System.out.println(doubleDb+0.1);//100.0
}
@@ -329,7 +319,7 @@ new Integer(123) 与 Integer.valueOf(123) 的区别在于:
System.out.println(z == k); // true
```
-valueOf() 方法的实现比较简单,就是先判断值是否在缓存池中,如果在的话就直接返回缓存池的内容。编译器会在自动装箱过程调用 valueOf() 方法,因此多个值相同且值在缓存池范围内的 Integer 实例使用自动装箱来创建,那么就会引用相同的对象。
+valueOf() 方法的实现比较简单,就是先判断值是否在缓存池中,如果在的话就直接返回缓存池的内容。编译器会在自动装箱过程调用 valueOf() 方法,因此多个值相同且值在缓存池范围内的 Integer 实例使用自动装箱来创建,那么就会引用相同的对象
**基本类型对应的缓存池如下:**
@@ -340,7 +330,7 @@ valueOf() 方法的实现比较简单,就是先判断值是否在缓存池中
- Integer values between -128 and 127
- Character in the range \u0000 to \u007F (0 and 127)
-在 jdk 1.8 所有的数值类缓冲池中,**Integer 的缓存池 IntegerCache 很特殊,这个缓冲池的下界是 -128,上界默认是 127**,但是上界是可调的,在启动 JVM 时通过 `AutoBoxCacheMax=` 来指定这个缓冲池的大小,该选项在 JVM 初始化的时候会设定一个名为 java.lang.IntegerCache.high 系统属性,然后 IntegerCache 初始化的时候就会读取该系统属性来决定上界
+在 jdk 1.8 所有的数值类缓冲池中,**Integer 的缓存池 IntegerCache 很特殊,这个缓冲池的下界是 -128,上界默认是 127**,但是上界是可调的,在启动 JVM 时通过 `AutoBoxCacheMax=` 来指定这个缓冲池的大小,该选项在 JVM 初始化的时候会设定一个名为 java.lang.Integer.IntegerCache 系统属性,然后 IntegerCache 初始化的时候就会读取该系统属性来决定上界
```java
Integer x = 100; // 自动装箱,底层调用 Integer.valueOf(1)
@@ -417,7 +407,7 @@ public static void main(String[] args) {
#### 元素访问
-* **索引**:每一个存储到数组的元素,都会自动的拥有一个编号,从 **0** 开始。这个自动编号称为数组索引(index),可以通过数组的索引访问到数组中的元素。
+* **索引**:每一个存储到数组的元素,都会自动的拥有一个编号,从 **0** 开始。这个自动编号称为数组索引(index),可以通过数组的索引访问到数组中的元素
* **访问格式**:数组名[索引],`arr[0]`
* **赋值:**`arr[0] = 10`
@@ -430,7 +420,7 @@ public static void main(String[] args) {
#### 内存分配
-内存是计算机中的重要器件,临时存储区域,作用是运行程序。我们编写的程序是存放在硬盘中,在硬盘中的程序是不会运行的,必须放进内存中才能运行,运行完毕后会清空内存。 Java 虚拟机要运行程序,必须要对内存进行空间的分配和管理。
+内存是计算机中的重要器件,临时存储区域,作用是运行程序。编写的程序是存放在硬盘中,在硬盘中的程序是不会运行的,必须放进内存中才能运行,运行完毕后会清空内存,Java 虚拟机要运行程序,必须要对内存进行空间的分配和管理
| 区域名称 | 作用 |
| ---------- | ---------------------------------------------------------- |
@@ -440,7 +430,7 @@ public static void main(String[] args) {
| 堆内存 | 存储对象或者数组,new 来创建的,都存储在堆内存 |
| 方法栈 | 方法运行时使用的内存,比如 main 方法运行,进入方法栈中执行 |
-**内存分配图**:Java 内存分配
+内存分配图:**Java 数组分配在堆内存**
* 一个数组内存图
@@ -475,9 +465,9 @@ public static void main(String[] args) {
}
```
- arr = null,表示变量 arr 将不再保存数组的内存地址,也就不允许再操作数组,因此运行的时候会抛出空指针异常。在开发中,空指针异常是不能出现的,一旦出现了,就必须要修改编写的代码。
+ arr = null,表示变量 arr 将不再保存数组的内存地址,也就不允许再操作数组,因此运行的时候会抛出空指针异常。在开发中,空指针异常是不能出现的,一旦出现了,就必须要修改编写的代码
- 解决方案:给数组一个真正的堆内存空间引用即可!
+ 解决方案:给数组一个真正的堆内存空间引用即可
@@ -491,14 +481,12 @@ public static void main(String[] args) {
初始化:
-* 动态初始化:
-
- 数据类型[][] 变量名 = new 数据类型[m] [n] : `int[][] arr = new int[3][3]`
+* 动态初始化:数据类型[][] 变量名 = new 数据类型[m] [n],`int[][] arr = new int[3][3]`
* m 表示这个二维数组,可以存放多少个一维数组,行
* n 表示每一个一维数组,可以存放多少个元素,列
* 静态初始化
- * 数据类型[][] 变量名 = new 数据类型[][]{ {元素1, 元素2...} , {元素1, 元素2...}
+ * 数据类型[][] 变量名 = new 数据类型 [][]{{元素1, 元素2...} , {元素1, 元素2...}
* 数据类型[][] 变量名 = {{元素1, 元素2...}, {元素1, 元素2...}...}
* `int[][] arr = {{11,22,33}, {44,55,66}}`
@@ -537,20 +525,20 @@ public class Test1 {
### 运算
* i++ 与 ++i 的区别?
- i++ 表示先将 i 放在表达式中运算,然后再加 1
- ++i 表示先将 i 加 1,然后再放在表达式中运算
+
+ i++ 表示先将 i 放在表达式中运算,然后再加 1,++i 表示先将 i 加 1,然后再放在表达式中运算
* || 和 |,&& 和& 的区别,逻辑运算符
- **& 和| 称为布尔运算符,位运算符。&& 和 || 称为条件布尔运算符,也叫短路运算符**。
+ **& 和| 称为布尔运算符,位运算符;&& 和 || 称为条件布尔运算符,也叫短路运算符**
如果 && 运算符的第一个操作数是 false,就不需要考虑第二个操作数的值了,因为无论第二个操作数的值是什么,其结果都是 false;同样,如果第一个操作数是 true,|| 运算符就返回 true,无需考虑第二个操作数的值;但 & 和 | 却不是这样,它们总是要计算两个操作数。为了提高性能,**尽可能使用 && 和 || 运算符**
-* ^ 异或:两位相异为 1,相同为 0,又叫不进位加法。同或:两位相同为 1,相异为 0
+* 异或 ^:两位相异为 1,相同为 0,又叫不进位加法
-* switch
+* 同或:两位相同为 1,相异为 0
- 从 Java 7 开始,可以在 switch 条件判断语句中使用 String 对象
+* switch:从 Java 7 开始,可以在 switch 条件判断语句中使用 String 对象
```java
String s = "a";
@@ -570,11 +558,9 @@ public class Test1 {
* break:跳出一层循环
-* 移位运算
+* 移位运算:计算机里一般用**补码表示数字**,正数、负数的表示区别就是最高位是 0 还是 1
- 计算机里一般用**补码表示数字**,正数、负数的表示区别就是最高位是 0 还是 1
-
- * 正数的原码反码补码相同
+ * 正数的原码反码补码相同,最高位为 0
```java
100: 00000000 00000000 00000000 01100100
@@ -583,7 +569,7 @@ public class Test1 {
* 负数:
原码:最高位为 1,其余位置和正数相同
反码:保证符号位不变,其余位置取反
- 补码:保证符号位不变,其余位置取反加 1,即反码 +1
+ 补码:保证符号位不变,其余位置取反后加 1,即反码 +1
```java
-100 原码: 10000000 00000000 00000000 01100100 //32位
@@ -636,7 +622,7 @@ public class Test1 {
格式:数据类型... 参数名称
-作用:传输参数非常灵活,方便,可以不传输参数、传输一个参数、或者传输一个数组。
+作用:传输参数非常灵活,可以不传输参数、传输一个参数、或者传输一个数组
可变参数的注意事项:
@@ -837,7 +823,7 @@ public class MethodDemo {
Java 的参数是以**值传递**的形式传入方法中
-值传递和引用传递的区别在于传递后会不会影响实参的值:值传递会创建副本,引用传递不会创建副本
+值传递和引用传递的区别在于传递后会不会影响实参的值:**值传递会创建副本**,引用传递不会创建副本
* 基本数据类型:形式参数的改变,不影响实际参数
@@ -996,11 +982,11 @@ Debug 是供程序员使用的程序调试工具,它可以用于查看程序
### 概述
-**Java 是一种面向对象的高级编程语言。**
+Java 是一种面向对象的高级编程语言
-**三大特征:封装,继承,多态**
+面向对象三大特征:**封装,继承,多态**
-面向对象最重要的两个概念:类和对象
+两个概念:类和对象
* 类:相同事物共同特征的描述,类只是学术上的一个概念并非真实存在的,只能描述一类事物
* 对象:是真实存在的实例, 实例 == 对象,**对象是类的实例化**
@@ -1198,11 +1184,11 @@ Java 是通过成员变量是否有 static 修饰来区分是类的还是属于
内存问题:
-* **栈内存存放 main 方法和地址**
+* 栈内存存放 main 方法和地址
-* **堆内存存放对象和变量**
+* 堆内存存放对象和变量
-* **方法区存放 class 和静态变量(jdk8 以后移入堆)**
+* 方法区存放 class 和静态变量(jdk8 以后移入堆)
访问问题:
@@ -1210,7 +1196,7 @@ Java 是通过成员变量是否有 static 修饰来区分是类的还是属于
* 实例方法是否可以直接访问静态成员变量?可以,静态成员变量可以被共享访问
* 实例方法是否可以直接访问实例方法? 可以,实例方法和实例方法都属于对象
* 实例方法是否可以直接访问静态方法?可以,静态方法可以被共享访问
-* 静态方法是否可以直接访问实例变量? 不可以,实例变量必须用对象访问!!
+* 静态方法是否可以直接访问实例变量? 不可以,实例变量**必须用对象访问**!!
* 静态方法是否可以直接访问静态变量? 可以,静态成员变量可以被共享访问。
* 静态方法是否可以直接访问实例方法? 不可以,实例方法必须用对象访问!!
* 静态方法是否可以直接访问静态方法?可以,静态方法可以被共享访问!!
@@ -1256,7 +1242,7 @@ Java 是通过成员变量是否有 static 修饰来区分是类的还是属于
* 子类不能继承父类的构造器,子类有自己的构造器
* 子类是不能可以继承父类的私有成员的,可以反射暴力去访问继承自父类的私有成员
-* 子类是不能继承父类的静态成员的,子类只是可以访问父类的静态成员,父类静态成员只有一份可以被子类共享访问,**共享并非继承**
+* 子类是不能继承父类的静态成员,父类静态成员只有一份可以被子类共享访问,**共享并非继承**
```java
public class ExtendsDemo {
@@ -1267,8 +1253,10 @@ public class ExtendsDemo {
System.out.println(Cat.schoolName);
}
}
+
class Cat extends Animal{
}
+
class Animal{
public static String schoolName ="seazean";
public static void test(){}
@@ -1295,6 +1283,7 @@ public class ExtendsDemo {
w.showName();
}
}
+
class Wolf extends Animal{
private String name = "子类狼";
public void showName(){
@@ -1327,7 +1316,7 @@ class Animal{
方法重写的校验注解:@Override
-* 方法加了这个注解,那就必须是成功重写父类的方法,否则报错
+* 方法加了这个注解,那就必须是成功重写父类的方法,否则报错
* @Override 优势:可读性好,安全,优雅
**子类可以扩展父类的功能,但不能改变父类原有的功能**,重写有以下三个限制:
@@ -1432,11 +1421,11 @@ class Animal{
* this 代表了当前对象的引用(继承中指代子类对象):this.子类成员变量、this.子类成员方法、**this(...)** 可以根据参数匹配访问本类其他构造器
* super 代表了父类对象的引用(继承中指代了父类对象空间):super.父类成员变量、super.父类的成员方法、super(...) 可以根据参数匹配访问父类的构造器
-**注意:**
+注意:
-* this(...) 借用本类其他构造器,super(...) 调用父类的构造器。
-* this(...) 或 super(...) 必须放在构造器的第一行,否则报错!
-* this(...) 和 super(...) 不能同时出现在构造器中,因为构造函数必须出现在第一行上,只能选择一个。
+* this(...) 借用本类其他构造器,super(...) 调用父类的构造器
+* this(...) 或 super(...) 必须放在构造器的第一行,否则报错
+* this(...) 和 super(...) **不能同时出现**在构造器中,因为构造函数必须出现在第一行上,只能选择一个
```java
public class ThisDemo {
@@ -1503,7 +1492,7 @@ final 和 abstract 的关系是**互斥关系**,不能同时修饰类或者同
final 修饰静态成员变量,变量变成了常量
-**常量:有 public static final 修饰,名称字母全部大写,多个单词用下划线连接。**
+常量:有 public static final 修饰,名称字母全部大写,多个单词用下划线连接
final 修饰静态成员变量可以在哪些地方赋值:
@@ -1520,7 +1509,6 @@ public class FinalDemo {
static{
//SCHOOL_NAME = "java";//报错
SCHOOL_NAME1 = "张三1";
- //SCHOOL_NAME1 = "张三2"; // 报错,第二次赋值!
}
}
```
@@ -1575,13 +1563,13 @@ public class FinalDemo {
#### 基本介绍
-> 父类知道子类要完成某个功能,但是每个子类实现情况不一样。
+> 父类知道子类要完成某个功能,但是每个子类实现情况不一样
抽象方法:没有方法体,只有方法签名,必须用 abstract 修饰的方法就是抽象方法
抽象类:拥有抽象方法的类必须定义成抽象类,必须用 abstract 修饰,**抽象类是为了被继承**
-一个类继承抽象类,**必须重写抽象类的全部抽象方法**,否则这个类必须定义成抽象类,因为拥有抽象方法的类必须定义成抽象类
+一个类继承抽象类,**必须重写抽象类的全部抽象方法**,否则这个类必须定义成抽象类
```java
public class AbstractDemo {
@@ -1811,32 +1799,32 @@ public class InterfaceDemo {
InterfaceJDK8.inAddr();
}
}
-class Man implements InterfaceJDK8{
+class Man implements InterfaceJDK8 {
@Override
public void work() {
System.out.println("工作中。。。");
}
}
-interface InterfaceJDK8{
+interface InterfaceJDK8 {
//抽象方法!!
void work();
// a.默认方法(就是之前写的普通实例方法)
// 必须用接口的实现类的对象来调用。
- default void run(){
+ default void run() {
go();
System.out.println("开始跑步🏃");
}
// b.静态方法
// 注意:接口的静态方法必须用接口的类名本身来调用
- static void inAddr(){
+ static void inAddr() {
System.out.println("我们在武汉");
}
// c.私有方法(就是私有的实例方法): JDK 1.9才开始有的。
// 只能在本接口中被其他的默认方法或者私有方法访问。
- private void go(){
+ private void go() {
System.out.println("开始。。");
}
}
@@ -1874,7 +1862,7 @@ interface InterfaceJDK8{
#### 基本介绍
-多态的概念:同一个实体同时具有多种形式同一个类型的对象,执行同一个行为,在不同的状态下会表现出不同的行为特征。
+多态的概念:同一个实体同时具有多种形式同一个类型的对象,执行同一个行为,在不同的状态下会表现出不同的行为特征
多态的格式:
@@ -1897,11 +1885,11 @@ interface InterfaceJDK8{
* 存在方法重写
多态的优势:
-* 在多态形式下,右边对象可以实现组件化切换,业务功能也随之改变,便于扩展和维护。可以实现类与类之间的**解耦**
+* 在多态形式下,右边对象可以实现组件化切换,便于扩展和维护,也可以实现类与类之间的**解耦**
* 父类类型作为方法形式参数,传递子类对象给方法,可以传入一切子类对象进行方法的调用,更能体现出多态的**扩展性**与便利性
多态的劣势:
-* 多态形式下,不能直接调用子类特有的功能,因为编译看左边,父类中没有子类独有的功能,所以代码在编译阶段就直接报错了!
