前端进阶算法3:从浏览器缓存淘汰策略和Vue的keep-alive学习LRU算法#9
Description

引言
这个标题已经很明显的告诉我们:前端需要了解 LRU 算法!
这也是前端技能的亮点,当面试官在问到你前端开发中遇到过哪些算法,你也可以把这部分丢过去!
本节按以下步骤切入:
- 由浏览器缓存策略引出 LRU 算法原理
- 然后走进
vue中keep-alive的应用 - 接着,透过
vue中keep-alive源码看LRU算法的实现 - 最后,来一道 leetcode 题目,我们来实现一个 LRU 算法
按这个步骤来,完全掌握 LRU 算法,点亮前端技能,下面就开始吧👇
一、LRU 缓存淘汰策略
缓存在计算机网络上随处可见,例如:当我们首次访问一个网页时,打开很慢,但当我们再次打开这个网页时,打开就很快。
这就涉及缓存在浏览器上的应用:浏览器缓存。当我们打开一个网页时,例如 https://github.com/sisterAn/JavaScript-Algorithms ,它会在发起真正的网络请求前,查询浏览器缓存,看是否有要请求的文件,如果有,浏览器将会拦截请求,返回缓存文件,并直接结束请求,不会再去服务器上下载。如果不存在,才会去服务器请求。
其实,浏览器中的缓存是一种在本地保存资源副本,它的大小是有限的,当我们请求数过多时,缓存空间会被用满,此时,继续进行网络请求就需要确定缓存中哪些数据被保留,哪些数据被移除,这就是浏览器缓存淘汰策略,最常见的淘汰策略有 FIFO(先进先出)、LFU(最少使用)、LRU(最近最少使用)。
LRU ( Least Recently Used :最近最少使用 )缓存淘汰策略,故名思义,就是根据数据的历史访问记录来进行淘汰数据,其核心思想是 如果数据最近被访问过,那么将来被访问的几率也更高 ,优先淘汰最近没有被访问到的数据。
画个图帮助我们理解:
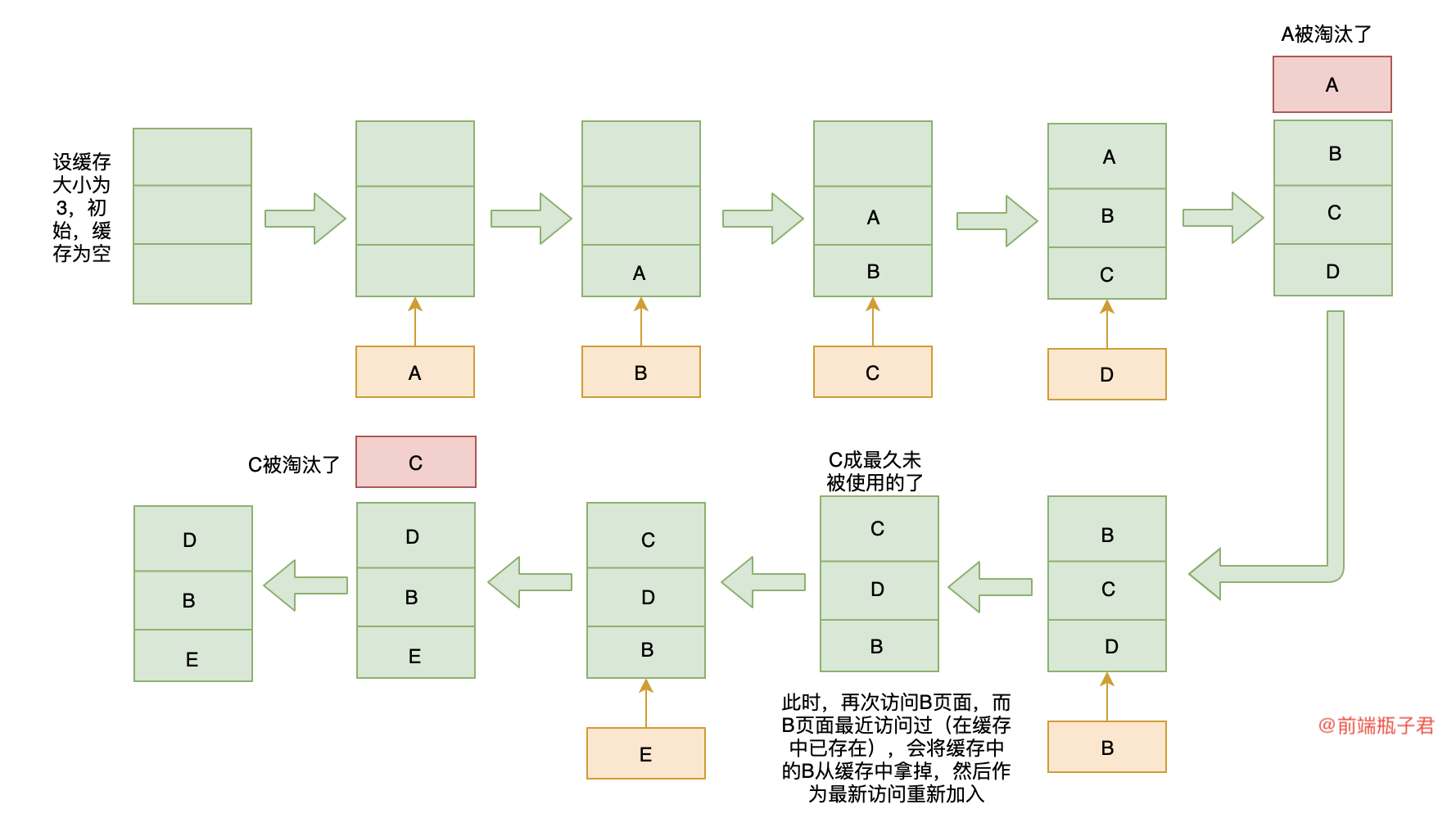
二、LRU 在 keep-alive (Vue) 上的实现
1. keep-alive
keep-alive 在 vue 中用于实现组件的缓存,当组件切换时不会对当前组件进行卸载。
<!-- 基本 --> <keep-alive> <component :is="view"></component> </keep-alive>最常用的两个属性:include 、 exculde ,用于组件进行有条件的缓存,可以用逗号分隔字符串、正则表达式或一个数组来表示。
在 2.5.0 版本中,keep-alive 新增了 max 属性,用于最多可以缓存多少组件实例,一旦这个数字达到了,在新实例被创建之前,已缓存组件中最久没有被访问的实例会被销毁掉,看,这里就应用了 LRU 算法。即在 keep-alive 中缓存达到 max,新增缓存实例会优先淘汰最近没有被访问到的实例🎉🎉🎉
下面我们透过 vue 源码看一下具体的实现👇
2. 从 vue 源码看 keep-alive 的实现
exportdefault{name: "keep-alive",// 抽象组件属性 ,它在组件实例建立父子关系的时候会被忽略,发生在 initLifecycle 的过程中abstract: true,props: {// 被缓存组件include: patternTypes,// 不被缓存组件exclude: patternTypes,// 指定缓存大小max: [String,Number]},created(){// 初始化用于存储缓存的 cache 对象this.cache=Object.create(null);// 初始化用于存储VNode key值的 keys 数组this.keys=[];},destroyed(){for(constkeyinthis.cache){// 删除所有缓存pruneCacheEntry(this.cache,key,this.keys);}},mounted(){// 监听缓存(include)/不缓存(exclude)组件的变化// 在变化时,重新调整 cache// pruneCache:遍历 cache,如果缓存的节点名称与传入的规则没有匹配上的话,就把这个节点从缓存中移除this.