+* 多态形式下,不能直接调用子类特有的功能,因为编译看左边,父类中没有子类独有的功能,所以代码在编译阶段就直接报错了
```java
public class PolymorphicDemo {
@@ -2061,7 +2049,7 @@ static class Outter{
#### 实例内部类
-定义:无 static 修饰的内部类,属于外部类的每个对象,跟着外部类对象一起加载。
+定义:无 static 修饰的内部类,属于外部类的每个对象,跟着外部类对象一起加载
实例内部类的成分特点:实例内部类中不能定义静态成员,其他都可以定义
@@ -2192,9 +2180,8 @@ static {
```
* 静态代码块特点:
- * 必须有 static 修饰
+ * 必须有 static 修饰,只能访问静态资源
* 会与类一起优先加载,且自动触发执行一次
- * 只能访问静态资源
* 静态代码块作用:
* 可以在执行类的方法等操作之前先在静态代码块中进行静态资源的初始化
* **先执行静态代码块,在执行 main 函数里的操作**
@@ -2337,7 +2324,7 @@ Object 的 clone() 是 protected 方法,一个类不显式去重写 clone(),
* 浅拷贝 (shallowCopy):**对基本数据类型进行值传递,对引用数据类型只是复制了引用**,被复制对象属性的所有的引用仍然指向原来的对象,简而言之就是增加了一个指针指向原来对象的内存地址
- **Java 中的复制方法基本都是浅克隆**:Object.clone()、System.arraycopy()、Arrays.copyOf()
+ **Java 中的复制方法基本都是浅拷贝**:Object.clone()、System.arraycopy()、Arrays.copyOf()
* 深拷贝 (deepCopy):对基本数据类型进行值传递,对引用数据类型是一个整个独立的对象拷贝,会拷贝所有的属性并指向的动态分配的内存,简而言之就是把所有属性复制到一个新的内存,增加一个指针指向新内存。所以使用深拷贝的情况下,释放内存的时候不会出现使用浅拷贝时释放同一块内存的错误
@@ -2390,11 +2377,11 @@ Objects 类与 Object 是继承关系
Objects 的方法:
-* `public static boolean equals(Object a, Object b)`:比较两个对象是否相同。
- 底层进行非空判断,从而可以避免空指针异常,更安全,推荐使用!
-
- ```java
+* `public static boolean equals(Object a, Object b)`:比较两个对象是否相同
+
+ ```java
public static boolean equals(Object a, Object b) {
+ // 进行非空判断,从而可以避免空指针异常
return a == b || a != null && a.equals(b);
}
```
@@ -2637,7 +2624,7 @@ public static void main(String[] args) {
System.out.println(str1 == str1.intern());//true,字符串池中不存在,把堆中的引用复制一份放入串池
String str2 = new StringBuilder("ja").append("va").toString();
- System.out.println(str2 == str2.intern());//false
+ System.out.println(str2 == str2.intern());//false,字符串池中存在,直接返回已经存在的引用
}
```
@@ -2878,7 +2865,7 @@ public class MyArraysDemo {
1. 导入包:`import java.util.Random`
2. 创建对象:`Random r = new Random()`
3. 随机整数:`int num = r.nextInt(10)`
- * 解释:10 代表的是一个范围,如果括号写 10,产生的随机数就是 0 - 9,括号写 20 的随机数则是 0 - 19
+ * 解释:10 代表的是一个范围,如果括号写 10,产生的随机数就是 0 - 9,括号写 20 的随机数则是 0 - 19
* 获取 0 - 10:`int num = r.nextInt(10 + 1)`
4. 随机小数:`public double nextDouble()` 从范围 `0.0d` 至 `1.0d` (左闭右开),伪随机地生成并返回
@@ -2900,11 +2887,11 @@ System 代表当前系统
* `public static long currentTimeMillis()`:获取当前系统此刻时间毫秒值
* `static void arraycopy(Object var0, int var1, Object var2, int var3, int var4)`:数组拷贝
- 参数一:原数组
- 参数二:从原数组的哪个位置开始赋值
- 参数三:目标数组
- 参数四:从目标数组的哪个位置开始赋值
- 参数五:赋值几个
+ * 参数一:原数组
+ * 参数二:从原数组的哪个位置开始赋值
+ * 参数三:目标数组
+ * 参数四:从目标数组的哪个位置开始赋值
+ * 参数五:赋值几个
```java
public class SystemDemo {
@@ -3758,15 +3745,12 @@ public class RegexDemo {
数据存储的常用结构有:栈、队列、数组、链表和红黑树
* 队列(queue):先进先出,后进后出。(FIFO first in first out)
- 场景:各种排队、叫号系统,有很多集合可以实现队列
-
+
* 栈(stack):后进先出,先进后出 (LIFO)
- 压栈 == 入栈、弹栈 == 出栈
- 场景:手枪的弹夹
-
+
* 数组:数组是内存中的连续存储区域,分成若干等分的小区域(每个区域大小是一样的)元素存在索引
- 特点:**查询元素快**(根据索引快速计算出元素的地址,然后立即去定位)
- **增删元素慢**(创建新数组,迁移元素)
+
+ 特点:**查询元素快**(根据索引快速计算出元素的地址,然后立即去定位),**增删元素慢**(创建新数组,迁移元素)
* 链表:元素不是内存中的连续区域存储,元素是游离存储的,每个元素会记录下个元素的地址
特点:**查询元素慢,增删元素快**(针对于首尾元素,速度极快,一般是双链表)
@@ -3774,11 +3758,12 @@ public class RegexDemo {
* 树:
* 二叉树:binary tree 永远只有一个根节点,是每个结点不超过2个节点的树(tree)
+
特点:二叉排序树:小的左边,大的右边,但是可能树很高,性能变差,为了做排序和搜索会进行左旋和右旋实现平衡查找二叉树,让树的高度差不大于1
-* 红黑树(基于红黑规则实现自平衡的排序二叉树):树保证到了很矮小,但是又排好序,性能最高的树
+ * 红黑树(基于红黑规则实现自平衡的排序二叉树):树保证到了很矮小,但是又排好序,性能最高的
- 特点:**红黑树的增删查改性能都好**
+ 特点:**红黑树的增删查改性能都好**
各数据结构时间复杂度对比:
@@ -3970,8 +3955,8 @@ ArrayList 添加的元素,是有序,可重复,有索引的
* `public boolean add(E e)`:将指定的元素追加到此集合的末尾
* `public void add(int index, E element)`:将指定的元素,添加到该集合中的指定位置上
* `public E get(int index)`:返回集合中指定位置的元素
-* `public E remove(int index)`:移除列表中指定位置的元素, 返回的是被移除的元素
-* `public E set(int index, E element)`:用指定元素替换集合中指定位置的元素,返回更新前的元素值
+* `public E remove(int index)`:移除列表中指定位置的元素,返回的是被移除的元素
+* `public E set(int index, E element)`:用指定元素替换集合中指定位置的元素,返回更新前的元素值
* `int indexOf(Object o)`:返回列表中指定元素第一次出现的索引,如果不包含此元素,则返回 -1
```java
@@ -4008,7 +3993,7 @@ public class ArrayList extends AbstractList
核心方法:
-* 构造函数:以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量,即向数组中添加第一个元素时,**数组容量扩为 10**
+* 构造函数:以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量(惰性初始化),即向数组中添加第一个元素时,**数组容量扩为 10**
* 添加元素:
@@ -4059,8 +4044,8 @@ public class ArrayList extends AbstractList
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
- System.arraycopy(elementData, index, elementData, index + 1,
- size - index);
+ // 将指定索引后的数据后移
+ System.arraycopy(elementData, index, elementData, index + 1, size - index);
elementData[index] = element;
size++;
}
@@ -4091,7 +4076,7 @@ public class ArrayList extends AbstractList
* OutOfMemoryError:Requested array size exceeds VM limit(请求的数组大小超出 VM 限制)
* OutOfMemoryError: Java heap space(堆区内存不足,可以通过设置 JVM 参数 -Xmx 来调节)
-* 删除元素:需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,在旧数组上操作,该操作的时间复杂度为 O(N),可以看到 ArrayList 删除元素的代价是非常高的,
+* 删除元素:需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,在旧数组上操作,该操作的时间复杂度为 O(N),可以看到 ArrayList 删除元素的代价是非常高的
```java
public E remove(int index) {
@@ -4212,10 +4197,6 @@ LinkedList 除了拥有 List 集合的全部功能还多了很多操作首尾元
* `public E poll()`:检索并删除此列表的头(第一个元素)
* `public void addFirst(E e)`:将指定元素插入此列表的开头
* `public void addLast(E e)`:将指定元素添加到此列表的结尾
-* `public E getFirst()`:返回此列表的第一个元素
-* `public E getLast()`:返回此列表的最后一个元素
-* `public E removeFirst()`:移除并返回此列表的第一个元素
-* `public E removeLast()`:移除并返回此列表的最后一个元素
* `public E pop()`:从此列表所表示的堆栈处弹出一个元素
* `public void push(E e)`:将元素推入此列表所表示的堆栈
* `public int indexOf(Object o)`:返回此列表中指定元素的第一次出现的索引,如果不包含返回 -1
@@ -4401,7 +4382,7 @@ Set 集合添加的元素是无序,不重复的。
每个元素的 hashcode() 的值进行响应的算法运算,计算出的值相同的存入一个数组块中,以链表的形式存储,如果链表长度超过8就采取红黑树存储,所以输出的元素是无序的。
-* 如何设置只要对象内容一样,就希望集合认为它们重复了:**重写 hashCode 和 equals 方法**
+* 如何设置只要对象内容一样,就希望集合认为重复:**重写 hashCode 和 equals 方法**
@@ -4585,7 +4566,7 @@ Map集合的体系:
LinkedHashMap(实现类)
```
-Map集合的特点:
+Map 集合的特点:
1. Map 集合的特点都是由键决定的
2. Map 集合的键是无序,不重复的,无索引的(Set)
@@ -4597,13 +4578,6 @@ HashMap:元素按照键是无序,不重复,无索引,值不做要求
LinkedHashMap:元素按照键是有序,不重复,无索引,值不做要求
-```java
-//经典代码
-Map maps = new HashMap<>();
-maps.put("手机",1);
-System.out.println(maps);
-```
-
***
@@ -4714,12 +4688,12 @@ JDK7 对比 JDK8:
* 哈希表(Hash table,也叫散列表),根据关键码值而直接访问的数据结构。通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度,这个映射函数叫做散列函数,存放记录的数组叫做散列表
-* JDK1.8 之前 HashMap 由 数组+链表 组成
+* JDK1.8 之前 HashMap 由数组+链表组成
* 数组是 HashMap 的主体
* 链表则是为了解决哈希冲突而存在的(**拉链法解决冲突**),拉链法就是头插法,两个对象调用的 hashCode 方法计算的哈希码值(键的哈希)一致导致计算的数组索引值相同
-* JDK1.8 以后 HashMap 由 **数组+链表 +红黑树**数据结构组成
+* JDK1.8 以后 HashMap 由**数组+链表 +红黑树**数据结构组成
* 解决哈希冲突时有了较大的变化
* 当链表长度**超过(大于)阈值**(或者红黑树的边界值,默认为 8)并且当前数组的**长度大于等于 64 时**,此索引位置上的所有数据改为红黑树存储
@@ -4767,7 +4741,7 @@ HashMap 继承关系如下图所示:
```java
// 默认的初始容量是16 -- 1<<4相当于1*2的4次方---1*16
- static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
+ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
```
HashMap 构造方法指定集合的初始化容量大小:
@@ -4776,9 +4750,9 @@ HashMap 继承关系如下图所示:
HashMap(int initialCapacity)// 构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap
```
- * 为什么必须是 2 的 n 次幂?
+ * 为什么必须是 2 的 n 次幂?用位运算替代取余计算,减少 rehash 的代价(移动的节点少)
- HashMap 中添加元素时,需要根据 key 的 hash 值,确定在数组中的具体位置。为了存取高效,要尽量较少碰撞,把数据分配均匀,每个链表长度大致相同,实现该方法的算法就是取模,hash%length,计算机中直接求余效率不如位移运算,所以源码中使用 hash&(length-1),实际上**hash % length == hash & (length-1)的前提是 length 是 2 的n次幂**
+ HashMap 中添加元素时,需要根据 key 的 hash 值确定在数组中的具体位置。为了减少碰撞,把数据分配均匀,每个链表长度大致相同,实现该方法就是取模 `hash%length`,计算机中直接求余效率不如位移运算, **`hash % length == hash & (length-1)` 的前提是 length 是 2 的 n 次幂**
散列平均分布:2 的 n 次方是 1 后面 n 个 0,2 的 n 次方 -1 是 n 个 1,可以**保证散列的均匀性**,减少碰撞
@@ -4804,11 +4778,6 @@ HashMap 继承关系如下图所示:
static final int MAXIMUM_CAPACITY = 1 << 30;// 0100 0000 0000 0000 0000 0000 0000 0000 = 2 ^ 30
```
- 最大容量为什么是 2 的 30 次方原因:
-
- * int 类型是 32 位整型,占 4 个字节
- * Java 的原始类型里没有无符号类型,所以首位是符号位正数为 0,负数为 1,
-
5. 当链表的值超过 8 则会转红黑树(JDK1.8 新增)
```java
@@ -4852,7 +4821,7 @@ HashMap 继承关系如下图所示:
static final int MIN_TREEIFY_CAPACITY = 64;
```
- 原因:数组比较小的情况下变为红黑树结构,反而会降低效率,红黑树需要进行左旋,右旋,变色这些操作来保持平衡。同时数组长度小于 64 时,搜索时间相对快些,所以为了提高性能和减少搜索时间,底层在阈值大于 8 并且数组长度大于等于 64 时,链表才转换为红黑树,效率也变的更高效
+ 原因:数组比较小的情况下变为红黑树结构,反而会降低效率,红黑树需要进行左旋,右旋,变色这些操作来保持平衡
8. table 用来初始化(必须是二的 n 次幂)
@@ -4861,8 +4830,6 @@ HashMap 继承关系如下图所示:
transient Node[] table;
```
- jdk8 之前数组类型是 Entry类型,之后是 Node 类型。只是换了个名字,都实现了一样的接口 Map.Entry,负责存储键值对数据的
-
9. HashMap 中**存放元素的个数**
```java
@@ -4884,7 +4851,7 @@ HashMap 继承关系如下图所示:
int threshold;
```
-12. **哈希表的加载因子(重点)**
+12. **哈希表的加载因子**
```java
final float loadFactor;
@@ -4892,9 +4859,9 @@ HashMap 继承关系如下图所示:
* 加载因子的概述
- loadFactor 加载因子,是用来衡量 HashMap 满的程度,表示 **HashMap 的疏密程度**,影响 hash 操作到同一个数组位置的概率,计算 HashMap 的实时加载因子的方法为:size/capacity,而不是占用桶的数量去除以 capacity,capacity 是桶的数量,也就是 table 的长度 length。
+ loadFactor 加载因子,是用来衡量 HashMap 满的程度,表示 HashMap 的疏密程度,影响 hash 操作到同一个数组位置的概率,计算 HashMap 的实时加载因子的方法为 **size/capacity**,而不是占用桶的数量去除以 capacity,capacity 是桶的数量,也就是 table 的长度 length
- 当 HashMap 里面容纳的元素已经达到 HashMap 数组长度的 75% 时,表示 HashMap 拥挤,需要扩容,而扩容这个过程涉及到 rehash、复制数据等操作,非常消耗性能,所以开发中尽量减少扩容的次数,可以通过创建 HashMap 集合对象时指定初始容量来尽量避免。
+ 当 HashMap 容纳的元素已经达到数组长度的 75% 时,表示 HashMap 拥挤需要扩容,而扩容这个过程涉及到 rehash、复制数据等操作,非常消耗性能,所以开发中尽量减少扩容的次数,通过创建 HashMap 集合对象时指定初始容量来避免
```java
HashMap(int initialCapacity, float loadFactor)//构造指定初始容量和加载因子的空HashMap
@@ -4904,7 +4871,7 @@ HashMap 继承关系如下图所示:
loadFactor 太大导致查找元素效率低,存放的数据拥挤,太小导致数组的利用率低,存放的数据会很分散。loadFactor 的默认值为 **0.75f 是官方给出的一个比较好的临界值**
- * threshold 计算公式:capacity(数组长度默认16) * loadFactor(默认 0.75)。当 size>=threshold 的时候,那么就要考虑对数组的 resize(扩容),这就是衡量数组是否需要扩增的一个标准, 扩容后的 HashMap 容量是之前容量的**两倍**
+ * threshold 计算公式:capacity(数组长度默认16) * loadFactor(默认 0.75)。当 size >= threshold 的时候,那么就要考虑对数组的 resize(扩容),这就是衡量数组是否需要扩增的一个标准, 扩容后的 HashMap 容量是之前容量的**两倍**
@@ -5013,8 +4980,8 @@ HashMap 继承关系如下图所示:
```java
static final int hash(Object key) {
int h;
- // 1)如果key等于null:可以看到当key等于null的时候也是有哈希值的,返回的是0.
- // 2)如果key不等于null:首先计算出key的hashCode赋值给h,然后与h无符号右移16位后的二进制进行按位异或得到最后的hash值
+ // 1)如果key等于null:可以看到当key等于null的时候也是有哈希值的,返回的是0
+ // 2)如果key不等于null:首先计算出key的hashCode赋值给h,然后与h无符号右移16位后的二进制进行按位异或
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
```
@@ -5096,8 +5063,6 @@ HashMap 继承关系如下图所示:
2. 如果是树形化遍历桶中的元素,创建相同个数的树形节点,复制内容,建立起联系,类似单向链表转换为双向链表
3. 让桶中的第一个元素即数组中的元素指向新建的红黑树的节点,以后这个桶里的元素就是红黑树而不是链表数据结构了
-
-
* tableSizeFor():创建 HashMap 指定容量时,HashMap 通过位移运算和或运算得到比指定初始化容量大的最小的 2 的 n 次幂
```java
@@ -5678,15 +5643,11 @@ TreeMap 集合指定大小规则有 2 种方式:
#### WeakMap
-WeakHashMap 是基于弱引用的
-
-内部的 Entry 继承 WeakReference,被弱引用关联的对象在**下一次垃圾回收时会被回收**,并且构造方法传入引用队列,用来在清理对象完成以后清理引用
+WeakHashMap 是基于弱引用的,内部的 Entry 继承 WeakReference,被弱引用关联的对象在**下一次垃圾回收时会被回收**,并且构造方法传入引用队列,用来在清理对象完成以后清理引用
```java
private static class Entry extends WeakReference
@@ -13310,7 +13271,7 @@ Redis 服务器创建并修改 Lua 环境的整个过程:
* 创建 redis.pcall 函数的错误报告辅助函数 `_redis_err_handler `,这个函数可以打印出错代码的来源和发生错误的行数
-* 对 Lua环境中的全局环境进行保护,确保传入服务器的脚本不会因忘记使用 local 关键字,而将额外的全局变量添加到 Lua 环境
+* 对 Lua 环境中的全局环境进行保护,确保传入服务器的脚本不会因忘记使用 local 关键字,而将额外的全局变量添加到 Lua 环境
* 将完成修改的 Lua 环境保存到服务器状态的 lua 属性中,等待执行服务器传来的 Lua 脚本
@@ -13409,7 +13370,7 @@ EVAL 命令第二步是将客户端传入的脚本保存到服务器的 lua_scri
EVAL 命令第三步是执行脚本函数
-* 将 EVAL 命令中传入的**键名(key name)参数和脚本参数**分别保存到 KEYS 数组和 ARGV 数组,将这两个数组作为**全局变量**传入到 Lua 环境里
+* 将 EVAL 命令中传入的**键名参数和脚本参数**分别保存到 KEYS 数组和 ARGV 数组,将这两个数组作为**全局变量**传入到 Lua 环境
* 为 Lua 环境装载超时处理钩子(hook),这个钩子可以在脚本出现超时运行情况时,让客户端通过 `SCRIPT KILL` 命令停止脚本,或者通过 SHUTDOWN 命令直接关闭服务器
因为 Redis 是单线程的执行命令,当 Lua 脚本阻塞时需要兜底策略,可以中断执行
@@ -13477,8 +13438,6 @@ Redis 复制 EVAL、SCRIPT FLUSH、SCRIPT LOAD 三个命令的方法和复制普
-
-
***
@@ -13536,7 +13495,7 @@ Redis 分布式锁的基本使用,悲观锁
`NX`:只在键不存在时,才对键进行设置操作,`SET key value NX` 效果等同于 `SETNX key value`
- `XX` :只在键已经存在时,才对键进行设置操作
+ `XX`:只在键已经存在时,才对键进行设置操作
`EX`:设置键 key 的过期时间,单位时秒
@@ -13557,7 +13516,7 @@ Redis 分布式锁的基本使用,悲观锁
PEXPIRE lock-key milliseconds
```
- 通过 EXPIRE 设置过期时间缺乏原子性,如果在 SETNX 和 EXPIRE 之间出现异常,锁也无法释放
+ 通过 EXPIRE 设置过期时间缺乏原子性,如果在 SETNX 和 EXPIRE 之间出现异常,锁也无法释放
* 在 SET 时指定过期时间,保证原子性
@@ -13656,9 +13615,10 @@ end
超时释放:锁超时释放可以避免死锁,但如果是业务执行耗时较长,需要进行锁续时,防止业务未执行完提前释放锁
-看门狗 watchDog 机制:
+看门狗 Watch Dog 机制:
* 获取锁成功后,提交周期任务,每隔一段时间(Redisson 中默认为过期时间 / 3),重置一次超时时间
+* 如果服务宕机,Watch Dog 机制线程就停止,就不会再延长 key 的过期时间
* 释放锁后,终止周期任务
@@ -13673,7 +13633,7 @@ end
主从一致性:集群模式下,主从同步存在延迟,当加锁后主服务器宕机时,从服务器还没同步主服务器中的锁数据,此时从服务器升级为主服务器,其他线程又可以获取到锁
-将服务器升级为多主多从,:
+将服务器升级为多主多从:
* 获取锁需要从所有主服务器 SET 成功才算获取成功
* 某个 master 宕机,slave 还没有同步锁数据就升级为 master,其他线程尝试加锁会加锁失败,因为其他 master 上已经存在该锁
@@ -13705,7 +13665,7 @@ end
主从复制的特点:
-* **薪火相传**:一个 slave 可以是下一个 slave 的 master,slave 同样可以接收其他 slave 的连接和同步请求,那么该 slave 作为了链条中下一个的 master, 可以有效减轻 master 的写压力,去中心化降低风险
+* **薪火相传**:一个 slave 可以是下一个 slave 的 master,slave 同样可以接收其他 slave 的连接和同步请求,那么该 slave 作为了链条中下一个的 master,可以有效减轻 master 的写压力,去中心化降低风险
注意:主机挂了,从机还是从机,无法写数据了
@@ -14047,7 +14007,7 @@ PSYNC 命令的调用方法有两种
#### 心跳机制
-心跳机制:进入命令传播阶段,从服务器默认会以每秒一次的频率,向主服务器发送命令:`REPLCONF ACK `,re_offset 是从服务器当前的复制偏移量
+心跳机制:进入命令传播阶段,**从服务器**默认会以每秒一次的频率,**向主服务器发送命令**:`REPLCONF ACK `,replication_offset 是从服务器当前的复制偏移量
心跳的作用:
@@ -14086,16 +14046,19 @@ slavel: ip=127.0.0.1,port=22222,state=online,offset=456,lag=3 # 3秒之前发送
#### 配置选项
-Redis 的 min-slaves-to-write 和 min-slaves-max-lag 两个选项可以防止主服务器在**不安全的情况下**执行写命令
+Redis 的 min-slaves-to-write 和 min-slaves-max-lag 两个选项可以防止主服务器在**不安全的情况下**拒绝执行写命令
比如向主服务器设置:
+* min-slaves-to-write:主库最少有 N 个健康的从库存活才能执行写命令,没有足够的从库直接拒绝写入
+* min-slaves-max-lag:从库和主库进行数据复制时的 ACK 消息延迟的最大时间
+
```sh
min-slaves-to-write 5
min-slaves-max-lag 10
```
-那么在从服务器的数最少于 5 个,或者 5 个从服务器的延迟(lag)值都大于或等于10 秒时,主服务器将拒绝执行写命令
+那么在从服务器的数少于 5 个,或者 5 个从服务器的延迟(lag)值都大于或等于10 秒时,主服务器将拒绝执行写命令
@@ -14150,7 +14113,7 @@ master 的 CPU 占用过高或 slave 频繁断开连接
* 出现的原因:
* slave 每 1 秒发送 REPLCONF ACK 命令到 master
- * 当 slave 接到了慢查询时(keys * ,hgetall等),会大量占用 CPU 性能
+ * 当 slave 接到了慢查询时(keys * ,hgetall 等),会大量占用 CPU 性能
* master 每 1 秒调用复制定时函数 replicationCron(),比对 slave 发现长时间没有进行响应
最终导致 master 各种资源(输出缓冲区、带宽、连接等)被严重占用
@@ -14314,7 +14277,7 @@ Sentinel 本质上只是一个运行在特殊模式下的 Redis 服务器,当
#### 代码替换
-将一部分普通 Redis服务器使用的代码替换成 Sentinel 专用代码
+将一部分普通 Redis 服务器使用的代码替换成 Sentinel 专用代码
Redis 服务器端口:
@@ -14358,7 +14321,7 @@ struct sentinelState {
// 当前纪元,用于实现故障转移
uint64_t current_epoch;
- // 保存了所有被这个sentinel监视的主服务器
+ // 【保存了所有被这个sentinel监视的主服务器】
dict *masters;
// 是否进入了 TILT 模式
@@ -14475,10 +14438,10 @@ typedef struct sentinelAddr {
##### 主服务器
-Sentinel 默认会以每十秒一次的频率,通过命令连接向被监视的主服务器发送 INFO 命令,来获取主服务器的当前信息
+Sentinel 默认会以每十秒一次的频率,通过命令连接向被监视的主服务器发送 INFO 命令,来获取主服务器的信息
* 一部分是主服务器本身的信息,包括 runid 域记录的服务器运行 ID,以及 role 域记录的服务器角色
-* 另一部分是服务器属下所有从服务器的信息,每个从服务器都由一个 slave 字符串开头的行记录,根据这些 IP 地址和端口号,Sentinel 无须用户提供从服务器的地址信息,就可以自动发现从服务器
+* 另一部分是服务器属下所有从服务器的信息,每个从服务器都由一个 slave 字符串开头的行记录,根据这些 IP 地址和端口号,Sentinel 无须用户提供从服务器的地址信息,就可以**自动发现从服务器**
```sh
# Server
@@ -14507,7 +14470,7 @@ slave1: ip=l27.0.0.1, port=22222, state=online, offset=22, lag=0
##### 从服务器
-当 Sentinel 发现主服务器有新的从服务器出现时,会为这个新的从服务器创建相应的实例结构, 还会创建到从服务器的命令连接和订阅连接,所以 Sentinel 对所有的从服务器之间都可以进行命令操作
+当 Sentinel 发现主服务器有新的从服务器出现时,会为这个新的从服务器创建相应的实例结构,还会**创建到从服务器的命令连接和订阅连接**,所以 Sentinel 对所有的从服务器之间都可以进行命令操作
Sentinel 默认会以每十秒一次的频率,向从服务器发送 INFO 命令:
@@ -14574,26 +14537,13 @@ SUBSCRIBE _sentinel_:hello
* 如果信息中记录的 Sentinel 运行 ID 与自己的相同,不做进一步处理
* 如果不同,将根据信息中的各个参数,对相应主服务器的实例结构进行更新
-对于监视同一个服务器的多个 Sentinel 来说,**一个 Sentinel 发送的信息会被其他 Sentinel 接收到**,这些信息会被用于更新其他 Sentinel 对发送信息 Sentinel 的认知,也会被用于更新其他 Sentinel 对被监视的服务器的认知
-
-哨兵实例之间可以相互发现,要归功于 Redis 提供发布订阅机制
-
-
-
-***
-
-
-
-##### 更新字典
-
Sentinel 为主服务器创建的实例结构的 sentinels 字典保存所有同样监视这个**主服务器的 Sentinel 信息**(包括 Sentinel 自己),字典的键是 Sentinel 的名字,格式为 `ip:port`,值是键所对应 Sentinel 的实例结构
-当 Sentinel 接收到其他 Sentinel 发来的信息时(发送信息的为源 Sentinel,接收信息的为目标 Sentinel),目标 Sentinel 会分析提取参数,在自己的 Sentinel 状态 sentinelState.masters 中查找相应的主服务器实例结构,检查主服务器实例结构的 sentinels 字典中,源 Sentinel 的实例结构是否存在
+监视同一个服务器的 Sentinel 订阅的频道相同,Sentinel 发送的信息会被其他 Sentinel 接收到(发送信息的为源 Sentinel,接收信息的为目标 Sentinel),目标 Sentinel 在自己的 sentinelState.masters 中查找源 Sentinel 服务器的实例结构进行添加或更新
-* 如果源 Sentinel 的实例结构存在,那么对源 Sentinel 的实例结构进行更新
-* 如果源 Sentinel 的实例结构不存在,说明源 Sentinel 是刚开始监视主服务器,目标 Sentinel 会为源 Sentinel 创建一个新的实例结构,并将这个结构添加到 sentinels 字典里面
+因为 Sentinel 可以接收到的频道信息来感知其他 Sentinel 的存在,并通过发送频道信息来让其他 Sentinel 知道自己的存在,所以用户在使用 Sentinel 时并不需要提供各个 Sentinel 的地址信息,**监视同一个主服务器的多个 Sentinel 可以相互发现对方**
-因为 Sentinel 可以接收到的频道信息来获知其他 Sentinel 的存在,并通过发送频道信息来让其他 Sentinel 知道自己的存在,所以用户在使用 Sentinel 时并不需要提供各个 Sentinel 的地址信息,**监视同一个主服务器的多个 Sentinel 可以自动发现对方**
+哨兵实例之间可以相互发现,要归功于 Redis 提供发布订阅机制
@@ -14664,7 +14614,7 @@ SENTINEL is-master-down-by-addr
源 Sentinel 将统计其他 Sentinel 同意主服务器已下线的数量,当这一数量达到配置指定的判断客观下线所需的数量(quorum)时,Sentinel 会将主服务器对应实例结构 flags 属性的 SRI_O_DOWN 标识打开,代表客观下线,并对主服务器执行故障转移操作
-注意:不同 Sentinel 判断客观下线的条件可能不同,因为载入的配置文件中的属性(quorum)可能不同
+注意:**不同 Sentinel 判断客观下线的条件可能不同**,因为载入的配置文件中的属性 quorum 可能不同
@@ -14674,7 +14624,7 @@ SENTINEL is-master-down-by-addr
### 领头选举
-主服务器被判断为客观下线时,监视这个主服务器的各个 Sentinel 会进行协商,选举出一个领头 Sentinel 对下线服务器执行故障转移
+主服务器被判断为客观下线时,**监视该主服务器的各个 Sentinel 会进行协商**,选举出一个领头 Sentinel 对下线服务器执行故障转移
Redis 选举领头 Sentinel 的规则:
@@ -14683,7 +14633,7 @@ Redis 选举领头 Sentinel 的规则:
* 在一个配置纪元里,所有 Sentinel 都只有一次将某个 Sentinel 设置为局部领头 Sentinel 的机会,并且局部领头一旦设置,在这个配置纪元里就不能再更改
* Sentinel 设置局部领头 Sentinel 的规则是先到先得,最先向目标 Sentinel 发送设置要求的源 Sentinel 将成为目标 Sentinel 的局部领头 Sentinel,之后接收到的所有设置要求都会被目标 Sentinel 拒绝
-* 领头 Sentinel 的产生需要半数以上 Sentinel 的支持,并且每个 Sentinel 只有一票,所以一个配置纪元只会出现一个领头 Sentinel,比如 10 个 Sentinel 的系统中,至少需要 `10/2 + 1 = 6` 票
+* 领头 Sentinel 的产生**需要半数以上 Sentinel 的支持**,并且每个 Sentinel 只有一票,所以一个配置纪元只会出现一个领头 Sentinel,比如 10 个 Sentinel 的系统中,至少需要 `10/2 + 1 = 6` 票
选举过程:
@@ -14691,7 +14641,7 @@ Redis 选举领头 Sentinel 的规则:
* 目标 Sentinel 接受命令处理完成后,将返回一条命令回复,回复中的 leader_runid 和 leader_epoch 参数分别记录了目标 Sentinel 的局部领头 Sentinel 的运行 ID 和配置纪元
* 源 Sentinel 接收目标 Sentinel 命令回复之后,会判断 leader_epoch 是否和自己的相同,相同就继续判断 leader_runid 是否和自己的运行 ID 一致,成立表示目标 Sentinel 将源 Sentinel 设置成了局部领头 Sentinel,即获得一票
* 如果某个 Sentinel 被半数以上的 Sentinel 设置成了局部领头 Sentinel,那么这个 Sentinel 成为领头 Sentinel
-* 如果在给定时限内,没有一个 Sentinel 被选举为领头 Sentinel,那么各个 Sentinel 将在一段时间后再次选举,直到选出领头
+* 如果在给定时限内,没有一个 Sentinel 被选举为领头 Sentinel,那么各个 Sentinel 将在一段时间后**再次选举**,直到选出领头
* 每次进行领头 Sentinel 选举之后,不论选举是否成功,所有 Sentinel 的配置纪元(configuration epoch)都要自增一次
Sentinel 集群至少 3 个节点的原因:
@@ -14699,7 +14649,10 @@ Sentinel 集群至少 3 个节点的原因:
* 如果 Sentinel 集群只有 2 个 Sentinel 节点,则领头选举需要 `2/2 + 1 = 2` 票,如果一个节点挂了,那就永远选不出领头
* Sentinel 集群允许 1 个 Sentinel 节点故障则需要 3 个节点的集群,允许 2 个节点故障则需要 5 个节点集群
+**如何获取哨兵节点的半数数量**?