$watch("include",val=>{pruneCache(this,name=>matches(val,name));});this.$watch("exclude",val=>{pruneCache(this,name=>!matches(val,name));});},render(){// 获取第一个子元素的 vnodeconstslot=this.$slots.default;constvnode: VNode=getFirstComponentChild(slot);constcomponentOptions: ?VNodeComponentOptions=vnode&&vnode.componentOptions;if(componentOptions){// name 不在 inlcude 中或者在 exlude 中则直接返回 vnode,否则继续进行下一步// check patternconstname: ?string=getComponentName(componentOptions);const{ include, exclude }=this;if(// not included(include&&(!name||!matches(include,name)))||// excluded(exclude&&name&&matches(exclude,name))){returnvnode;}const{ cache, keys }=this;// 获取键,优先获取组件的 name 字段,否则是组件的 tagconstkey: ?string=vnode.key==null ? // same constructor may get registered as different local components// so cid alone is not enough (#3269)componentOptions.Ctor.cid+(componentOptions.tag ? `::${componentOptions.tag}` : "") : vnode.key;// --------------------------------------------------// 下面就是 LRU 算法了,// 如果在缓存里有则调整,// 没有则放入(长度超过 max,则淘汰最近没有访问的)// --------------------------------------------------// 如果命中缓存,则从缓存中获取 vnode 的组件实例,并且调整 key 的顺序放入 keys 数组的末尾if(cache[key]){vnode.componentInstance=cache[key].componentInstance;// make current key freshestremove(keys,key);keys.push(key);}// 如果没有命中缓存,就把 vnode 放进缓存else{cache[key]=vnode;keys.push(key);// prune oldest entry// 如果配置了 max 并且缓存的长度超过了 this.max,还要从缓存中删除第一个if(this.max&&keys.length>parseInt(this.max)){pruneCacheEntry(cache,keys[0],keys,this._vnode);}}// keepAlive标记位vnode.data.keepAlive=true;}returnvnode||(slot&&slot[0]);}};// 移除 key 缓存functionpruneCacheEntry(cache: VNodeCache,key: string,keys: Array<string>,current?: VNode){constcached=cache[key]if(cached&&(!current||cached.tag!