+* 客观下线是通过配置文件获取的数量,达到 quorum 就客观下线
+* 哨兵数量是通过主节点是实例结构中,保存着监视该主节点的所有哨兵信息,从而获取得到
@@ -14798,7 +14751,8 @@ typedef struct clusterState {
// 集群当前的状态,是在线还是下线
int state;
- // 集群中至少处理着一个槽的节点的数量,为0表示集群目前没有任何节点在处理槽
+ // 集群中至少处理着一个槽的(主)节点的数量,为0表示集群目前没有任何节点在处理槽
+ // 【选举时投票数量超过半数,从这里获取的】
int size;
// 集群节点名单(包括 myself 节点),字典的键为节点的名字,字典的值为节点对应的clusterNode结构
@@ -14894,7 +14848,7 @@ CLUSTER MEET
#### 基本操作
-Redis 集群通过分片的方式来保存数据库中的键值对,集群的整个数据库被分为16384 个槽(slot),数据库中的每个键都属于 16384 个槽中的一个,集群中的每个节点可以处理 0 个或最多 16384 个槽(**每个主节点存储的数据并不一样**)
+Redis 集群通过分片的方式来保存数据库中的键值对,集群的整个数据库被分为 16384 个槽(slot),数据库中的每个键都属于 16384 个槽中的一个,集群中的每个节点可以处理 0 个或最多 16384 个槽(**每个主节点存储的数据并不一样**)
* 当数据库中的 16384 个槽都有节点在处理时,集群处于上线状态(ok)
* 如果数据库中有任何一个槽得到处理,那么集群处于下线状态(fail)
@@ -14979,7 +14933,7 @@ typedef struct clusterState {
#### 集群数据
-集群节点保存键值对以及键值对过期时间的方式,与单机 Redis 服务器保存键值对以及键值对过期时间的方式完全相同,但是集群节点只能使用 0 号数据库,单机服务器可以任意使用
+集群节点保存键值对以及键值对过期时间的方式,与单机 Redis 服务器保存键值对以及键值对过期时间的方式完全相同,但是**集群节点只能使用 0 号数据库**,单机服务器可以任意使用
除了将键值对保存在数据库里面之外,节点还会用 clusterState 结构中的 slots_to_keys 跳跃表来**保存槽和键之间的关系**
@@ -15033,10 +14987,7 @@ def CLUSTER_KEYSLOT(key):
reply_client(slot);
```
-判断槽是否由当前节点负责处理:
-
-* 如果 clusterState.slots[i] 等于 clusterState.myself,那么说明槽 i 由当前节点负责,节点可以执行客户端发送的命令
-* 如果 clusterState.slots[i] 不等于 clusterState.myself,那么说明槽 i 并非由当前节点负责,节点会根据 clusterState.slots[i] 指向的clusterNode 结构所记录的节点 IP 和端口号,向客户端返回 MOVED 错误
+判断槽是否由当前节点负责处理:如果 clusterState.slots[i] 不等于 clusterState.myself,那么说明槽 i 并非由当前节点负责,节点会根据 clusterState.slots[i] 指向的 clusterNode 结构所记录的节点 IP 和端口号,向客户端返回 MOVED 错误
@@ -15101,8 +15052,8 @@ Redis 集群的重新分片操作可以将任意数量已经指派给某个节
Redis 的集群管理软件 redis-trib 负责执行重新分片操作,redis-trib 通过向源节点和目标节点发送命令来进行重新分片操作
-* redis-trib 向目标节点发送 `CLUSTER SETSLOT IMPORTING ` 命令,让目标节点准备好从源节点导入属于槽 slot 的键值对
-* redis-trib 向源节点发送 `CLUSTER SETSLOT MIGRATING ` 命令,让源节点准备好将属于槽 slot 的键值对迁移至目标节点
+* 向目标节点发送 `CLUSTER SETSLOT IMPORTING ` 命令,准备好从源节点导入属于槽 slot 的键值对
+* 向源节点发送 `CLUSTER SETSLOT MIGRATING ` 命令,让源节点准备好将属于槽 slot 的键值对迁移
* redis-trib 向源节点发送 `CLUSTER GETKEYSINSLOT ` 命令,获得最多 count 个属于槽 slot 的键值对的键名
* 对于每个 key,redis-trib 都向源节点发送一个 `MIGRATE 0 [-k ]
- ```
-
- 范例:100 个连接,5000 次请求对应的性能
-
- ```sh
- redis-benchmark -c 100 -n 5000
- ```
+参考文档:https://help.aliyun.com/document_detail/353223.html
- 
-* redis-cli
- monitor:启动服务器调试信息
+***
- ```sh
- monitor
- ```
- slowlog:慢日志
- ```sh
- slowlog [operator] #获取慢查询日志
- ```
+### 慢查询
- * get :获取慢查询日志信息
- * len :获取慢查询日志条目数
- * reset :重置慢查询日志
+确认服务和 Redis 之间的链路是否正常,排除网络原因后进行 Redis 的排查:
- 相关配置:
+* 使用复杂度过高的命令
+* 操作大 key,分配内存和释放内存会比较耗时
+* key 集中过期,导致定时任务需要更长的时间去清理
+* 实例内存达到上限,每次写入新的数据之前,Redis 必须先从实例中踢出一部分数据
- ```sh
- slowlog-log-slower-than 1000 #设置慢查询的时间下线,单位:微妙
- slowlog-max-len 100 #设置慢查询命令对应的日志显示长度,单位:命令数
- ```
+参考文章:https://www.cnblogs.com/traditional/p/15633919.html(非常好)
@@ -16557,227 +16357,6 @@ public class JDBCDemo01 {
-***
-
-
-
-### 工具类
-
-* 配置文件(在 src 下创建 config.properties)
-
- ```properties
- driverClass=com.mysql.jdbc.Driver
- url=jdbc:mysql://192.168.2.184:3306/db14
- username=root
- password=123456
- ```
-
-* 工具类
-
- ```java
- public class JDBCUtils {
- //1.私有构造方法
- private JDBCUtils(){
- };
-
- //2.声明配置信息变量
- private static String driverClass;
- private static String url;
- private static String username;
- private static String password;
- private static Connection con;
-
- //3.静态代码块中实现加载配置文件和注册驱动
- static{
- try{
- //通过类加载器返回配置文件的字节流
- InputStream is = JDBCUtils.class.getClassLoader().
- getResourceAsStream("config.properties");
-
- //创建Properties集合,加载流对象的信息
- Properties prop = new Properties();
- prop.load(is);
-
- //获取信息为变量赋值
- driverClass = prop.getProperty("driverClass");
- url = prop.getProperty("url");
- username = prop.getProperty("username");
- password = prop.getProperty("password");
-
- //注册驱动
- Class.forName(driverClass);
-
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
-
- //4.获取数据库连接的方法
- public static Connection getConnection() {
- try {
- con = DriverManager.getConnection(url,username,password);
- } catch (SQLException e) {
- e.printStackTrace();
- }
- return con;
- }
-
- //5.释放资源的方法
- public static void close(Connection con, Statement stat, ResultSet rs) {
- if(con != null) {
- try {
- con.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
-
- if(stat != null) {
- try {
- stat.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
-
- if(rs != null) {
- try {
- rs.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
- }
- //方法重载,可能没有返回值对象
- public static void close(Connection con, Statement stat) {
- close(con,stat,null);
- }
- }
- ```
-
-
-
-
-****
-
-
-
-### 数据封装
-
-从数据库读取数据并封装成 Student 对象,需要:
-
-- Student 类成员变量对应表中的列
-
-- 所有的基本数据类型需要使用包装类,**以防 null 值无法赋值**
-
- ```java
- public class Student {
- private Integer sid;
- private String name;
- private Integer age;
- private Date birthday;
- ........
- ```
-
-- 数据准备
-
- ```mysql
- -- 创建db14数据库
- CREATE DATABASE db14;
-
- -- 使用db14数据库
- USE db14;
-
- -- 创建student表
- CREATE TABLE student(
- sid INT PRIMARY KEY AUTO_INCREMENT, -- 学生id
- NAME VARCHAR(20), -- 学生姓名
- age INT, -- 学生年龄
- birthday DATE -- 学生生日
- );
-
- -- 添加数据
- INSERT INTO student VALUES (NULL,'张三',23,'1999-09-23'),(NULL,'李四',24,'1998-08-10'),(NULL,'王五',25,'1996-06-06'),(NULL,'赵六',26,'1994-10-20');
- ```
-
-- 操作数据库
-
- ```java
- public class StudentDaoImpl{
- //查询所有学生信息
- @Override
- public ArrayList findAll() {
- //1.
- ArrayList list = new ArrayList<>();
- Connection con = null;
- Statement stat = null;
- ResultSet rs = null;
- try{
- //2.获取数据库连接
- con = JDBCUtils.getConnection();
-
- //3.获取执行者对象
- stat = con.createStatement();
-
- //4.执行sql语句,并且接收返回的结果集
- String sql = "SELECT * FROM student";
- rs = stat.executeQuery(sql);
-
- //5.处理结果集
- while(rs.next()) {
- Integer sid = rs.getInt("sid");
- String name = rs.getString("name");
- Integer age = rs.getInt("age");
- Date birthday = rs.getDate("birthday");
-
- //封装Student对象
- Student stu = new Student(sid,name,age,birthday);
- //将student对象保存到集合中
- list.add(stu);
- }
- } catch(Exception e) {
- e.printStackTrace();
- } finally {
- //6.释放资源
- JDBCUtils.close(con,stat,rs);
- }
- //将集合对象返回
- return list;
- }
-
- //添加学生信息
- @Override
- public int insert(Student stu) {
- Connection con = null;
- Statement stat = null;
- int result = 0;
- try{
- con = JDBCUtils.getConnection();
-
- //3.获取执行者对象
- stat = con.createStatement();
-
- //4.执行sql语句,并且接收返回的结果集
- Date d = stu.getBirthday();
- SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
- String birthday = sdf.format(d);
- String sql = "INSERT INTO student VALUES ('"+stu.getSid()+"','"+stu.getName()+"','"+stu.getAge()+"','"+birthday+"')";
- result = stat.executeUpdate(sql);
-
- } catch(Exception e) {
- e.printStackTrace();
- } finally {
- //6.释放资源
- JDBCUtils.close(con,stat);
- }
- //将结果返回
- return result;
- }
- }
- ```
-
-
-
***
@@ -16856,292 +16435,15 @@ PreparedStatement:预编译 sql 语句的执行者对象,继承 `PreparedSta
-****
-
-
-
-#### 自定义池
-
-DataSource 接口概述:
-
-* java.sql.DataSource 接口:数据源(数据库连接池)
-* Java 中 DataSource 是一个标准的数据源接口,官方提供的数据库连接池规范,连接池类实现该接口
-* 获取数据库连接对象:`Connection getConnection()`
-
-自定义连接池:
-
-```java
-public class MyDataSource implements DataSource{
- //1.定义集合容器,用于保存多个数据库连接对象
- private static List pool = Collections.synchronizedList(new ArrayList());
-
- //2.静态代码块,生成10个数据库连接保存到集合中
- static {
- for (int i = 0; i < 10; i++) {
- Connection con = JDBCUtils.getConnection();
- pool.add(con);
- }
- }
- //3.返回连接池的大小
- public int getSize() {
- return pool.size();
- }
-
- //4.从池中返回一个数据库连接
- @Override
- public Connection getConnection() {
- if(pool.size() > 0) {
- //从池中获取数据库连接
- return pool.remove(0);
- }else {
- throw new RuntimeException("连接数量已用尽");
- }
- }
-}
-```
-
-测试连接池功能:
-
-```java
-public class MyDataSourceTest {
- public static void main(String[] args) throws Exception{
- //创建数据库连接池对象
- MyDataSource dataSource = new MyDataSource();
-
- System.out.println("使用之前连接池数量:" + dataSource.getSize());//10
-
- //获取数据库连接对象
- Connection con = dataSource.getConnection();
- System.out.println(con.getClass());// JDBC4Connection
-
- //查询学生表全部信息
- String sql = "SELECT * FROM student";
- PreparedStatement pst = con.prepareStatement(sql);
- ResultSet rs = pst.executeQuery();
-
- while(rs.next()) {
- System.out.println(rs.getInt("sid") + "\t" + rs.getString("name") + "\t" + rs.getInt("age") + "\t" + rs.getDate("birthday"));
- }
-
- //释放资源
- rs.close();
- pst.close();
- //目前的连接对象close方法,是直接关闭连接,而不是将连接归还池中
- con.close();
-
- System.out.println("使用之后连接池数量:" + dataSource.getSize());//9
- }
-}
-```
-
-结论:释放资源并没有把连接归还给连接池
-
-
-
-***
-
-
-
-#### 归还连接
-
-归还数据库连接的方式:继承方式、装饰者设计者模式、适配器设计模式、动态代理方式
-
-##### 继承方式
-
-继承(无法解决)
-
-- 通过打印连接对象,发现 DriverManager 获取的连接实现类是 JDBC4Connection
-- 自定义一个类,继承 JDBC4Connection 这个类,重写 close() 方法
-- 查看 JDBC 工具类获取连接的方法发现:虽然自定义了一个子类,完成了归还连接的操作。但是 DriverManager 获取的还是 JDBC4Connection 这个对象,并不是我们的子类对象
-
-代码实现
-
-* 自定义继承连接类
-
- ```java
- //1.定义一个类,继承JDBC4Connection
- public class MyConnection1 extends JDBC4Connection{
- //2.定义Connection连接对象和容器对象的成员变量
- private Connection con;
- private List pool;
-
- //3.通过有参构造方法为成员变量赋值
- public MyConnection1(String hostToConnectTo, int portToConnectTo, Properties info, String databaseToConnectTo, String url,Connection con,List pool) throws SQLException {
- super(hostToConnectTo, portToConnectTo, info, databaseToConnectTo, url);
- this.con = con;
- this.pool = pool;
- }
-
- //4.重写close方法,完成归还连接
- @Override
- public void close() throws SQLException {
- pool.add(con);
- }
- }
- ```
-
-* 自定义连接池类
-
- ```java
- //将之前的连接对象换成自定义的子类对象
- private static MyConnection1 con;
-
- //4.获取数据库连接的方法
- public static Connection getConnection() {
- try {
- //等效于:MyConnection1 con = new JDBC4Connection(); 语法错误!
- con = DriverManager.getConnection(url,username,password);
- } catch (SQLException e) {
- e.printStackTrace();
- }
-
- return con;
- }
- ```
-
-
-
-***
-
-
-
-##### 装饰者
-
-自定义类实现 Connection 接口,通过装饰设计模式,实现和 mysql 驱动包中的 Connection 实现类相同的功能
-
-在实现类对每个获取的 Connection 进行装饰:把连接和连接池参数传递进行包装
-特点:通过装饰设计模式连接类我们发现,有很多需要重写的方法,代码太繁琐
-
-* 装饰设计模式类
-
- ```java
- //1.定义一个类,实现Connection接口
- public class MyConnection2 implements Connection {
- //2.定义Connection连接对象和连接池容器对象的变量
- private Connection con;
- private List pool;
-
- //3.提供有参构造方法,接收连接对象和连接池对象,对变量赋值
- public MyConnection2(Connection con,List pool) {
- this.con = con;
- this.pool = pool;
- }
-
- //4.在close()方法中,完成连接的归还
- @Override
- public void close() throws SQLException {
- pool.add(con);
- }
- //5.剩余方法,只需要调用mysql驱动包的连接对象完成即可
- @Override
- public Statement createStatement() throws SQLException {
- return con.createStatement();
- }
- ..........
- }
- ```
-
-* 自定义连接池类
-
- ```java
- @Override
- public Connection getConnection() {
- if(pool.size() > 0) {
- //从池中获取数据库连接
- Connection con = pool.remove(0);
- //通过自定义连接对象进行包装
- MyConnection2 mycon = new MyConnection2(con,pool);
- //返回包装后的连接对象
- return mycon;
- }else {
- throw new RuntimeException("连接数量已用尽");
- }
- }
- ```
-
-
***
-##### 适配器
-
-使用适配器设计模式改进,提供一个适配器类,实现 Connection 接口,将所有功能进行实现(除了 close 方法),自定义连接类只需要继承这个适配器类,重写需要改进的 close() 方法即可。
-
-特点:自定义连接类中很简洁。剩余所有的方法抽取到了适配器类中,但是适配器这个类还是我们自己编写。
-
-* 适配器类
-
- ```java
- public abstract class MyAdapter implements Connection {
-
- // 定义数据库连接对象的变量
- private Connection con;
-
- // 通过构造方法赋值
- public MyAdapter(Connection con) {
- this.con = con;
- }
-
- // 所有的方法,均调用mysql的连接对象实现
- @Override
- public Statement createStatement() throws SQLException {
- return con.createStatement();
- }
- }
- ```
-* 自定义连接类
- ```java
- public class MyConnection3 extends MyAdapter {
- //2.定义Connection连接对象和连接池容器对象的变量
- private Connection con;
- private List pool;
-
- //3.提供有参构造方法,接收连接对象和连接池对象,对变量赋值
- public MyConnection3(Connection con,List pool) {
- super(con); // 将接收的数据库连接对象给适配器父类传递
- this.con = con;
- this.pool = pool;
- }
-
- //4.在close()方法中,完成连接的归还
- @Override
- public void close() throws SQLException {
- pool.add(con);
- }
- }
- ```
-
-* 自定义连接池类
-
- ```java
- //从池中返回一个数据库连接
- @Override
- public Connection getConnection() {
- if(pool.size() > 0) {
- //从池中获取数据库连接
- Connection con = pool.remove(0);
- //通过自定义连接对象进行包装
- MyConnection3 mycon = new MyConnection3(con,pool);
- //返回包装后的连接对象
- return mycon;
- }else {
- throw new RuntimeException("连接数量已用尽");
- }
- }
- ```
-
-
-
-***
-
-
-
-##### 动态代理
+#### 归还连接
使用动态代理的方式来改进
@@ -17326,101 +16628,6 @@ Druid 连接池:
-***
-
-
-
-#### 工具类
-
-数据库连接池的工具类:
-
-```java
-public class DataSourceUtils {
- //1.私有构造方法
- private DataSourceUtils(){}
-
- //2.声明数据源变量
- private static DataSource dataSource;
-
- //3.提供静态代码块,完成配置文件的加载和获取数据库连接池对象
- static{
- try{
- //完成配置文件的加载
- InputStream is = DataSourceUtils.class.getClassLoader().getResourceAsStream("druid.properties");
- Properties prop = new Properties();
- prop.load(is);
-
- //获取数据库连接池对象
- dataSource = DruidDataSourceFactory.createDataSource(prop);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
-
- //4.提供一个获取数据库连接的方法
- public static Connection getConnection() {
- Connection con = null;
- try {
- con = dataSource.getConnection();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- return con;
- }
-
- //5.提供一个获取数据库连接池对象的方法
- public static DataSource getDataSource() {
- return dataSource;
- }
-
- //6.释放资源
- public static void close(Connection con, Statement stat, ResultSet rs) {
- if(con != null) {
- try {
- con.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
-
- if(stat != null) {
- try {
- stat.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
-
- if(rs != null) {
- try {
- rs.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
- }
- //方法重载
- public static void close(Connection con, Statement stat) {
- if(con != null) {
- try {
- con.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
-
- if(stat != null) {
- try {
- stat.close();
- } catch (SQLException e) {
- e.printStackTrace();
- }
- }
- }
-}
-
-```
-
diff --git a/Frame.md b/Frame.md
index 65b948a..f00ae48 100644
--- a/Frame.md
+++ b/Frame.md
@@ -739,9 +739,13 @@ Maven 的插件用来执行生命周期中的相关事件
### 继承
-作用:通过继承可以实现在子工程中沿用父工程中的配置
+Maven 中的继承与 Java 中的继承相似,可以实现在子工程中沿用父工程中的配置
-- Maven 中的继承与 Java 中的继承相似,在子工程中配置继承关系
+dependencyManagement 里只是声明依赖,并不实现引入,所以子工程需要显式声明需要用的依赖
+
+- 如果子工程中未声明依赖,则不会从父项目继承下来
+- 在子工程中声明该依赖项,并且不指定具体版本,才会从父项目中继承该项,version 和 scope 都继承取自父工程 pom 文件
+- 如果子工程中指定了版本号,那么使用子工程中指定的 jar 版本
制作方式:
@@ -1544,9 +1548,9 @@ Reactor 对象通过 select 监控客户端请求事件,收到事件后通过
采用多个 Reactor ,执行流程:
-* Reactor 主线程 MainReactor 通过 select 监控建立连接事件,收到事件后通过 Acceptor 接收,处理建立连接事件,处理完成后 MainReactor 会将连接分配给 Reactor 子线程的 SubReactor(有多个)处理
+* Reactor 主线程 MainReactor 通过 select **监控建立连接事件**,收到事件后通过 Acceptor 接收,处理建立连接事件,处理完成后 MainReactor 会将连接分配给 Reactor 子线程的 SubReactor(有多个)处理
-* SubReactor 将连接加入连接队列进行监听,并创建一个 Handler 用于处理该连接的事件,当有新的事件发生时,SubReactor 会调用连接对应的 Handler 进行响应
+* SubReactor 将连接加入连接队列进行监听其他事件,并创建一个 Handler 用于处理该连接的事件,当有新的事件发生时,SubReactor 会调用连接对应的 Handler 进行响应
* Handler 通过 read 读取数据后,会分发给 Worker 线程池进行业务处理
@@ -3073,7 +3077,7 @@ Protobuf 是以 message 的方式来管理数据,支持跨平台、跨语言
```protobuf
syntax = "proto3"; // 版本
option java_outer_classname = "StudentPOJO"; // 生成的外部类名,同时也是文件名
- // protobuf 使用 message 管理数据
+
message Student { // 在 StudentPOJO 外部类种生成一个内部类 Student,是真正发送的 POJO 对象
int32 id = 1; // Student 类中有一个属性:名字为 id 类型为 int32(protobuf类型) ,1表示属性序号,不是值
string name = 2;
@@ -3435,6 +3439,8 @@ RCVBUF_ALLOCATOR:属于 SocketChannal 参数
### 消息队列
+#### 应用场景
+
消息队列是一种先进先出的数据结构,常见的应用场景:
* 应用解耦:系统的耦合性越高,容错性就越低
@@ -3443,7 +3449,7 @@ RCVBUF_ALLOCATOR:属于 SocketChannal 参数

-* 流量削峰:应用系统如果遇到系统请求流量的瞬间猛增,有可能会将系统压垮,使用消息队列可以将大量请求缓存起来,分散到很长一段时间处理,这样可以提高系统的稳定性和用户体验。
+* 流量削峰:应用系统如果遇到系统请求流量的瞬间猛增,有可能会将系统压垮,使用消息队列可以将大量请求缓存起来,分散到很长一段时间处理,这样可以提高系统的稳定性和用户体验

@@ -3459,6 +3465,36 @@ RCVBUF_ALLOCATOR:属于 SocketChannal 参数
+***
+
+
+
+#### 技术选型
+
+RocketMQ 对比 Kafka 的优点
+
+* 支持 Pull和 Push 两种消息模式
+
+- 支持延时消息、死信队列、消息重试、消息回溯、消息跟踪、事务消息等高级特性
+- 对消息可靠性做了改进,**保证消息不丢失并且至少消费一次**,与 Kafka 一样是先写 PageCache 再落盘,并且数据有多副本
+- RocketMQ 存储模型是所有的 Topic 都写到同一个 Commitlog 里,是一个 append only 操作,在海量 Topic 下也能将磁盘的性能发挥到极致,并且保持稳定的写入时延。Kafka 的吞吐非常高(零拷贝、操作系统页缓存、磁盘顺序写),但是在多 Topic 下时延不够稳定(顺序写入特性会被破坏从而引入大量的随机 I/O),不适合实时在线业务场景
+- 经过阿里巴巴多年双 11 验证过、可以支持亿级并发的开源消息队列
+
+Kafka 比 RocketMQ 吞吐量高:
+
+* Kafka 将 Producer 端将多个小消息合并,采用异步批量发送的机制,当发送一条消息时,消息并没有发送到 Broker 而是缓存起来,直接向业务返回成功,当缓存的消息达到一定数量时再批量发送
+
+* 减少了网络 I/O,提高了消息发送的性能,但是如果消息发送者宕机,会导致消息丢失,降低了可靠性
+* RocketMQ 缓存过多消息会导致频繁 GC,并且为了保证可靠性没有采用这种方式
+
+Topic 的 partition 数量过多时,Kafka 的性能不如 RocketMQ:
+
+* 两者都使用文件存储,但是 Kafka 是一个分区一个文件,Topic 过多时分区的总量也会增加,过多的文件导致对消息刷盘时出现文件竞争磁盘,造成性能的下降。**一个分区只能被一个消费组中的一个消费线程进行消费**,因此可以同时消费的消费端也比较少
+
+* RocketMQ 所有队列都存储在一个文件中,每个队列存储的消息量也比较小,因此多 Topic 的对 RocketMQ 的性能的影响较小
+
+
+
****
@@ -3970,9 +4006,9 @@ Broker 可以配置 messageDelayLevel,该属性是 Broker 的属性,不属
- 1<=level<=maxLevel:消息延迟特定时间,例如 level==1,延迟 1s
- level > maxLevel:则 level== maxLevel,例如 level==20,延迟 2h
-定时消息会暂存在名为 SCHEDULE_TOPIC_XXXX 的 Topic 中,并根据 delayTimeLevel 存入特定的 queue,队列的标识 `queueId = delayTimeLevel – 1`,即**一个 queue 只存相同延迟的消息**,保证具有相同发送延迟的消息能够顺序消费。Broker 会调度地消费 SCHEDULE_TOPIC_XXXX,将消息写入真实的 Topic
+定时消息会暂存在名为 SCHEDULE_TOPIC_XXXX 的 Topic 中,并根据 delayTimeLevel 存入特定的 queue,队列的标识 `queueId = delayTimeLevel – 1`,即**一个 queue 只存相同延迟的消息**,保证具有相同发送延迟的消息能够顺序消费。Broker 会为每个延迟级别提交一个定时任务,调度地消费 SCHEDULE_TOPIC_XXXX,将消息写入真实的 Topic
-注意:定时消息在第一次写入和调度写入真实 Topic 时都会计数,因此发送数量、tps 都会变高。
+注意:定时消息在第一次写入和调度写入真实 Topic 时都会计数,因此发送数量、tps 都会变高
@@ -4555,7 +4591,7 @@ RocketMQ 消息的存储是由 ConsumeQueue 和 CommitLog 配合完成 的,Com
* ConsumerQueue:消息消费队列,存储消息在 CommitLog 的索引。RocketMQ 消息消费时要遍历 CommitLog 文件,并根据主题 Topic 检索消息,这是非常低效的。引入 ConsumeQueue 作为消费消息的索引,**保存了指定 Topic 下的队列消息在 CommitLog 中的起始物理偏移量 offset**,消息大小 size 和消息 Tag 的 HashCode 值,每个 ConsumeQueue 文件大小约 5.72M
* IndexFile:为了消息查询提供了一种通过 Key 或时间区间来查询消息的方法,通过 IndexFile 来查找消息的方法**不影响发送与消费消息的主流程**。IndexFile 的底层存储为在文件系统中实现的 HashMap 结构,故 RocketMQ 的索引文件其底层实现为 **hash 索引**
-RocketMQ 采用的是混合型的存储结构,即为 Broker 单个实例下所有的队列共用一个日志数据文件(CommitLog)来存储。混合型存储结构(多个 Topic 的消息实体内容都存储于一个 CommitLog 中)针对 Producer 和 Consumer 分别采用了**数据和索引部分相分离**的存储结构,Producer 发送消息至 Broker 端,然后 Broker 端使用同步或者异步的方式对消息刷盘持久化,保存至 CommitLog 中。只要消息被持久化至磁盘文件 CommitLog 中,Producer 发送的消息就不会丢失,Consumer 也就肯定有机会去消费这条消息
+RocketMQ 采用的是混合型的存储结构,即为 Broker 单个实例下所有的队列共用一个日志数据文件(CommitLog)来存储,多个 Topic 的消息实体内容都存储于一个 CommitLog 中。混合型存储结构针对 Producer 和 Consumer 分别采用了**数据和索引部分相分离**的存储结构,Producer 发送消息至 Broker 端,然后 Broker 端使用同步或者异步的方式对消息刷盘持久化,保存至 CommitLog 中。只要消息被持久化至磁盘文件 CommitLog 中,Producer 发送的消息就不会丢失,Consumer 也就肯定有机会去消费这条消息
服务端支持长轮询模式,当消费者无法拉取到消息后,可以等下一次消息拉取,Broker 允许等待 30s 的时间,只要这段时间内有新消息到达,将直接返回给消费端。RocketMQ 的具体做法是,使用 Broker 端的后台服务线程 ReputMessageService 不停地分发请求并异步构建 ConsumeQueue(逻辑消费队列)和 IndexFile(索引文件)数据
@@ -4593,7 +4629,7 @@ MappedByteBuffer 内存映射的方式**限制**一次只能映射 1.5~2G 的文
页缓存(PageCache)是 OS 对文件的缓存,每一页的大小通常是 4K,用于加速对文件的读写。因为 OS 将一部分的内存用作 PageCache,所以程序对文件进行顺序读写的速度几乎接近于内存的读写速度
-* 对于数据的写入,OS 会先写入至 Cache 内,随后通过异步的方式由 pdflush 内核线程将 Cache 内的数据刷盘至物理磁盘上
+* 对于数据的写入,OS 会先写入至 Cache 内,随后**通过异步的方式由 pdflush 内核线程将 Cache 内的数据刷盘至物理磁盘上**
* 对于数据的读取,如果一次读取文件时出现未命中 PageCache 的情况,OS 从物理磁盘上访问读取文件的同时,会顺序对其他相邻块的数据文件进行**预读取**(局部性原理,最大 128K)
在 RocketMQ 中,ConsumeQueue 逻辑消费队列存储的数据较少,并且是顺序读取,在 PageCache 机制的预读取作用下,Consume Queue 文件的读性能几乎接近读内存,即使在有消息堆积情况下也不会影响性能。但是 CommitLog 消息存储的日志数据文件读取内容时会产生较多的随机访问读取,严重影响性能。选择合适的系统 IO 调度算法和固态硬盘,比如设置调度算法为 Deadline,随机读的性能也会有所提升
@@ -4627,8 +4663,6 @@ RocketMQ 采用文件系统的方式,无论同步还是异步刷盘,都使
-
-
****
@@ -4698,7 +4732,9 @@ BrokerServer 的高可用通过 Master 和 Slave 的配合:
* Slave 只负责读,当 Master 不可用,对应的 Slave 仍能保证消息被正常消费
* 配置多组 Master-Slave 组,其他的 Master-Slave 组也会保证消息的正常发送和消费
-* 目前不支持把 Slave 自动转成 Master,需要手动停止 Slave 角色的 Broker,更改配置文件,用新的配置文件启动 Broker
+* **目前不支持把 Slave 自动转成 Master**,需要手动停止 Slave 角色的 Broker,更改配置文件,用新的配置文件启动 Broker
+
+ 所以需要配置多个 Master 保证可用性,否则一个 Master 挂了导致整体系统的写操作不可用
生产端的高可用:在创建 Topic 的时候,把 Topic 的**多个 Message Queue 创建在多个 Broker 组**上(相同 Broker 名称,不同 brokerId 的机器),当一个 Broker 组的 Master 不可用后,其他组的 Master 仍然可用,Producer 仍然可以发送消息
@@ -4716,7 +4752,7 @@ BrokerServer 的高可用通过 Master 和 Slave 的配合:
如果一个 Broker 组有 Master 和 Slave,消息需要从 Master 复制到 Slave 上,有同步和异步两种复制方式:
-* 同步复制方式:Master 和 Slave 均写成功后才反馈给客户端写成功状态。在同步复制方式下,如果 Master 出故障, Slave 上有全部的备份数据,容易恢复,但是同步复制会增大数据写入延迟,降低系统吞吐量
+* 同步复制方式:Master 和 Slave 均写成功后才反馈给客户端写成功状态(写 Page Cache)。在同步复制方式下,如果 Master 出故障, Slave 上有全部的备份数据,容易恢复,但是同步复制会增大数据写入延迟,降低系统吞吐量
* 异步复制方式:只要 Master 写成功,即可反馈给客户端写成功状态,系统拥有较低的延迟和较高的吞吐量,但是如果 Master 出了故障,有些数据因为没有被写入 Slave,有可能会丢失
@@ -4737,6 +4773,8 @@ RocketMQ 支持消息的高可靠,影响消息可靠性的几种情况:
后两种属于单点故障,且无法恢复,一旦发生,在此单点上的消息全部丢失。RocketMQ 在这两种情况下,通过主从异步复制,可保证 99% 的消息不丢,但是仍然会有极少量的消息可能丢失。通过**同步双写技术**可以完全避免单点,但是会影响性能,适合对消息可靠性要求极高的场合,RocketMQ 从 3.0 版本开始支持同步双写
+一般而言,我们会建议采取同步双写 + 异步刷盘的方式,在消息的可靠性和性能间有一个较好的平衡
+
****
@@ -4786,7 +4824,7 @@ LatencyFaultTolerance 机制是实现消息发送高可用的核心关键所在

-集群模式下,**queue 都是只允许分配只一个实例**,如果多个实例同时消费一个 queue 的消息,由于拉取哪些消息是 Consumer 主动控制的,会导致同一个消息在不同的实例下被消费多次
+集群模式下,**queue 都是只允许分配一个实例**,如果多个实例同时消费一个 queue 的消息,由于拉取哪些消息是 Consumer 主动控制的,会导致同一个消息在不同的实例下被消费多次
通过增加 Consumer 实例去分摊 queue 的消费,可以起到水平扩展的消费能力的作用。而当有实例下线时,会重新触发负载均衡,这时候原来分配到的 queue 将分配到其他实例上继续消费。但是如果 Consumer 实例的数量比 Message Queue 的总数量还多的话,多出来的 Consumer 实例将无法分到 queue,也就无法消费到消息,也就无法起到分摊负载的作用了,所以需要**控制让 queue 的总数量大于等于 Consumer 的数量**
@@ -4802,7 +4840,7 @@ LatencyFaultTolerance 机制是实现消息发送高可用的核心关键所在
Consumer 端实现负载均衡的核心类 **RebalanceImpl**
-在 Consumer 实例的启动流程中的会启动 MQClientInstance 实例,完成负载均衡服务线程 RebalanceService 的启动(每隔 20s 执行一次),RebalanceService 线程的 run() 方法最终调用的是 RebalanceImpl 类的 rebalanceByTopic() 方法,该方法是实现 Consumer 端负载均衡的核心。rebalanceByTopic() 方法会根据消费者通信类型为广播模式还是集群模式做不同的逻辑处理。这里主要看下集群模式下的处理流程:
+在 Consumer 实例的启动流程中的会启动 MQClientInstance 实例,完成负载均衡服务线程 RebalanceService 的启动(**每隔 20s 执行一次**负载均衡),RebalanceService 线程的 run() 方法最终调用的是 RebalanceImpl 类的 rebalanceByTopic() 方法,该方法是实现 Consumer 端负载均衡的核心。rebalanceByTopic() 方法会根据广播模式还是集群模式做不同的逻辑处理。主要看集群模式:
* 从 rebalanceImpl 实例的本地缓存变量 topicSubscribeInfoTable 中,获取该 Topic 主题下的消息消费队列集合 mqSet