==current.tag)){cached.componentInstance.$destroy()}cache[key]=nullremove(keys,key)}// remove 方法(shared/util.js)/** * Remove an item from an array. */exportfunctionremove(arr: Array<any>,item: any): Array<any>|void{if(arr.length){constindex=arr.indexOf(item)if(index>-1){returnarr.splice(index,1)}}}在 keep-alive 缓存超过 max 时,使用的缓存淘汰算法就是 LRU 算法,它在实现的过程中用到了 cache 对象用于保存缓存的组件实例及 key 值,keys 数组用于保存缓存组件的 key ,当 keep-alive 中渲染一个需要缓存的实例时:
- 判断缓存中是否已缓存了该实例,缓存了则直接获取,并调整
key在keys中的位置(移除keys中key,并放入keys数组的最后一位) - 如果没有缓存,则缓存该实例,若
keys的长度大于max(缓存长度超过上限),则移除keys[0]缓存
下面我们来自己实现一个 LRU 算法吧⛽️⛽️⛽️
三、leetcode:LRU 缓存机制
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和写入数据 put 。
获取数据 get(key) - 如果密钥 ( key ) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1 。
写入数据 put(key, value) - 如果密钥不存在,则写入数据。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据,从而为新数据留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
LRUCachecache=newLRUCache(2/* 缓存容量 */);cache.put(1,1);cache.put(2,2);cache.get(1);// 返回 1cache.put(3,3);// 该操作会使得密钥 2 作废cache.get(2);// 返回 -1 (未找到)cache.put(4,4);// 该操作会使得密钥 1 作废cache.get(1);// 返回 -1 (未找到)cache.get(3);// 返回 3cache.get(4);// 返回 4前面已经介绍过了 keep-alive 中LRU实现源码,现在来看这道题是不是很简单😊😊😊,可以尝试自己解答一下⛽️,然后思考一下有没有什么继续优化的!欢迎提供更多的解法
答案已提交到 #7
四、认识更多的前端道友,一起进阶前端开发
前端算法集训营第一期免费开营啦🎉🎉🎉,免费哟!
在这里,你可以和志同道合的前端朋友们(600+)一起进阶前端算法,从0到1构建完整的数据结构与算法体系。
在这里,瓶子君不仅介绍算法,还将算法与前端各个领域进行结合,包括浏览器、HTTP、V8、React、Vue源码等。
在这里,你可以每天学习一道大厂算法题(阿里、腾讯、百度、字节等等)或 leetcode,瓶子君都会在第二天解答哟!
更多福利等你解锁🔓🔓🔓!
在公众号「前端瓶子君」内回复「算法」即可加入。你的关注就是对瓶子君最大的支持😄😄😄