@@ -4822,7 +4860,7 @@ Consumer 端实现负载均衡的核心类 **RebalanceImpl**
对比下 RebalancePushImpl 和 RebalancePullImpl 两个实现类的 dispatchPullRequest() 方法,RebalancePullImpl 类里面的该方法为空
-消息消费队列在同一消费组不同消费者之间的负载均衡,其核心设计理念是在**一个消息消费队列在同一时间只允许被同一消费组内的一个消费者消费,一个消息消费者能同时消费多个消息队列**
+消息消费队列在**同一消费组不同消费者之间的负载均衡**,其核心设计理念是在**一个消息消费队列在同一时间只允许被同一消费组内的一个消费者消费,一个消息消费者能同时消费多个消息队列**
@@ -4883,7 +4921,7 @@ IndexFile 文件的存储在 `$HOME\store\index${fileName}`,文件名 fileName
#### 消息重投
-生产者在发送消息时,同步消息和异步消息失败会重投,oneway 没有任何保证。消息重投保证消息尽可能发送成功、不丢失,但当出现消息量大、网络抖动时,可能会造成消息重复;生产者主动重发、Consumer 负载变化也会导致重复消息。
+生产者在发送消息时,同步消息和异步消息失败会重投,oneway 没有任何保证。消息重投保证消息尽可能发送成功、不丢失,但当出现消息量大、网络抖动时,可能会造成消息重复;生产者主动重发、Consumer 负载变化也会导致重复消息
如下方法可以设置消息重投策略:
@@ -4915,7 +4953,7 @@ RocketMQ 会为每个消费组都设置一个 Topic 名称为 `%RETRY%+consumerG
* 无序消息(普通、定时、延时、事务消息)的重试,可以通过设置返回状态达到消息重试的结果。无序消息的重试只针对集群消费方式生效,广播方式不提供失败重试特性,即消费失败后,失败消息不再重试,继续消费新的消息
-**无序消息情况下**,因为异常恢复需要一些时间,会为重试队列设置多个重试级别,每个重试级别都有对应的重新投递延时,重试次数越多投递延时就越大。RocketMQ 对于重试消息的处理是先保存至 Topic 名称为 `SCHEDULE_TOPIC_XXXX` 的延迟队列中,后台定时任务按照对应的时间进行 Delay 后重新保存至 `%RETRY%+consumerGroup` 的重试队列中
+**无序消息情况下**,因为异常恢复需要一些时间,会为重试队列设置多个重试级别,每个重试级别都有对应的重新投递延时,重试次数越多投递延时就越大。RocketMQ 对于重试消息的处理是先保存至 Topic 名称为 `SCHEDULE_TOPIC_XXXX` 的延迟队列中,后台定时任务**按照对应的时间进行 Delay 后**重新保存至 `%RETRY%+consumerGroup` 的重试队列中
消息队列 RocketMQ 默认允许每条消息最多重试 16 次,每次重试的间隔时间如下表示:
@@ -5045,6 +5083,31 @@ public class MessageListenerImpl implements MessageListener {
+***
+
+
+
+### 高可靠性
+
+RocketMQ 消息丢失可能发生在以下三个阶段:
+
+- 生产阶段:消息在 Producer 发送端创建出来,经过网络传输发送到 Broker 存储端
+ - 生产者得到一个成功的响应,就可以认为消息的存储和消息的消费都是可靠的
+ - 消息重投机制
+- 存储阶段:消息在 Broker 端存储,如果是主备或者多副本,消息会在这个阶段被复制到其他的节点或者副本上
+ - 单点:刷盘机制(同步或异步)
+ - 主从:消息同步机制(异步复制或同步双写,主从复制章节详解)
+ - 过期删除:操作 CommitLog、ConsumeQueue 文件是基于文件内存映射机制,并且在启动的时候会将所有的文件加载,为了避免内存与磁盘的浪费,让磁盘能够循环利用,防止磁盘不足导致消息无法写入等引入了文件过期删除机制。最终使得磁盘水位保持在一定水平,最终保证新写入消息的可靠存储
+- 消费阶段:Consumer 消费端从 Broker存储端拉取消息,经过网络传输发送到 Consumer 消费端上
+ - 消息重试机制来最大限度的保证消息的消费
+ - 消费失败的进行消息回退,重试次数过多的消息放入死信队列
+
+
+
+推荐文章:https://cdn.modb.pro/db/394751
+
+
+
****
@@ -7374,7 +7437,7 @@ AllocateMappedFileService **创建 MappedFile 服务**
ReputMessageService 消息分发服务,用于构**建 ConsumerQueue 和 IndexFile 文件**
-* run():**循环执行 doReput 方法**,所以发送的消息存储进 CL 就可以产生对应的 CQ,每执行一次线程休眠 1 毫秒
+* run():**循环执行 doReput 方法**,**所以发送的消息存储进 CL 就可以产生对应的 CQ**,每执行一次线程休眠 1 毫秒
```java
public void run()
@@ -7566,7 +7629,7 @@ public GetMessageResult getMessage(final String group, final String topic, final
`if ((bufferTotal + sizePy) > ...)`:热数据一次 pull 请求最大允许获取 256kb 的消息
- `if (messageTotal > ...)`:冷数据一次 pull 请求最大允许获取32 条消息
+ `if (messageTotal > ...)`:冷数据一次 pull 请求最大允许获取 32 条消息
* `if (messageFilter != null)`:按照消息 tagCode 进行过滤
@@ -10209,16 +10272,17 @@ ConsumeRequest 是 ConsumeMessageOrderlyService 的内部类,是一个 Runnabl
生产流程:
-* 首先获取当前消息主题的发布信息,获取不到去 Namesrv 获取(默认有 TBW102),并将获取的到的路由数据转化为发布数据,**创建 MQ 队列**,客户端实例同样更新订阅数据,创建 MQ 队列,放入负载均衡服务 topicSubscribeInfoTable 中
+* 首先获取当前消息主题的发布信息,获取不到去 Namesrv 获取(默认有 TBW102),并将获取的到的路由数据转化为发布数据,**创建 MQ 队列在多个 Broker 组**(一组代表一主多从的 Broker 架构),客户端实例同样更新订阅数据,创建 MQ 队列,放入负载均衡服务 topicSubscribeInfoTable 中
* 然后从发布数据中选择一个 MQ 队列发送消息
-* Broker 端通过 SendMessageProcessor 对发送的消息进行持久化处理,存储到 CommitLog。将重试次数过多的消息加入死信队列,将延迟消息的主题和队列修改为调度主题和调度队列 ID
+* Broker 端通过 SendMessageProcessor 对发送的消息进行持久化处理,存储到 CommitLog。将重试次数过多的消息加入**死信队列**,将延迟消息的主题和队列修改为调度主题和调度队列 ID
* Broker 启动 ScheduleMessageService 服务会为每个延迟级别创建一个延迟任务,让延迟消息得到有效的处理,将到达交付时间的消息修改为原始主题的原始 ID 存入 CommitLog,消费者就可以进行消费了
消费流程:
+* 消息消费队列 ConsumerQueue 存储消息在 CommitLog 的索引,消费者通过该队列来读取消息实体内容,一个 MQ 就对应一个 CQ
* 首先通过负载均衡服务,将分配到当前消费者实例的 MQ 创建 PullRequest,并放入 PullMessageService 的本地阻塞队列内
* PullMessageService 循环从阻塞队列获取请求对象,发起拉消息请求,并创建 PullCallback 回调对象,将正常拉取的消息**提交到消费任务线程池**,并设置请求的下一次拉取位点,重新放入阻塞队列,形成闭环
-* 消费任务服务对消费失败的消息进行回退,回退失败的消息会再次提交消费任务重新消费
+* 消费任务服务对消费失败的消息进行回退,通过内部生产者实例发送回退消息,回退失败的消息会再次提交消费任务重新消费
* Broker 端对拉取消息的请求进行处理(processRequestCommand),查询成功将消息放入响应体,通过 Netty 写回客户端,当 `pullRequest.offset == queue.maxOffset` 说明该队列已经没有需要获取的消息,将请求放入长轮询集合等待有新消息
* PullRequestHoldService 负责长轮询,每 5 秒遍历一次长轮询集合,将满足条件的 PullRequest 再次提交到线程池内处理
@@ -10519,7 +10583,7 @@ Zookeepe 集群三个角色:
* Epoch:每个 Leader 任期的代号,同一轮选举投票过程中的该值是相同的,投完一次票就增加
-选举机制:半数机制,超过半数的投票旧通过
+选举机制:半数机制,超过半数的投票就通过
* 第一次启动选举规则:投票过半数时,服务器 ID 大的胜出
@@ -10712,7 +10776,7 @@ CAP 理论指的是在一个分布式系统中,Consistency(一致性)、Av
CAP 三个基本需求,因为 P 是必须的,因此分布式系统选择就在 CP 或者 AP 中:
* 一致性:指数据在多个副本之间是否能够保持数据一致的特性,当一个系统在数据一致的状态下执行更新操作后,也能保证系统的数据仍然处于一致的状态
-* 可用性:指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果
+* 可用性:指系统提供的服务必须一直处于可用的状态,即使集群中一部分节点故障,对于用户的每一个操作请求总是能够在有限的时间内返回结果
* 分区容错性:分布式系统在遇到任何网络分区故障时,仍然能够保证对外提供服务,不会宕机,除非是整个网络环境都发生了故障
@@ -11223,7 +11287,7 @@ FastLeaderElection 中有 WorkerReceiver 线程
-### 状态同步
+#### 状态同步
选举结束后,每个节点都需要根据角色更新自己的状态,Leader 更新状态为 Leader,其他节点更新状态为 Follower,整体流程:
diff --git a/Java.md b/Java.md
index 26fbec9..23a9e8b 100644
--- a/Java.md
+++ b/Java.md
@@ -6,25 +6,22 @@
#### 变量类型
-| | 成员变量 | 局部变量 | 静态变量 |
-| :------: | :------------: | :------------------------: | :-------------------------: |
-| 定义位置 | 在类中,方法外 | 方法中或者方法的形参 | 在类中,方法外 |
-| 初始化值 | 有默认初始化值 | 无,先定义,赋值后才能使用 | 有默认初始化值 |
-| 调用方法 | 对象调用 | | 对象调用,类名调用 |
-| 存储位置 | 堆中 | 栈中 | 方法区(JDK8 以后移到堆中) |
-| 生命周期 | 与对象共存亡 | 与方法共存亡 | 与类共存亡 |
-| 别名 | 实例变量 | | 类变量,静态成员变量 |
+| | 成员变量 | 局部变量 | 静态变量 |
+| :------: | :------------: | :------------------: | :-------------------------: |
+| 定义位置 | 在类中,方法外 | 方法中或者方法的形参 | 在类中,方法外 |
+| 初始化值 | 有默认初始化值 | 无,赋值后才能使用 | 有默认初始化值 |
+| 调用方法 | 对象调用 | | 对象调用,类名调用 |
+| 存储位置 | 堆中 | 栈中 | 方法区(JDK8 以后移到堆中) |
+| 生命周期 | 与对象共存亡 | 与方法共存亡 | 与类共存亡 |
+| 别名 | 实例变量 | | 类变量,静态成员变量 |
-**静态变量只有一个,成员变量是类中的变量,局部变量是方法中的变量**
+静态变量只有一个,成员变量是类中的变量,局部变量是方法中的变量
-初学时笔记内容参考视频:https://www.bilibili.com/video/BV1TE41177mP,随着学习的深入又增加了很多知识
+初学时笔记内容参考视频:https://www.bilibili.com/video/BV1TE41177mP,随着学习的深入又增加很多知识
-给初学者的一些个人建议:
-* 初学者对编程的认知比较浅显,一些专有词汇和概念难以理解,所以建议观看视频进行入门,大部分公开课视频讲的比较基础
-* 在有了一定的编程基础后,需要看一些经典书籍和技术博客,来扩容自己的知识广度和深度,可以长期保持记录笔记的好习惯
@@ -40,9 +37,8 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
**byte:**
-- byte 数据类型是 8 位、有符号的,以**二进制补码**表示的整数,**8 位一个字节**,首位是符号位
-- 最小值是 -128(-2^7)
-- 最大值是 127(2^7-1)
+- byte 数据类型是 8 位、有符号的,以二进制补码表示的整数,**8 位一个字节**,首位是符号位
+- 最小值是 -128(-2^7)、最大值是 127(2^7-1)
- 默认值是 `0`
- byte 类型用在大型数组中节约空间,主要代替整数,byte 变量占用的空间只有 int 类型的四分之一
- 例子:`byte a = 100,byte b = -50`
@@ -50,8 +46,7 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
**short:**
- short 数据类型是 16 位、有符号的以二进制补码表示的整数
-- 最小值是 -32768(-2^15)
-- 最大值是 32767(2^15 - 1)
+- 最小值是 -32768(-2^15)、最大值是 32767(2^15 - 1)
- short 数据类型也可以像 byte 那样节省空间,一个 short 变量是 int 型变量所占空间的二分之一
- 默认值是 `0`
- 例子:`short s = 1000,short r = -20000`
@@ -59,8 +54,7 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
**int:**
- int 数据类型是 32 位 4 字节、有符号的以二进制补码表示的整数
-- 最小值是 -2,147,483,648(-2^31)
-- 最大值是 2,147,483,647(2^31 - 1)
+- 最小值是 -2,147,483,648(-2^31)、最大值是 2,147,483,647(2^31 - 1)
- 一般地整型变量默认为 int 类型
- 默认值是 `0`
- 例子:`int a = 100000, int b = -200000`
@@ -68,12 +62,10 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
**long:**
- long 数据类型是 64 位 8 字节、有符号的以二进制补码表示的整数
-- 最小值是 -9,223,372,036,854,775,808(-2^63)
-- 最大值是 9,223,372,036,854,775,807(2^63 -1)
+- 最小值是 -9,223,372,036,854,775,808(-2^63)、最大值是 9,223,372,036,854,775,807(2^63 -1)
- 这种类型主要使用在需要比较大整数的系统上
- 默认值是 ` 0L`
-- 例子: `long a = 100000L,Long b = -200000L`
- L 理论上不分大小写,但是若写成 I 容易与数字 1 混淆,不容易分辩,所以最好大写
+- 例子: `long a = 100000L,Long b = -200000L`,L 理论上不分大小写,但是若写成 I 容易与数字 1 混淆,不容易分辩
**float:**
@@ -104,7 +96,7 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
- char 类型是一个单一的 16 位**两个字节**的 Unicode 字符
- 最小值是 `\u0000`(即为 0)
- 最大值是 `\uffff`(即为 65535)
-- char 数据类型可以存储任何字符
+- char 数据类型可以**存储任何字符**
- 例子:`char c = 'A'`,`char c = '张'`
@@ -117,7 +109,7 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
* float 与 double:
- Java 不能隐式执行**向下转型**,因为这会使得精度降低(参考多态),但是可以向上转型
+ Java 不能隐式执行**向下转型**,因为这会使得精度降低,但是可以向上转型
```java
//1.1字面量属于double类型,不能直接将1.1直接赋值给 float 变量,因为这是向下转型
@@ -146,7 +138,7 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
字面量 1 是 int 类型,比 short 类型精度要高,因此不能隐式地将 int 类型向下转型为 short 类型
- 使用 += 或者 ++ 运算符会执行隐式类型转换:
+ 使用 += 或者 ++ 运算符会执行类型转换:
```java
short s1 = 1;
@@ -177,12 +169,12 @@ Java 语言提供了八种基本类型。六种数字类型(四个整数型,
基本数据类型 包装类(引用数据类型)
byte Byte
short Short
-int Integer(特殊)
+int Integer
long Long
float Float
double Double
-char Character(特殊)
+char Character
boolean Boolean
```
Java 为包装类做了一些特殊功能,具体来看特殊功能主要有:
@@ -209,17 +201,15 @@ Java 为包装类做了一些特殊功能,具体来看特殊功能主要有:
String itStr1 = Integer.toString(it);
System.out.println(itStr1+1);//1001
// c.直接把基本数据类型+空字符串就得到了字符串。
- String itStr2 = it+"";
+ String itStr2 = it + "";
System.out.println(itStr2+1);// 1001
- // 2.把字符串类型的数值转换成对应的基本数据类型的值。(真的很有用)
+ // 2.把字符串类型的数值转换成对应的基本数据类型的值
String numStr = "23";
- //int numInt = Integer.parseInt(numStr);
int numInt = Integer.valueOf(numStr);
System.out.println(numInt+1);//24
String doubleStr = "99.9";
- //double doubleDb = Double.parseDouble(doubleStr);
double doubleDb = Double.valueOf(doubleStr);
System.out.println(doubleDb+0.1);//100.0
}
@@ -329,7 +319,7 @@ new Integer(123) 与 Integer.valueOf(123) 的区别在于:
System.out.println(z == k); // true
```
-valueOf() 方法的实现比较简单,就是先判断值是否在缓存池中,如果在的话就直接返回缓存池的内容。编译器会在自动装箱过程调用 valueOf() 方法,因此多个值相同且值在缓存池范围内的 Integer 实例使用自动装箱来创建,那么就会引用相同的对象。
+valueOf() 方法的实现比较简单,就是先判断值是否在缓存池中,如果在的话就直接返回缓存池的内容。编译器会在自动装箱过程调用 valueOf() 方法,因此多个值相同且值在缓存池范围内的 Integer 实例使用自动装箱来创建,那么就会引用相同的对象
**基本类型对应的缓存池如下:**
@@ -340,7 +330,7 @@ valueOf() 方法的实现比较简单,就是先判断值是否在缓存池中
- Integer values between -128 and 127
- Character in the range \u0000 to \u007F (0 and 127)
-在 jdk 1.8 所有的数值类缓冲池中,**Integer 的缓存池 IntegerCache 很特殊,这个缓冲池的下界是 -128,上界默认是 127**,但是上界是可调的,在启动 JVM 时通过 `AutoBoxCacheMax=` 来指定这个缓冲池的大小,该选项在 JVM 初始化的时候会设定一个名为 java.lang.IntegerCache.high 系统属性,然后 IntegerCache 初始化的时候就会读取该系统属性来决定上界
+在 jdk 1.8 所有的数值类缓冲池中,**Integer 的缓存池 IntegerCache 很特殊,这个缓冲池的下界是 -128,上界默认是 127**,但是上界是可调的,在启动 JVM 时通过 `AutoBoxCacheMax=` 来指定这个缓冲池的大小,该选项在 JVM 初始化的时候会设定一个名为 java.lang.Integer.IntegerCache 系统属性,然后 IntegerCache 初始化的时候就会读取该系统属性来决定上界
```java
Integer x = 100; // 自动装箱,底层调用 Integer.valueOf(1)
@@ -417,7 +407,7 @@ public static void main(String[] args) {
#### 元素访问
-* **索引**:每一个存储到数组的元素,都会自动的拥有一个编号,从 **0** 开始。这个自动编号称为数组索引(index),可以通过数组的索引访问到数组中的元素。
+* **索引**:每一个存储到数组的元素,都会自动的拥有一个编号,从 **0** 开始。这个自动编号称为数组索引(index),可以通过数组的索引访问到数组中的元素
* **访问格式**:数组名[索引],`arr[0]`
* **赋值:**`arr[0] = 10`
@@ -430,7 +420,7 @@ public static void main(String[] args) {
#### 内存分配
-内存是计算机中的重要器件,临时存储区域,作用是运行程序。我们编写的程序是存放在硬盘中,在硬盘中的程序是不会运行的,必须放进内存中才能运行,运行完毕后会清空内存。 Java 虚拟机要运行程序,必须要对内存进行空间的分配和管理。
+内存是计算机中的重要器件,临时存储区域,作用是运行程序。编写的程序是存放在硬盘中,在硬盘中的程序是不会运行的,必须放进内存中才能运行,运行完毕后会清空内存,Java 虚拟机要运行程序,必须要对内存进行空间的分配和管理
| 区域名称 | 作用 |
| ---------- | ---------------------------------------------------------- |
@@ -440,7 +430,7 @@ public static void main(String[] args) {
| 堆内存 | 存储对象或者数组,new 来创建的,都存储在堆内存 |
| 方法栈 | 方法运行时使用的内存,比如 main 方法运行,进入方法栈中执行 |
-**内存分配图**:Java 内存分配
+内存分配图:**Java 数组分配在堆内存**
* 一个数组内存图
@@ -475,9 +465,9 @@ public static void main(String[] args) {
}
```
- arr = null,表示变量 arr 将不再保存数组的内存地址,也就不允许再操作数组,因此运行的时候会抛出空指针异常。在开发中,空指针异常是不能出现的,一旦出现了,就必须要修改编写的代码。
+ arr = null,表示变量 arr 将不再保存数组的内存地址,也就不允许再操作数组,因此运行的时候会抛出空指针异常。在开发中,空指针异常是不能出现的,一旦出现了,就必须要修改编写的代码
- 解决方案:给数组一个真正的堆内存空间引用即可!
+ 解决方案:给数组一个真正的堆内存空间引用即可
@@ -491,14 +481,12 @@ public static void main(String[] args) {
初始化:
-* 动态初始化:
-
- 数据类型[][] 变量名 = new 数据类型[m] [n] : `int[][] arr = new int[3][3]`
+* 动态初始化:数据类型[][] 变量名 = new 数据类型[m] [n],`int[][] arr = new int[3][3]`
* m 表示这个二维数组,可以存放多少个一维数组,行
* n 表示每一个一维数组,可以存放多少个元素,列
* 静态初始化
- * 数据类型[][] 变量名 = new 数据类型[][]{ {元素1, 元素2...} , {元素1, 元素2...}
+ * 数据类型[][] 变量名 = new 数据类型 [][]{{元素1, 元素2...} , {元素1, 元素2...}
* 数据类型[][] 变量名 = {{元素1, 元素2...}, {元素1, 元素2...}...}
* `int[][] arr = {{11,22,33}, {44,55,66}}`
@@ -537,20 +525,20 @@ public class Test1 {
### 运算
* i++ 与 ++i 的区别?
- i++ 表示先将 i 放在表达式中运算,然后再加 1
- ++i 表示先将 i 加 1,然后再放在表达式中运算
+
+ i++ 表示先将 i 放在表达式中运算,然后再加 1,++i 表示先将 i 加 1,然后再放在表达式中运算
* || 和 |,&& 和& 的区别,逻辑运算符
- **& 和| 称为布尔运算符,位运算符。&& 和 || 称为条件布尔运算符,也叫短路运算符**。
+ **& 和| 称为布尔运算符,位运算符;&& 和 || 称为条件布尔运算符,也叫短路运算符**
如果 && 运算符的第一个操作数是 false,就不需要考虑第二个操作数的值了,因为无论第二个操作数的值是什么,其结果都是 false;同样,如果第一个操作数是 true,|| 运算符就返回 true,无需考虑第二个操作数的值;但 & 和 | 却不是这样,它们总是要计算两个操作数。为了提高性能,**尽可能使用 && 和 || 运算符**
-* ^ 异或:两位相异为 1,相同为 0,又叫不进位加法。同或:两位相同为 1,相异为 0
+* 异或 ^:两位相异为 1,相同为 0,又叫不进位加法
-* switch
+* 同或:两位相同为 1,相异为 0
- 从 Java 7 开始,可以在 switch 条件判断语句中使用 String 对象
+* switch:从 Java 7 开始,可以在 switch 条件判断语句中使用 String 对象
```java
String s = "a";
@@ -570,11 +558,9 @@ public class Test1 {
* break:跳出一层循环
-* 移位运算
+* 移位运算:计算机里一般用**补码表示数字**,正数、负数的表示区别就是最高位是 0 还是 1
- 计算机里一般用**补码表示数字**,正数、负数的表示区别就是最高位是 0 还是 1
-
- * 正数的原码反码补码相同
+ * 正数的原码反码补码相同,最高位为 0
```java
100: 00000000 00000000 00000000 01100100
@@ -583,7 +569,7 @@ public class Test1 {
* 负数:
原码:最高位为 1,其余位置和正数相同
反码:保证符号位不变,其余位置取反
- 补码:保证符号位不变,其余位置取反加 1,即反码 +1
+ 补码:保证符号位不变,其余位置取反后加 1,即反码 +1
```java
-100 原码: 10000000 00000000 00000000 01100100 //32位
@@ -636,7 +622,7 @@ public class Test1 {
格式:数据类型... 参数名称
-作用:传输参数非常灵活,方便,可以不传输参数、传输一个参数、或者传输一个数组。
+作用:传输参数非常灵活,可以不传输参数、传输一个参数、或者传输一个数组
可变参数的注意事项:
@@ -837,7 +823,7 @@ public class MethodDemo {
Java 的参数是以**值传递**的形式传入方法中
-值传递和引用传递的区别在于传递后会不会影响实参的值:值传递会创建副本,引用传递不会创建副本
+值传递和引用传递的区别在于传递后会不会影响实参的值:**值传递会创建副本**,引用传递不会创建副本
* 基本数据类型:形式参数的改变,不影响实际参数
@@ -996,11 +982,11 @@ Debug 是供程序员使用的程序调试工具,它可以用于查看程序
### 概述
-**Java 是一种面向对象的高级编程语言。**
+Java 是一种面向对象的高级编程语言
-**三大特征:封装,继承,多态**
+面向对象三大特征:**封装,继承,多态**
-面向对象最重要的两个概念:类和对象
+两个概念:类和对象
* 类:相同事物共同特征的描述,类只是学术上的一个概念并非真实存在的,只能描述一类事物
* 对象:是真实存在的实例, 实例 == 对象,**对象是类的实例化**
@@ -1198,11 +1184,11 @@ Java 是通过成员变量是否有 static 修饰来区分是类的还是属于
内存问题:
-* **栈内存存放 main 方法和地址**
+* 栈内存存放 main 方法和地址
-* **堆内存存放对象和变量**
+* 堆内存存放对象和变量
-* **方法区存放 class 和静态变量(jdk8 以后移入堆)**
+* 方法区存放 class 和静态变量(jdk8 以后移入堆)
访问问题:
@@ -1210,7 +1196,7 @@ Java 是通过成员变量是否有 static 修饰来区分是类的还是属于
* 实例方法是否可以直接访问静态成员变量?可以,静态成员变量可以被共享访问
* 实例方法是否可以直接访问实例方法? 可以,实例方法和实例方法都属于对象
* 实例方法是否可以直接访问静态方法?可以,静态方法可以被共享访问
-* 静态方法是否可以直接访问实例变量? 不可以,实例变量必须用对象访问!!
+* 静态方法是否可以直接访问实例变量? 不可以,实例变量**必须用对象访问**!!
* 静态方法是否可以直接访问静态变量? 可以,静态成员变量可以被共享访问。
* 静态方法是否可以直接访问实例方法? 不可以,实例方法必须用对象访问!!
* 静态方法是否可以直接访问静态方法?可以,静态方法可以被共享访问!!
@@ -1256,7 +1242,7 @@ Java 是通过成员变量是否有 static 修饰来区分是类的还是属于
* 子类不能继承父类的构造器,子类有自己的构造器
* 子类是不能可以继承父类的私有成员的,可以反射暴力去访问继承自父类的私有成员
-* 子类是不能继承父类的静态成员的,子类只是可以访问父类的静态成员,父类静态成员只有一份可以被子类共享访问,**共享并非继承**
+* 子类是不能继承父类的静态成员,父类静态成员只有一份可以被子类共享访问,**共享并非继承**
```java
public class ExtendsDemo {
@@ -1267,8 +1253,10 @@ public class ExtendsDemo {
System.out.println(Cat.schoolName);
}
}
+
class Cat extends Animal{
}
+
class Animal{
public static String schoolName ="seazean";
public static void test(){}
@@ -1295,6 +1283,7 @@ public class ExtendsDemo {
w.showName();
}
}
+
class Wolf extends Animal{
private String name = "子类狼";
public void showName(){
@@ -1327,7 +1316,7 @@ class Animal{
方法重写的校验注解:@Override
-* 方法加了这个注解,那就必须是成功重写父类的方法,否则报错
+* 方法加了这个注解,那就必须是成功重写父类的方法,否则报错
* @Override 优势:可读性好,安全,优雅
**子类可以扩展父类的功能,但不能改变父类原有的功能**,重写有以下三个限制:
@@ -1432,11 +1421,11 @@ class Animal{
* this 代表了当前对象的引用(继承中指代子类对象):this.子类成员变量、this.子类成员方法、**this(...)** 可以根据参数匹配访问本类其他构造器
* super 代表了父类对象的引用(继承中指代了父类对象空间):super.父类成员变量、super.父类的成员方法、super(...) 可以根据参数匹配访问父类的构造器
-**注意:**
+注意:
-* this(...) 借用本类其他构造器,super(...) 调用父类的构造器。
-* this(...) 或 super(...) 必须放在构造器的第一行,否则报错!
-* this(...) 和 super(...) 不能同时出现在构造器中,因为构造函数必须出现在第一行上,只能选择一个。
+* this(...) 借用本类其他构造器,super(...) 调用父类的构造器
+* this(...) 或 super(...) 必须放在构造器的第一行,否则报错
+* this(...) 和 super(...) **不能同时出现**在构造器中,因为构造函数必须出现在第一行上,只能选择一个
```java
public class ThisDemo {
@@ -1503,7 +1492,7 @@ final 和 abstract 的关系是**互斥关系**,不能同时修饰类或者同
final 修饰静态成员变量,变量变成了常量
-**常量:有 public static final 修饰,名称字母全部大写,多个单词用下划线连接。**
+常量:有 public static final 修饰,名称字母全部大写,多个单词用下划线连接
final 修饰静态成员变量可以在哪些地方赋值:
@@ -1520,7 +1509,6 @@ public class FinalDemo {
static{
//SCHOOL_NAME = "java";//报错
SCHOOL_NAME1 = "张三1";
- //SCHOOL_NAME1 = "张三2"; // 报错,第二次赋值!
}
}
```
@@ -1575,13 +1563,13 @@ public class FinalDemo {
#### 基本介绍
-> 父类知道子类要完成某个功能,但是每个子类实现情况不一样。
+> 父类知道子类要完成某个功能,但是每个子类实现情况不一样
抽象方法:没有方法体,只有方法签名,必须用 abstract 修饰的方法就是抽象方法
抽象类:拥有抽象方法的类必须定义成抽象类,必须用 abstract 修饰,**抽象类是为了被继承**
-一个类继承抽象类,**必须重写抽象类的全部抽象方法**,否则这个类必须定义成抽象类,因为拥有抽象方法的类必须定义成抽象类
+一个类继承抽象类,**必须重写抽象类的全部抽象方法**,否则这个类必须定义成抽象类
```java
public class AbstractDemo {
@@ -1811,32 +1799,32 @@ public class InterfaceDemo {
InterfaceJDK8.inAddr();
}
}
-class Man implements InterfaceJDK8{
+class Man implements InterfaceJDK8 {
@Override
public void work() {
System.out.println("工作中。。。");
}
}
-interface InterfaceJDK8{
+interface InterfaceJDK8 {
//抽象方法!!
void work();
// a.默认方法(就是之前写的普通实例方法)
// 必须用接口的实现类的对象来调用。
- default void run(){
+ default void run() {
go();
System.out.println("开始跑步🏃");
}
// b.静态方法
// 注意:接口的静态方法必须用接口的类名本身来调用
- static void inAddr(){
+ static void inAddr() {
System.out.println("我们在武汉");
}
// c.私有方法(就是私有的实例方法): JDK 1.9才开始有的。
// 只能在本接口中被其他的默认方法或者私有方法访问。
- private void go(){
+ private void go() {
System.out.println("开始。。");
}
}
@@ -1874,7 +1862,7 @@ interface InterfaceJDK8{
#### 基本介绍
-多态的概念:同一个实体同时具有多种形式同一个类型的对象,执行同一个行为,在不同的状态下会表现出不同的行为特征。
+多态的概念:同一个实体同时具有多种形式同一个类型的对象,执行同一个行为,在不同的状态下会表现出不同的行为特征
多态的格式:
@@ -1897,11 +1885,11 @@ interface InterfaceJDK8{
* 存在方法重写
多态的优势:
-* 在多态形式下,右边对象可以实现组件化切换,业务功能也随之改变,便于扩展和维护。可以实现类与类之间的**解耦**
+* 在多态形式下,右边对象可以实现组件化切换,便于扩展和维护,也可以实现类与类之间的**解耦**
* 父类类型作为方法形式参数,传递子类对象给方法,可以传入一切子类对象进行方法的调用,更能体现出多态的**扩展性**与便利性
多态的劣势:
-* 多态形式下,不能直接调用子类特有的功能,因为编译看左边,父类中没有子类独有的功能,所以代码在编译阶段就直接报错了!
+* 多态形式下,不能直接调用子类特有的功能,因为编译看左边,父类中没有子类独有的功能,所以代码在编译阶段就直接报错了
```java
public class PolymorphicDemo {
@@ -2061,7 +2049,7 @@ static class Outter{
#### 实例内部类
-定义:无 static 修饰的内部类,属于外部类的每个对象,跟着外部类对象一起加载。
+定义:无 static 修饰的内部类,属于外部类的每个对象,跟着外部类对象一起加载
实例内部类的成分特点:实例内部类中不能定义静态成员,其他都可以定义
@@ -2192,9 +2180,8 @@ static {
```
* 静态代码块特点:
- * 必须有 static 修饰
+ * 必须有 static 修饰,只能访问静态资源
* 会与类一起优先加载,且自动触发执行一次
- * 只能访问静态资源
* 静态代码块作用:
* 可以在执行类的方法等操作之前先在静态代码块中进行静态资源的初始化
* **先执行静态代码块,在执行 main 函数里的操作**
@@ -2337,7 +2324,7 @@ Object 的 clone() 是 protected 方法,一个类不显式去重写 clone(),
* 浅拷贝 (shallowCopy):**对基本数据类型进行值传递,对引用数据类型只是复制了引用**,被复制对象属性的所有的引用仍然指向原来的对象,简而言之就是增加了一个指针指向原来对象的内存地址
- **Java 中的复制方法基本都是浅克隆**:Object.clone()、System.arraycopy()、Arrays.copyOf()
+ **Java 中的复制方法基本都是浅拷贝**:Object.clone()、System.arraycopy()、Arrays.copyOf()
* 深拷贝 (deepCopy):对基本数据类型进行值传递,对引用数据类型是一个整个独立的对象拷贝,会拷贝所有的属性并指向的动态分配的内存,简而言之就是把所有属性复制到一个新的内存,增加一个指针指向新内存。所以使用深拷贝的情况下,释放内存的时候不会出现使用浅拷贝时释放同一块内存的错误
@@ -2390,11 +2377,11 @@ Objects 类与 Object 是继承关系
Objects 的方法:
-* `public static boolean equals(Object a, Object b)`:比较两个对象是否相同。
- 底层进行非空判断,从而可以避免空指针异常,更安全,推荐使用!
-
- ```java
+* `public static boolean equals(Object a, Object b)`:比较两个对象是否相同
+
+ ```java
public static boolean equals(Object a, Object b) {
+ // 进行非空判断,从而可以避免空指针异常
return a == b || a != null && a.equals(b);
}
```
@@ -2637,7 +2624,7 @@ public static void main(String[] args) {
System.out.println(str1 == str1.intern());//true,字符串池中不存在,把堆中的引用复制一份放入串池
String str2 = new StringBuilder("ja").append("va").toString();
- System.out.println(str2 == str2.intern());//false
+ System.out.println(str2 == str2.intern());//false,字符串池中存在,直接返回已经存在的引用
}
```
@@ -2878,7 +2865,7 @@ public class MyArraysDemo {
1. 导入包:`import java.util.Random`
2. 创建对象:`Random r = new Random()`
3. 随机整数:`int num = r.nextInt(10)`
- * 解释:10 代表的是一个范围,如果括号写 10,产生的随机数就是 0 - 9,括号写 20 的随机数则是 0 - 19
+ * 解释:10 代表的是一个范围,如果括号写 10,产生的随机数就是 0 - 9,括号写 20 的随机数则是 0 - 19
* 获取 0 - 10:`int num = r.nextInt(10 + 1)`
4. 随机小数:`public double nextDouble()` 从范围 `0.0d` 至 `1.0d` (左闭右开),伪随机地生成并返回
@@ -2900,11 +2887,11 @@ System 代表当前系统
* `public static long currentTimeMillis()`:获取当前系统此刻时间毫秒值
* `static void arraycopy(Object var0, int var1, Object var2, int var3, int var4)`:数组拷贝
- 参数一:原数组
- 参数二:从原数组的哪个位置开始赋值
- 参数三:目标数组
- 参数四:从目标数组的哪个位置开始赋值
- 参数五:赋值几个
+ * 参数一:原数组
+ * 参数二:从原数组的哪个位置开始赋值
+ * 参数三:目标数组
+ * 参数四:从目标数组的哪个位置开始赋值
+ * 参数五:赋值几个
```java
public class SystemDemo {
@@ -3758,15 +3745,12 @@ public class RegexDemo {
数据存储的常用结构有:栈、队列、数组、链表和红黑树
* 队列(queue):先进先出,后进后出。(FIFO first in first out)
- 场景:各种排队、叫号系统,有很多集合可以实现队列
-
+
* 栈(stack):后进先出,先进后出 (LIFO)
- 压栈 == 入栈、弹栈 == 出栈
- 场景:手枪的弹夹
-
+
* 数组:数组是内存中的连续存储区域,分成若干等分的小区域(每个区域大小是一样的)元素存在索引
- 特点:**查询元素快**(根据索引快速计算出元素的地址,然后立即去定位)
- **增删元素慢**(创建新数组,迁移元素)
+
+ 特点:**查询元素快**(根据索引快速计算出元素的地址,然后立即去定位),**增删元素慢**(创建新数组,迁移元素)
* 链表:元素不是内存中的连续区域存储,元素是游离存储的,每个元素会记录下个元素的地址
特点:**查询元素慢,增删元素快**(针对于首尾元素,速度极快,一般是双链表)
@@ -3774,11 +3758,12 @@ public class RegexDemo {
* 树:
* 二叉树:binary tree 永远只有一个根节点,是每个结点不超过2个节点的树(tree)
+
特点:二叉排序树:小的左边,大的右边,但是可能树很高,性能变差,为了做排序和搜索会进行左旋和右旋实现平衡查找二叉树,让树的高度差不大于1
-* 红黑树(基于红黑规则实现自平衡的排序二叉树):树保证到了很矮小,但是又排好序,性能最高的树
+ * 红黑树(基于红黑规则实现自平衡的排序二叉树):树保证到了很矮小,但是又排好序,性能最高的
- 特点:**红黑树的增删查改性能都好**
+ 特点:**红黑树的增删查改性能都好**
各数据结构时间复杂度对比:
@@ -3970,8 +3955,8 @@ ArrayList 添加的元素,是有序,可重复,有索引的
* `public boolean add(E e)`:将指定的元素追加到此集合的末尾
* `public void add(int index, E element)`:将指定的元素,添加到该集合中的指定位置上
* `public E get(int index)`:返回集合中指定位置的元素
-* `public E remove(int index)`:移除列表中指定位置的元素, 返回的是被移除的元素
-* `public E set(int index, E element)`:用指定元素替换集合中指定位置的元素,返回更新前的元素值
+* `public E remove(int index)`:移除列表中指定位置的元素,返回的是被移除的元素
+* `public E set(int index, E element)`:用指定元素替换集合中指定位置的元素,返回更新前的元素值
* `int indexOf(Object o)`:返回列表中指定元素第一次出现的索引,如果不包含此元素,则返回 -1
```java
@@ -4008,7 +3993,7 @@ public class ArrayList extends AbstractList
核心方法:
-* 构造函数:以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量,即向数组中添加第一个元素时,**数组容量扩为 10**
+* 构造函数:以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量(惰性初始化),即向数组中添加第一个元素时,**数组容量扩为 10**
* 添加元素:
@@ -4059,8 +4044,8 @@ public class ArrayList extends AbstractList
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
- System.arraycopy(elementData, index, elementData, index + 1,
- size - index);
+ // 将指定索引后的数据后移
+ System.arraycopy(elementData, index, elementData, index + 1, size - index);
elementData[index] = element;
size++;
}
@@ -4091,7 +4076,7 @@ public class ArrayList extends AbstractList
* OutOfMemoryError:Requested array size exceeds VM limit(请求的数组大小超出 VM 限制)
* OutOfMemoryError: Java heap space(堆区内存不足,可以通过设置 JVM 参数 -Xmx 来调节)
-* 删除元素:需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,在旧数组上操作,该操作的时间复杂度为 O(N),可以看到 ArrayList 删除元素的代价是非常高的,
+* 删除元素:需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上,在旧数组上操作,该操作的时间复杂度为 O(N),可以看到 ArrayList 删除元素的代价是非常高的
```java
public E remove(int index) {
@@ -4212,10 +4197,6 @@ LinkedList 除了拥有 List 集合的全部功能还多了很多操作首尾元
* `public E poll()`:检索并删除此列表的头(第一个元素)
* `public void addFirst(E e)`:将指定元素插入此列表的开头
* `public void addLast(E e)`:将指定元素添加到此列表的结尾
-* `public E getFirst()`:返回此列表的第一个元素
-* `public E getLast()`:返回此列表的最后一个元素
-* `public E removeFirst()`:移除并返回此列表的第一个元素
-* `public E removeLast()`:移除并返回此列表的最后一个元素
* `public E pop()`:从此列表所表示的堆栈处弹出一个元素
* `public void push(E e)`:将元素推入此列表所表示的堆栈
* `public int indexOf(Object o)`:返回此列表中指定元素的第一次出现的索引,如果不包含返回 -1
@@ -4401,7 +4382,7 @@ Set 集合添加的元素是无序,不重复的。
每个元素的 hashcode() 的值进行响应的算法运算,计算出的值相同的存入一个数组块中,以链表的形式存储,如果链表长度超过8就采取红黑树存储,所以输出的元素是无序的。
-* 如何设置只要对象内容一样,就希望集合认为它们重复了:**重写 hashCode 和 equals 方法**
+* 如何设置只要对象内容一样,就希望集合认为重复:**重写 hashCode 和 equals 方法**
@@ -4585,7 +4566,7 @@ Map集合的体系:
LinkedHashMap(实现类)
```
-Map集合的特点:
+Map 集合的特点:
1. Map 集合的特点都是由键决定的
2. Map 集合的键是无序,不重复的,无索引的(Set)
@@ -4597,13 +4578,6 @@ HashMap:元素按照键是无序,不重复,无索引,值不做要求
LinkedHashMap:元素按照键是有序,不重复,无索引,值不做要求
-```java
-//经典代码
-Map maps = new HashMap<>();
-maps.put("手机",1);
-System.out.println(maps);
-```
-
***
@@ -4714,12 +4688,12 @@ JDK7 对比 JDK8:
* 哈希表(Hash table,也叫散列表),根据关键码值而直接访问的数据结构。通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度,这个映射函数叫做散列函数,存放记录的数组叫做散列表
-* JDK1.8 之前 HashMap 由 数组+链表 组成
+* JDK1.8 之前 HashMap 由数组+链表组成
* 数组是 HashMap 的主体
* 链表则是为了解决哈希冲突而存在的(**拉链法解决冲突**),拉链法就是头插法,两个对象调用的 hashCode 方法计算的哈希码值(键的哈希)一致导致计算的数组索引值相同
-* JDK1.8 以后 HashMap 由 **数组+链表 +红黑树**数据结构组成
+* JDK1.8 以后 HashMap 由**数组+链表 +红黑树**数据结构组成
* 解决哈希冲突时有了较大的变化
* 当链表长度**超过(大于)阈值**(或者红黑树的边界值,默认为 8)并且当前数组的**长度大于等于 64 时**,此索引位置上的所有数据改为红黑树存储
@@ -4767,7 +4741,7 @@ HashMap 继承关系如下图所示:
```java
// 默认的初始容量是16 -- 1<<4相当于1*2的4次方---1*16
- static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
+ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
```
HashMap 构造方法指定集合的初始化容量大小:
@@ -4776,9 +4750,9 @@ HashMap 继承关系如下图所示:
HashMap(int initialCapacity)// 构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap
```
- * 为什么必须是 2 的 n 次幂?
+ * 为什么必须是 2 的 n 次幂?用位运算替代取余计算,减少 rehash 的代价(移动的节点少)
- HashMap 中添加元素时,需要根据 key 的 hash 值,确定在数组中的具体位置。为了存取高效,要尽量较少碰撞,把数据分配均匀,每个链表长度大致相同,实现该方法的算法就是取模,hash%length,计算机中直接求余效率不如位移运算,所以源码中使用 hash&(length-1),实际上**hash % length == hash & (length-1)的前提是 length 是 2 的n次幂**
+ HashMap 中添加元素时,需要根据 key 的 hash 值确定在数组中的具体位置。为了减少碰撞,把数据分配均匀,每个链表长度大致相同,实现该方法就是取模 `hash%length`,计算机中直接求余效率不如位移运算, **`hash % length == hash & (length-1)` 的前提是 length 是 2 的 n 次幂**
散列平均分布:2 的 n 次方是 1 后面 n 个 0,2 的 n 次方 -1 是 n 个 1,可以**保证散列的均匀性**,减少碰撞
@@ -4804,11 +4778,6 @@ HashMap 继承关系如下图所示:
static final int MAXIMUM_CAPACITY = 1 << 30;// 0100 0000 0000 0000 0000 0000 0000 0000 = 2 ^ 30
```
- 最大容量为什么是 2 的 30 次方原因:
-
- * int 类型是 32 位整型,占 4 个字节
- * Java 的原始类型里没有无符号类型,所以首位是符号位正数为 0,负数为 1,
-
5. 当链表的值超过 8 则会转红黑树(JDK1.8 新增)
```java
@@ -4852,7 +4821,7 @@ HashMap 继承关系如下图所示:
static final int MIN_TREEIFY_CAPACITY = 64;
```
- 原因:数组比较小的情况下变为红黑树结构,反而会降低效率,红黑树需要进行左旋,右旋,变色这些操作来保持平衡。同时数组长度小于 64 时,搜索时间相对快些,所以为了提高性能和减少搜索时间,底层在阈值大于 8 并且数组长度大于等于 64 时,链表才转换为红黑树,效率也变的更高效
+ 原因:数组比较小的情况下变为红黑树结构,反而会降低效率,红黑树需要进行左旋,右旋,变色这些操作来保持平衡
8. table 用来初始化(必须是二的 n 次幂)
@@ -4861,8 +4830,6 @@ HashMap 继承关系如下图所示:
transient Node[] table;
```
- jdk8 之前数组类型是 Entry类型,之后是 Node 类型。只是换了个名字,都实现了一样的接口 Map.Entry,负责存储键值对数据的
-
9. HashMap 中**存放元素的个数**
```java
@@ -4884,7 +4851,7 @@ HashMap 继承关系如下图所示:
int threshold;
```
-12. **哈希表的加载因子(重点)**
+12. **哈希表的加载因子**
```java
final float loadFactor;
@@ -4892,9 +4859,9 @@ HashMap 继承关系如下图所示:
* 加载因子的概述
- loadFactor 加载因子,是用来衡量 HashMap 满的程度,表示 **HashMap 的疏密程度**,影响 hash 操作到同一个数组位置的概率,计算 HashMap 的实时加载因子的方法为:size/capacity,而不是占用桶的数量去除以 capacity,capacity 是桶的数量,也就是 table 的长度 length。
+ loadFactor 加载因子,是用来衡量 HashMap 满的程度,表示 HashMap 的疏密程度,影响 hash 操作到同一个数组位置的概率,计算 HashMap 的实时加载因子的方法为 **size/capacity**,而不是占用桶的数量去除以 capacity,capacity 是桶的数量,也就是 table 的长度 length
- 当 HashMap 里面容纳的元素已经达到 HashMap 数组长度的 75% 时,表示 HashMap 拥挤,需要扩容,而扩容这个过程涉及到 rehash、复制数据等操作,非常消耗性能,所以开发中尽量减少扩容的次数,可以通过创建 HashMap 集合对象时指定初始容量来尽量避免。
+ 当 HashMap 容纳的元素已经达到数组长度的 75% 时,表示 HashMap 拥挤需要扩容,而扩容这个过程涉及到 rehash、复制数据等操作,非常消耗性能,所以开发中尽量减少扩容的次数,通过创建 HashMap 集合对象时指定初始容量来避免
```java
HashMap(int initialCapacity, float loadFactor)//构造指定初始容量和加载因子的空HashMap
@@ -4904,7 +4871,7 @@ HashMap 继承关系如下图所示:
loadFactor 太大导致查找元素效率低,存放的数据拥挤,太小导致数组的利用率低,存放的数据会很分散。loadFactor 的默认值为 **0.75f 是官方给出的一个比较好的临界值**
- * threshold 计算公式:capacity(数组长度默认16) * loadFactor(默认 0.75)。当 size>=threshold 的时候,那么就要考虑对数组的 resize(扩容),这就是衡量数组是否需要扩增的一个标准, 扩容后的 HashMap 容量是之前容量的**两倍**
+ * threshold 计算公式:capacity(数组长度默认16) * loadFactor(默认 0.75)。当 size >= threshold 的时候,那么就要考虑对数组的 resize(扩容),这就是衡量数组是否需要扩增的一个标准, 扩容后的 HashMap 容量是之前容量的**两倍**
@@ -5013,8 +4980,8 @@ HashMap 继承关系如下图所示:
```java
static final int hash(Object key) {
int h;
- // 1)如果key等于null:可以看到当key等于null的时候也是有哈希值的,返回的是0.
- // 2)如果key不等于null:首先计算出key的hashCode赋值给h,然后与h无符号右移16位后的二进制进行按位异或得到最后的hash值
+ // 1)如果key等于null:可以看到当key等于null的时候也是有哈希值的,返回的是0
+ // 2)如果key不等于null:首先计算出key的hashCode赋值给h,然后与h无符号右移16位后的二进制进行按位异或
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
```
@@ -5096,8 +5063,6 @@ HashMap 继承关系如下图所示:
2. 如果是树形化遍历桶中的元素,创建相同个数的树形节点,复制内容,建立起联系,类似单向链表转换为双向链表
3. 让桶中的第一个元素即数组中的元素指向新建的红黑树的节点,以后这个桶里的元素就是红黑树而不是链表数据结构了
-
-
* tableSizeFor():创建 HashMap 指定容量时,HashMap 通过位移运算和或运算得到比指定初始化容量大的最小的 2 的 n 次幂
```java
@@ -5678,15 +5643,11 @@ TreeMap 集合指定大小规则有 2 种方式:
#### WeakMap
-WeakHashMap 是基于弱引用的
-
-内部的 Entry 继承 WeakReference,被弱引用关联的对象在**下一次垃圾回收时会被回收**,并且构造方法传入引用队列,用来在清理对象完成以后清理引用
+WeakHashMap 是基于弱引用的,内部的 Entry 继承 WeakReference,被弱引用关联的对象在**下一次垃圾回收时会被回收**,并且构造方法传入引用队列,用来在清理对象完成以后清理引用
```java
private static class Entry extends WeakReference